SIA: Symbolic Interpretability for Anticipatory Deep Reinforcement Learning in Network Control
作者: MohammadErfan Jabbari, Abhishek Duttagupta, Claudio Fiandrino, Leonardo Bonati, Salvatore D'Oro, Michele Polese, Marco Fiore, Tommaso Melodia
分类: cs.NI, cs.AI
发布日期: 2026-01-29
备注: 10 pages, 12 figures, accepted at IEEE INFOCOM 2026
💡 一句话要点
SIA:用于网络控制中预测性深度强化学习的符号可解释性框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 可解释性AI 网络控制 知识图谱 符号AI 预测性控制 移动网络
📋 核心要点
- 现有DRL智能体在网络控制中缺乏对未来KPI预测的利用,导致控制策略的反应性。
- SIA通过融合符号AI和知识图,为预测增强的DRL智能体提供实时可解释性,揭示决策依据。
- 实验表明,SIA能发现预测集成和奖励设计中的问题,并指导智能体改进,提升网络性能。
📝 摘要(中文)
深度强化学习(DRL)有望为未来移动网络提供自适应控制,但传统智能体仍然是被动的:它们根据过去和当前的测量结果采取行动,无法利用带宽等外生KPI的短期预测。利用预测增强智能体可以克服这种时间短视,但由于预测感知智能体充当黑盒,因此在网络中的应用很少;运营商无法判断预测是否指导决策或证明增加的复杂性是合理的。我们提出了SIA,这是第一个实时揭示预测增强DRL智能体如何运作的解释器。SIA将符号AI抽象与每个KPI的知识图融合以产生解释,并包括一个新的影响评分指标。SIA实现了亚毫秒级的速度,比现有的XAI方法快200倍以上。我们在三个不同的网络用例中评估了SIA,揭示了隐藏的问题,包括预测集成中的时间错位和触发反生产策略的奖励设计偏差。这些见解能够进行有针对性的修复:重新设计的智能体在视频流中实现了平均比特率提高9%,SIA的在线行动改进模块在不重新训练的情况下将RAN切片奖励提高了25%。通过使预测性DRL透明且可调,SIA降低了下一代移动网络中主动控制的门槛。
🔬 方法详解
问题定义:现有基于DRL的网络控制方法主要依赖于历史和当前的网络状态信息进行决策,无法有效利用未来网络状态的预测信息。直接将预测信息输入DRL智能体,虽然可能提升性能,但由于缺乏可解释性,运营商难以信任和部署,并且难以发现潜在的问题,例如预测偏差或奖励函数设计不合理等。
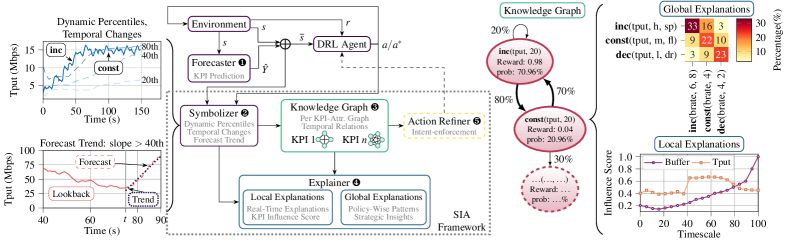
核心思路:SIA的核心思路是通过符号AI抽象和知识图谱,将DRL智能体的决策过程转化为人类可理解的符号表示,从而提供可解释性。具体来说,SIA将网络KPI(如带宽、延迟等)的预测值和DRL智能体的动作映射到符号化的状态和动作,并构建知识图谱来表示它们之间的关系。通过分析知识图谱,可以理解DRL智能体做出特定决策的原因。
技术框架:SIA框架主要包含以下几个模块:1) KPI预测模块:负责对网络KPI进行短期预测。2) 符号化模块:将KPI预测值和DRL智能体的动作进行符号化,例如将带宽预测值分为“高”、“中”、“低”三个等级。3) 知识图谱构建模块:根据符号化的状态和动作,构建知识图谱,表示它们之间的关系。4) 解释模块:分析知识图谱,生成人类可理解的解释,例如“当预测带宽为高时,DRL智能体选择动作A”。5) 影响评分模块:计算每个KPI对DRL智能体决策的影响程度,帮助识别关键KPI。6) 行动优化模块:基于SIA的解释,对DRL智能体的动作进行优化,提升性能。
关键创新:SIA的关键创新在于将符号AI抽象和知识图谱应用于DRL智能体的可解释性分析。与传统的XAI方法相比,SIA能够提供更具语义信息的解释,并且速度更快。此外,SIA还提出了一个新的影响评分指标,用于衡量每个KPI对DRL智能体决策的影响程度。
关键设计:SIA的关键设计包括:1) 符号化方法:采用基于分位数的方法对KPI预测值进行符号化,以适应不同的KPI分布。2) 知识图谱的构建:使用RDF三元组来表示符号化的状态、动作和它们之间的关系。3) 影响评分的计算:基于知识图谱中的路径,计算每个KPI对DRL智能体决策的影响程度。4) 行动优化:使用SIA的解释来指导DRL智能体的动作选择,例如避免选择导致负面结果的动作。
🖼️ 关键图片


📊 实验亮点
在三个不同的网络用例中,SIA成功揭示了预测集成中的时间错位和奖励设计偏差等问题。通过对DRL智能体进行针对性修复,视频流的平均比特率提高了9%,RAN切片奖励提高了25%。SIA的运行速度极快,比现有XAI方法快200倍以上,使其能够进行实时在线分析和优化。
🎯 应用场景
SIA可应用于各种网络控制场景,例如无线资源管理、流量工程、网络切片等。通过提供可解释性,SIA可以帮助运营商更好地理解和信任DRL智能体的决策,从而降低部署门槛。此外,SIA还可以帮助发现网络中的潜在问题,并指导智能体进行优化,提升网络性能。SIA有望推动DRL在下一代移动网络中的广泛应用。
📄 摘要(原文)
Deep reinforcement learning (DRL) promises adaptive control for future mobile networks but conventional agents remain reactive: they act on past and current measurements and cannot leverage short-term forecasts of exogenous KPIs such as bandwidth. Augmenting agents with predictions can overcome this temporal myopia, yet uptake in networking is scarce because forecast-aware agents act as closed-boxes; operators cannot tell whether predictions guide decisions or justify the added complexity. We propose SIA, the first interpreter that exposes in real time how forecast-augmented DRL agents operate. SIA fuses Symbolic AI abstractions with per-KPI Knowledge Graphs to produce explanations, and includes a new Influence Score metric. SIA achieves sub-millisecond speed, over 200x faster than existing XAI methods. We evaluate SIA on three diverse networking use cases, uncovering hidden issues, including temporal misalignment in forecast integration and reward-design biases that trigger counter-productive policies. These insights enable targeted fixes: a redesigned agent achieves a 9% higher average bitrate in video streaming, and SIA's online Action-Refinement module improves RAN-slicing reward by 25% without retraining. By making anticipatory DRL transparent and tunable, SIA lowers the barrier to proactive control in next-generation mobile networks.