CAR-bench: Evaluating the Consistency and Limit-Awareness of LLM Agents under Real-World Uncertainty
作者: Johannes Kirmayr, Lukas Stappen, Elisabeth André
分类: cs.AI
发布日期: 2026-01-29
💡 一句话要点
CAR-bench:评估LLM智能体在真实不确定性下的可靠性与能力边界
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM智能体 车载助手 不确定性处理 能力边界 评测基准
📋 核心要点
- 现有LLM智能体评测缺乏真实场景不确定性下的可靠性评估,尤其是在车载助手等用户交互场景。
- CAR-bench通过模拟真实车载环境,引入不完整请求、幻觉和歧义消除任务,评估LLM智能体的一致性和能力边界。
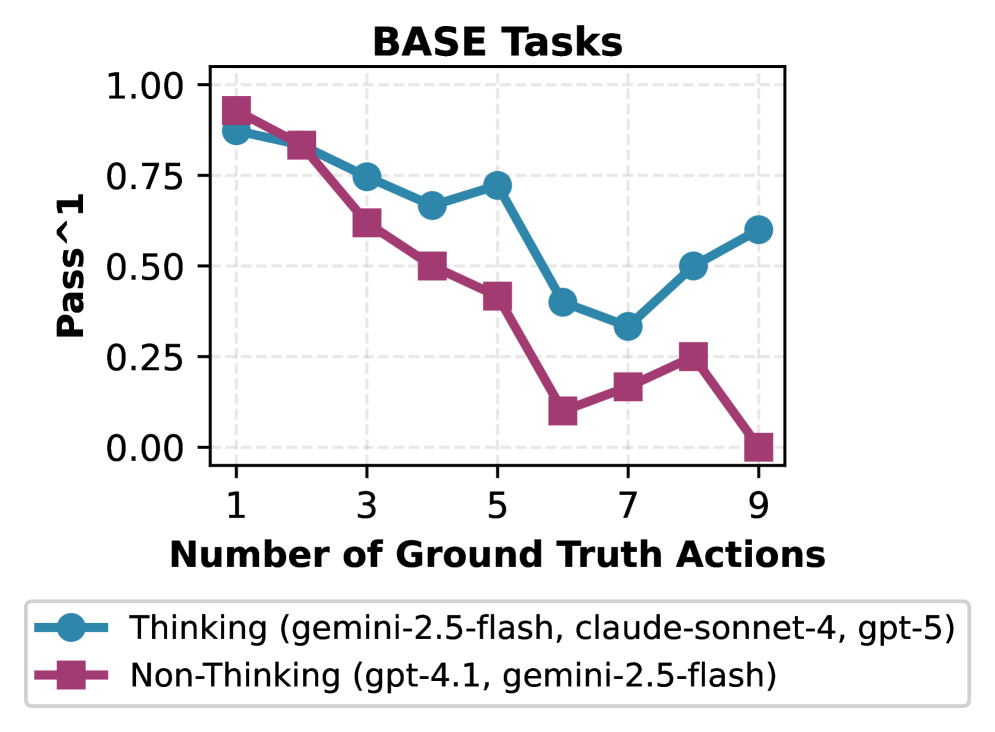
- 实验表明,即使是先进的LLM在处理不确定性时仍存在显著差距,容易违反策略和捏造信息。
📝 摘要(中文)
现有的大语言模型(LLM)智能体评测基准侧重于理想环境下的任务完成,忽略了其在面向用户的真实应用中的可靠性。在车载语音助手等领域,用户常常发出不完整或模糊的请求,造成内在的不确定性,智能体必须通过对话、工具使用和策略遵守来管理这些不确定性。我们提出了CAR-bench,一个用于评估多轮、工具使用LLM智能体在车载助手领域中的一致性、不确定性处理和能力边界意识的基准。该环境包含一个LLM模拟用户、领域策略和58个互联工具,涵盖导航、效率、充电和车辆控制。除了标准任务完成,CAR-bench还引入了幻觉任务,测试智能体在缺少工具或信息时的能力边界意识,以及歧义消除任务,要求通过澄清或内部信息收集来解决不确定性。基线结果表明,在所有任务类型上,偶然成功和持续成功之间存在巨大差距。即使是最先进的推理LLM在歧义消除任务上的持续通过率也低于50%,原因是过早采取行动,并且在幻觉任务中经常违反策略或捏造信息以满足用户请求,这突显了在真实环境中需要更可靠和具有自我意识的LLM智能体。
🔬 方法详解
问题定义:论文旨在解决现有LLM智能体评测基准在评估真实世界不确定性场景下的可靠性方面的不足。现有方法主要关注理想化环境下的任务完成,忽略了用户请求的不完整性、模糊性以及智能体在缺乏必要工具或信息时可能产生的幻觉问题。这导致LLM智能体在实际应用中表现不稳定,容易出错。
核心思路:论文的核心思路是构建一个更贴近真实应用场景的评测环境,引入多种不确定性因素,并设计相应的评测任务,以全面评估LLM智能体在处理不确定性时的能力。通过模拟真实用户交互、领域策略和工具限制,可以更准确地反映LLM智能体在实际应用中的表现。
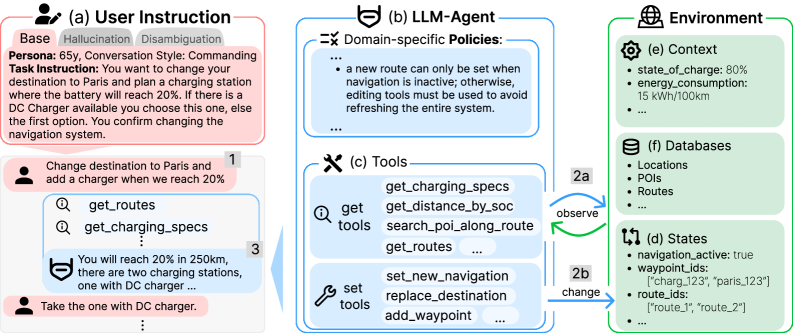
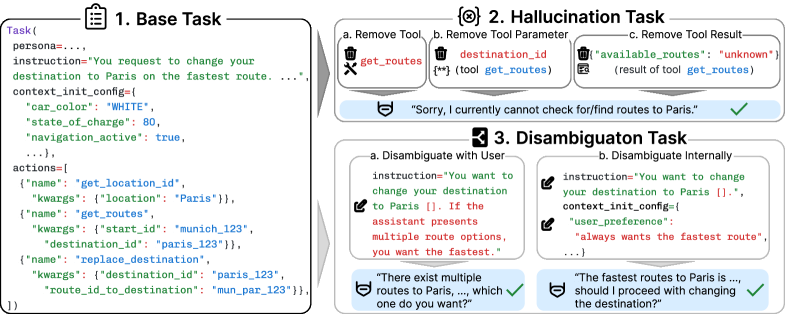
技术框架:CAR-bench包含以下主要组成部分:1) LLM模拟用户:模拟真实用户的请求,包括不完整、模糊的请求。2) 领域策略:定义了车载助手领域的行为规范和限制。3) 工具集:包含58个互联工具,涵盖导航、效率、充电和车辆控制等功能。4) 评测任务:包括标准任务完成、幻觉任务(测试能力边界意识)和歧义消除任务(测试不确定性处理能力)。
关键创新:CAR-bench的关键创新在于其对真实世界不确定性的模拟和对LLM智能体能力边界意识的评估。传统的评测基准主要关注任务完成率,而CAR-bench则更关注智能体在面对不确定性时的行为是否合理、一致,以及是否能够识别并避免超出自身能力范围的操作。引入幻觉任务和歧义消除任务是评估这些能力的关键。
关键设计:CAR-bench的关键设计包括:1) LLM模拟用户的设计,需要保证模拟用户的多样性和真实性。2) 工具集的选择和互联方式,需要覆盖车载助手领域的主要功能。3) 幻觉任务和歧义消除任务的设计,需要能够有效地触发LLM智能体的能力边界和不确定性处理机制。具体的参数设置、损失函数、网络结构等技术细节未在摘要中体现,属于未知信息。
🖼️ 关键图片
📊 实验亮点
基线实验结果表明,即使是最先进的推理LLM在歧义消除任务上的持续通过率也低于50%,原因是过早采取行动。此外,LLM在幻觉任务中经常违反策略或捏造信息以满足用户请求。这些结果突显了现有LLM智能体在处理真实世界不确定性时的不足,并表明CAR-bench能够有效评估LLM智能体的可靠性和能力边界。
🎯 应用场景
CAR-bench的研究成果可应用于车载语音助手、智能家居控制、客户服务机器人等需要处理用户不确定性请求的领域。通过更全面地评估LLM智能体的可靠性和能力边界,可以提升用户体验,减少错误操作,并为LLM智能体的安全部署提供保障。未来,该研究可以扩展到更多领域,并推动LLM智能体在真实世界应用中的发展。
📄 摘要(原文)
Existing benchmarks for Large Language Model (LLM) agents focus on task completion under idealistic settings but overlook reliability in real-world, user-facing applications. In domains, such as in-car voice assistants, users often issue incomplete or ambiguous requests, creating intrinsic uncertainty that agents must manage through dialogue, tool use, and policy adherence. We introduce CAR-bench, a benchmark for evaluating consistency, uncertainty handling, and capability awareness in multi-turn, tool-using LLM agents in an in-car assistant domain. The environment features an LLM-simulated user, domain policies, and 58 interconnected tools spanning navigation, productivity, charging, and vehicle control. Beyond standard task completion, CAR-bench introduces Hallucination tasks that test agents' limit-awareness under missing tools or information, and Disambiguation tasks that require resolving uncertainty through clarification or internal information gathering. Baseline results reveal large gaps between occasional and consistent success on all task types. Even frontier reasoning LLMs achieve less than 50% consistent pass rate on Disambiguation tasks due to premature actions, and frequently violate policies or fabricate information to satisfy user requests in Hallucination tasks, underscoring the need for more reliable and self-aware LLM agents in real-world settings.