Decoding in Geometry: Alleviating Embedding-Space Crowding for Complex Reasoning
作者: Yixin Yang, Qingxiu Dong, Zhifang Sui
分类: cs.AI
发布日期: 2026-01-30
💡 一句话要点
提出CraEG,通过几何引导重加权缓解LLM推理中嵌入空间拥挤问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 采样解码 嵌入空间 几何推理 概率重加权
📋 核心要点
- 现有基于概率重加权或阈值的解码方法忽略了token在嵌入空间中的几何关系,导致次优的推理性能。
- CraEG通过分析嵌入空间中token的几何关系,对概率分布进行重加权,从而缓解嵌入空间拥挤现象。
- 实验表明,CraEG在多个模型和基准测试中提高了生成性能,并增强了鲁棒性和多样性。
📝 摘要(中文)
基于采样的解码是大语言模型(LLM)复杂推理的基础,解码策略深刻影响模型行为。基于温度和截断的方法通过全局概率重加权或阈值处理来调整下一个token的分布,以平衡质量-多样性。然而,它们仅作用于token概率,忽略了嵌入空间中token之间的细粒度关系。我们发现了一种新的现象,即嵌入空间拥挤,其中下一个token的分布将其概率质量集中在嵌入空间中几何上接近的token上。我们量化了多个粒度的拥挤,并发现其与数学问题求解中的推理成功存在统计关联。受此发现的启发,我们提出CraEG,一种即插即用的采样方法,通过几何引导的重加权来缓解拥挤。CraEG是免训练的、单次通过的,并且与标准采样策略兼容。在多个模型和基准测试上的实验表明,生成性能得到提高,在鲁棒性和多样性指标方面有所提升。
🔬 方法详解
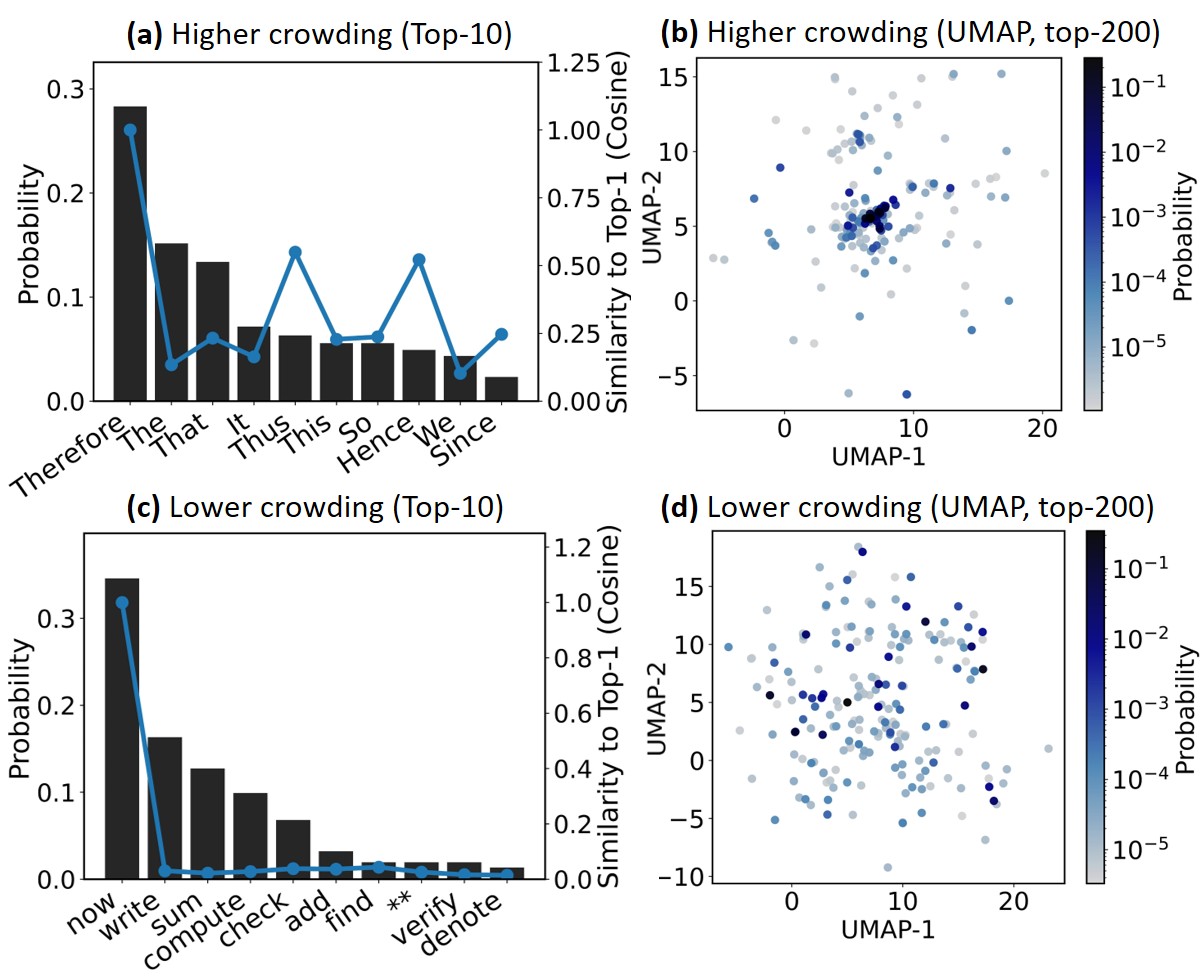
问题定义:大语言模型在进行复杂推理时,依赖于采样解码策略。现有的解码方法,如基于温度或截断的采样,主要关注token的概率分布,而忽略了token在嵌入空间中的几何关系。这种忽略导致了“嵌入空间拥挤”现象,即模型倾向于选择在嵌入空间中彼此接近的token,限制了生成的多样性和推理的准确性。现有方法未能有效利用token间的几何信息,导致推理性能受限。
核心思路:CraEG的核心思路是通过分析token在嵌入空间中的几何关系,来指导token概率的重加权。具体来说,CraEG旨在缓解嵌入空间拥挤现象,使得模型在采样时能够更均匀地选择token,从而提高生成的多样性和推理的准确性。通过几何引导的重加权,CraEG鼓励模型探索更广阔的token空间,避免陷入局部最优。
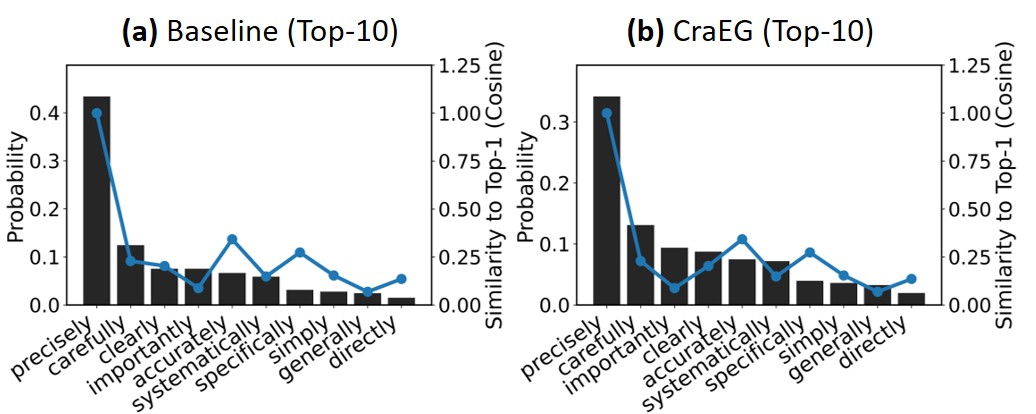
技术框架:CraEG是一个即插即用的采样方法,可以与现有的采样策略(如温度采样、top-k采样等)结合使用。其主要流程如下:1) 获取模型预测的下一个token的概率分布;2) 计算token在嵌入空间中的几何关系(例如,计算token之间的距离);3) 基于几何关系,对token的概率进行重加权,缓解拥挤现象;4) 使用重加权后的概率分布进行采样,生成下一个token。CraEG是单次通过的,不需要额外的训练。
关键创新:CraEG的关键创新在于它将token的几何信息引入到采样解码过程中。与现有方法仅关注token概率不同,CraEG通过分析token在嵌入空间中的位置关系,来指导token的选择。这种几何引导的重加权能够有效缓解嵌入空间拥挤现象,提高生成的多样性和推理的准确性。CraEG的即插即用特性使其易于集成到现有的LLM系统中。
关键设计:CraEG的关键设计在于如何有效地量化和利用token的几何关系。论文中可能使用了某种距离度量(例如,余弦相似度)来衡量token在嵌入空间中的接近程度。重加权的具体方式可能涉及到对距离相近的token进行惩罚,或者对距离较远的token进行奖励。具体的参数设置(例如,重加权的强度)可能需要根据具体的模型和任务进行调整。损失函数方面,由于CraEG是免训练的,因此没有涉及到损失函数的设计。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CraEG在多个模型和基准测试中提高了生成性能。具体来说,CraEG在数学问题求解任务中取得了显著的提升,表明其能够有效提高复杂推理的准确性。此外,CraEG还提高了生成的多样性和鲁棒性,表明其能够生成更丰富和可靠的文本。论文中可能提供了具体的性能数据,例如准确率、BLEU分数、多样性指标等,以及与现有基线的对比结果。
🎯 应用场景
CraEG可应用于各种需要大语言模型进行复杂推理的场景,例如数学问题求解、代码生成、文本摘要、对话生成等。通过提高生成的多样性和准确性,CraEG可以提升这些应用的用户体验和性能。此外,CraEG的即插即用特性使其易于集成到现有的LLM系统中,降低了应用门槛。未来,CraEG可以进一步扩展到其他模态,例如图像和音频,以提高多模态推理的性能。
📄 摘要(原文)
Sampling-based decoding underlies complex reasoning in large language models (LLMs), where decoding strategies critically shape model behavior. Temperature- and truncation-based methods reshape the next-token distribution through global probability reweighting or thresholding to balance the quality-diversity tradeoff. However, they operate solely on token probabilities, ignoring fine-grained relationships among tokens in the embedding space. We uncover a novel phenomenon, embedding-space crowding, where the next-token distribution concentrates its probability mass on geometrically close tokens in the embedding space. We quantify crowding at multiple granularities and find a statistical association with reasoning success in mathematical problem solving. Motivated by this finding, we propose CraEG, a plug-and-play sampling method that mitigates crowding through geometry-guided reweighting. CraEG is training-free, single-pass, and compatible with standard sampling strategies. Experiments on multiple models and benchmarks demonstrate improved generation performance, with gains in robustness and diversity metrics.