Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
作者: Shuangshuang Ying, Zheyu Wang, Yunjian Peng, Jin Chen, Yuhao Wu, Hongbin Lin, Dingyu He, Siyi Liu, Gengchen Yu, YinZhu Piao, Yuchen Wu, Xin Gui, Zhongyuan Peng, Xin Li, Xeron Du, Libo Qin, YiXin Cao, Ge Zhang
分类: cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出DeR2基准,解耦检索与推理能力,评估大语言模型在科学信息上的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大语言模型 科学推理 基准测试 解耦 知识推理 深度搜索
📋 核心要点
- 现有RAG评估难以区分检索、推理和工具链的影响,且易受参数记忆和网络波动干扰。
- DeR2通过解耦证据访问和推理,提供四种模式,量化检索和推理损失,实现细粒度错误分析。
- 实验表明,现有模型在DeR2上表现差异大,存在模式切换脆弱性和概念误用等问题,有提升空间。
📝 摘要(中文)
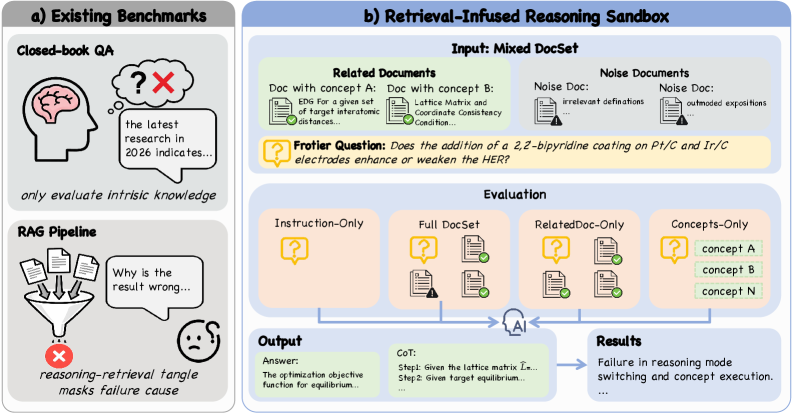
尽管大型语言模型在现有基准测试中表现出色,但它们是否能对真正新颖的科学信息进行推理仍不清楚。大多数评估对端到端RAG流程进行评分,其中推理与检索和工具链选择相混淆,并且信号进一步受到参数记忆和开放网络波动的影响。我们引入DeR2,这是一个受控的深度研究沙箱,它隔离了基于文档的推理,同时保留了深度搜索的核心难点:多步骤综合、去噪和基于证据的结论制定。DeR2通过四种模式(仅指令、概念(无文档的黄金概念)、仅相关(仅相关文档)和全集(相关文档加上主题相关的干扰项))将证据访问与推理分离,从而产生可解释的模式差距,这些差距可操作化检索损失与推理损失,并实现细粒度的错误归因。为了防止参数泄漏,我们应用了两阶段验证,要求在没有证据的情况下参数失败,同时确保oracle概念的可解性。为了确保可重复性,每个实例都提供了一个冻结的文档库(来自2023-2025年的理论论文),其中包含专家注释的概念和经过验证的理由。对各种最先进的基础模型进行的实验表明,存在很大的差异和显著的提升空间:一些模型表现出模式切换脆弱性,在全集上的表现比仅指令更差,而另一些模型则表现出结构性概念误用,正确命名概念但未能将其作为程序执行。
🔬 方法详解
问题定义:现有的大语言模型(LLM)评估方法,特别是检索增强生成(RAG)流程的评估,难以区分检索、推理和工具链选择的影响。模型可能通过参数记忆或从开放网络获取信息来作弊,导致评估结果不准确。此外,现有方法难以对检索和推理过程中的错误进行细粒度分析。
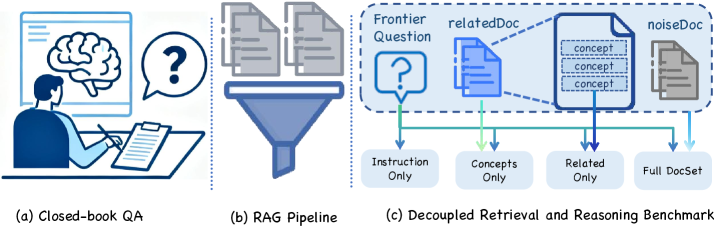
核心思路:DeR2的核心思路是创建一个受控的深度研究沙箱,通过解耦证据访问和推理,隔离文档基础上的推理过程。通过提供不同级别的证据(仅指令、概念、仅相关文档、全集),可以量化检索和推理过程中的损失,并进行细粒度的错误归因。
技术框架:DeR2包含以下主要模块: 1. 文档库:包含来自2023-2025年理论论文的冻结文档库,确保可重复性。 2. 问题集:包含需要多步骤推理、去噪和基于证据结论的问题。 3. 证据模式:提供四种证据模式:Instruction-only, Concepts, Related-only, Full-set。 4. 两阶段验证:防止参数泄漏,要求模型在没有证据的情况下失败,同时确保oracle概念的可解性。 5. 专家标注:提供专家标注的概念和验证的理由。
关键创新:DeR2的关键创新在于解耦了检索和推理过程,通过提供不同级别的证据,可以量化检索和推理的损失,并进行细粒度的错误归因。此外,DeR2采用两阶段验证来防止参数泄漏,并提供专家标注的概念和理由,确保评估的准确性和可信度。
关键设计:DeR2的关键设计包括: 1. 证据模式:四种证据模式的设计允许量化检索和推理的贡献。 2. 两阶段验证:防止模型通过参数记忆作弊。 3. 冻结文档库:确保评估的可重复性。 4. 专家标注:提供高质量的标注数据,提高评估的准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有模型在DeR2上表现出显著差异,一些模型在全集上的表现甚至不如仅指令模式,表明存在模式切换脆弱性。此外,一些模型存在结构性概念误用,即正确命名概念但未能将其作为程序执行。这些结果表明,现有模型在科学推理方面仍有很大的提升空间。
🎯 应用场景
DeR2可用于评估和改进大型语言模型在科学研究领域的推理能力,例如文献综述、科学发现和知识推理。该基准可以帮助研究人员开发更可靠、更可信的RAG系统,并促进人工智能在科学领域的应用。
📄 摘要(原文)
Despite strong performance on existing benchmarks, it remains unclear whether large language models can reason over genuinely novel scientific information. Most evaluations score end-to-end RAG pipelines, where reasoning is confounded with retrieval and toolchain choices, and the signal is further contaminated by parametric memorization and open-web volatility. We introduce DeR2, a controlled deep-research sandbox that isolates document-grounded reasoning while preserving core difficulties of deep search: multi-step synthesis, denoising, and evidence-based conclusion making. DeR2 decouples evidence access from reasoning via four regimes--Instruction-only, Concepts (gold concepts without documents), Related-only (only relevant documents), and Full-set (relevant documents plus topically related distractors)--yielding interpretable regime gaps that operationalize retrieval loss vs. reasoning loss and enable fine-grained error attribution. To prevent parametric leakage, we apply a two-phase validation that requires parametric failure without evidence while ensuring oracle-concept solvability. To ensure reproducibility, each instance provides a frozen document library (drawn from 2023-2025 theoretical papers) with expert-annotated concepts and validated rationales. Experiments across a diverse set of state-of-the-art foundation models reveal substantial variation and significant headroom: some models exhibit mode-switch fragility, performing worse with the Full-set than with Instruction-only, while others show structural concept misuse, correctly naming concepts but failing to execute them as procedures.