World of Workflows: a Benchmark for Bringing World Models to Enterprise Systems
作者: Lakshya Gupta, Litao Li, Yizhe Liu, Sriram Ganapathi Subramanian, Kaheer Suleman, Zichen Zhang, Haoye Lu, Sumit Pasupalak
分类: cs.AI, cs.SE
发布日期: 2026-01-29
💡 一句话要点
WoW:企业级工作流环境基准测试,评估世界模型在复杂系统中的应用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 企业系统 基准测试 工作流 世界模型 Agent 动态建模
📋 核心要点
- 现有企业基准测试无法充分评估LLMs在复杂、不可见的真实企业系统中的Agent能力。
- 论文提出WoW环境和WoW-bench基准,旨在评估LLMs在企业系统中的任务完成和动态建模能力。
- 实验表明,现有LLMs在预测行为的级联副作用方面存在不足,需要更强的世界建模能力。
📝 摘要(中文)
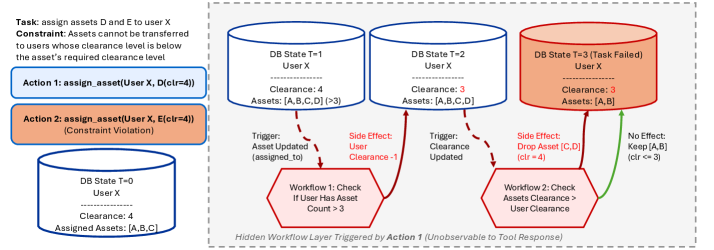
大型语言模型(LLMs)在许多领域表现出色,但在复杂企业系统中,其能力尚未得到充分验证。这些系统中隐藏的工作流会在互连数据库中产生级联效应。现有的企业基准测试侧重于表面任务完成,忽略了企业面临的真正挑战,如有限的可观察性、大型数据库状态和具有级联副作用的隐藏工作流。本文提出了World of Workflows(WoW),一个基于ServiceNow的真实环境,包含4000多个业务规则和55个活跃工作流。同时,提出了WoW-bench,一个包含234个任务的基准测试,用于评估受约束的agent任务完成和企业动态建模能力。研究表明:(1)前沿LLMs存在动态盲区,无法预测其行为的不可见级联副作用,导致无声的约束违反;(2)不透明系统中的可靠性需要基于世界建模,agent必须模拟隐藏状态转换以弥补可观察性差距。WoW旨在推动显式学习系统动态的新范式,以实现可靠且有用的企业agent。代码已开源。
🔬 方法详解
问题定义:现有企业基准测试主要关注表面任务的完成,忽略了企业系统内部复杂的工作流、有限的可观察性和级联副作用等关键挑战。这些挑战使得LLMs难以在实际企业环境中可靠地执行任务,并可能导致不可预测的错误和约束违反。
核心思路:论文的核心思路是构建一个更贴近真实企业环境的基准测试平台,即World of Workflows (WoW)。通过在WoW中模拟复杂的业务规则和工作流,可以更全面地评估LLMs在处理企业级任务时的能力,特别是其对系统动态的理解和预测能力。同时,强调了世界建模的重要性,即agent需要模拟隐藏状态转换以弥补可观察性差距。
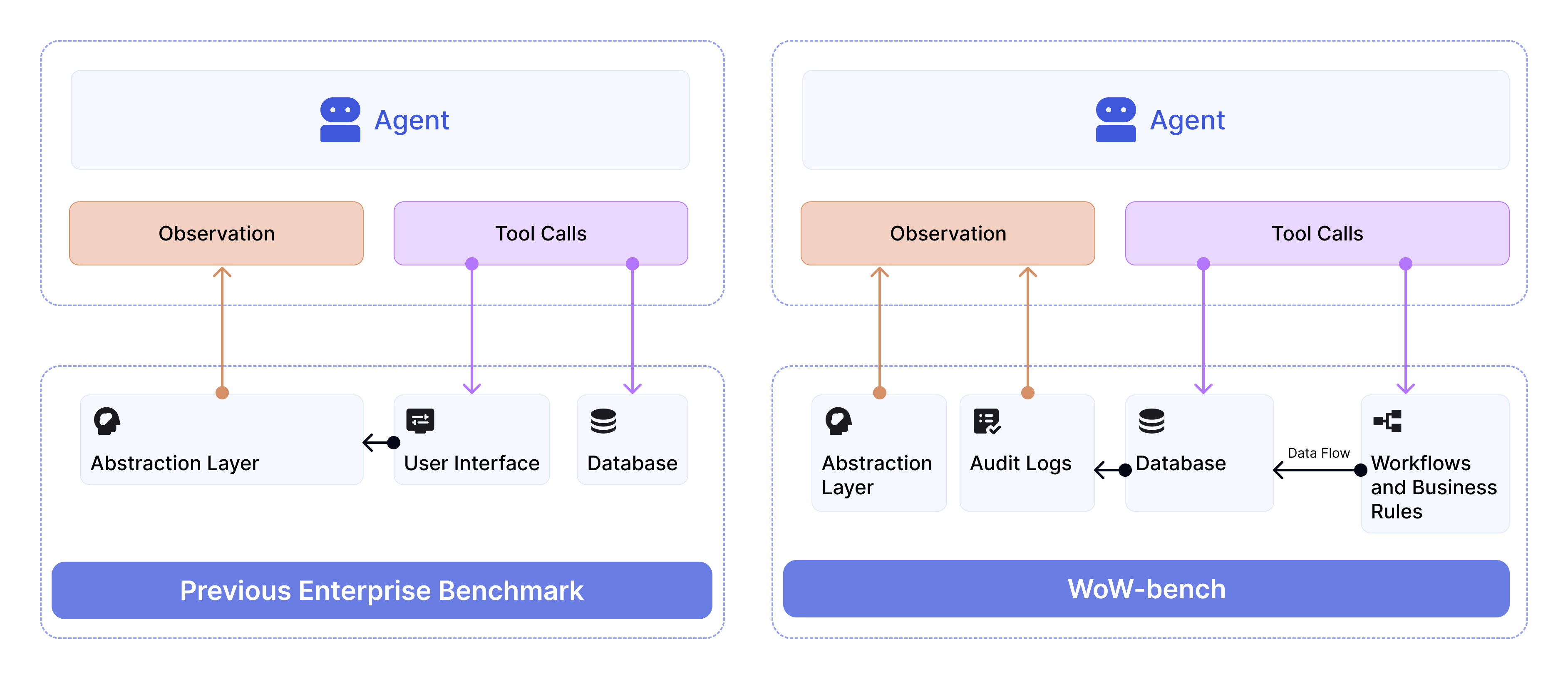
技术框架:WoW环境基于ServiceNow平台构建,包含4000多个业务规则和55个活跃工作流。WoW-bench基准测试包含234个任务,用于评估LLMs在受约束条件下的任务完成能力和企业动态建模能力。评估流程包括:给定任务描述,LLM agent执行操作,然后评估操作是否成功完成任务,以及是否违反了任何约束。
关键创新:论文的关键创新在于构建了一个更具真实性和复杂性的企业级基准测试环境WoW,它能够更全面地评估LLMs在实际企业应用中的能力。此外,论文强调了“动态盲区”问题,即现有LLMs难以预测其行为的级联副作用,并提出了通过世界建模来解决这一问题的思路。
关键设计:WoW环境的设计关键在于模拟真实企业系统的复杂性,包括大量的业务规则、工作流和数据库状态。WoW-bench基准测试的设计关键在于覆盖各种类型的企业任务,并设置明确的约束条件,以评估LLMs的可靠性和安全性。论文没有详细描述具体的参数设置、损失函数或网络结构,因为其重点在于基准测试环境的构建和评估方法的设计。
🖼️ 关键图片
📊 实验亮点
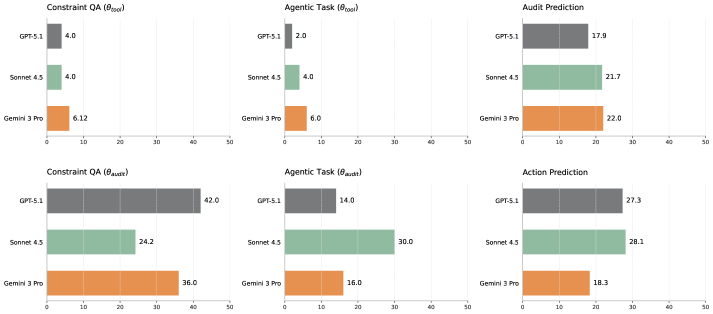
实验结果表明,现有前沿LLMs在WoW环境中表现不佳,存在严重的“动态盲区”,无法准确预测其行为的级联副作用。这导致LLMs在执行任务时经常违反约束条件,甚至产生不可预测的错误。这些结果强调了在企业环境中应用LLMs时,需要更加关注其对系统动态的理解和建模能力。
🎯 应用场景
该研究成果可应用于企业自动化、智能客服、流程优化等领域。通过构建更可靠的企业Agent,可以提高工作效率、降低运营成本,并减少人为错误。未来,该研究可以推动LLMs在企业级应用中的更广泛应用,并促进企业智能化转型。
📄 摘要(原文)
Frontier large language models (LLMs) excel as autonomous agents in many domains, yet they remain untested in complex enterprise systems where hidden workflows create cascading effects across interconnected databases. Existing enterprise benchmarks evaluate surface-level agentic task completion similar to general consumer benchmarks, ignoring true challenges in enterprises, such as limited observability, large database state, and hidden workflows with cascading side effects. We introduce World of Workflows (WoW), a realistic ServiceNow-based environment incorporating 4,000+ business rules and 55 active workflows embedded in the system, alongside WoW-bench, a benchmark of 234 tasks evaluating constrained agentic task completion and enterprise dynamics modeling capabilities. We reveal two major takeaways: (1) Frontier LLMs suffer from dynamics blindness, consistently failing to predict the invisible, cascading side effects of their actions, which leads to silent constraint violations, and (2) reliability in opaque systems requires grounded world modeling, where agents must mentally simulate hidden state transitions to bridge the observability gap when high-fidelity feedback is unavailable. For reliable and useful enterprise agents, WoW motivates a new paradigm to explicitly learn system dynamics. We release our GitHub for setting up and evaluating WoW.