AgenticSimLaw: A Juvenile Courtroom Multi-Agent Debate Simulation for Explainable High-Stakes Tabular Decision Making
作者: Jon Chun, Kathrine Elkins, Yong Suk Lee
分类: cs.AI
发布日期: 2026-01-29
备注: 18 pages, 5 figures
💡 一句话要点
AgenticSimLaw:用于可解释高风险表格决策的青少年法庭多智能体辩论模拟
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 可解释性 高风险决策 表格数据 法庭辩论
📋 核心要点
- 现有高风险表格决策方法缺乏透明性和可控性,难以审计和解释决策过程。
- AgenticSimLaw构建法庭辩论式多智能体框架,明确角色、协议和策略,实现可审计的决策过程。
- 实验表明,该框架在青少年累犯预测任务上表现更稳定、泛化性更强,并提供细粒度控制和可解释性。
📝 摘要(中文)
我们提出了AgenticSimLaw,一个角色结构化的多智能体辩论框架,为高风险表格决策任务提供透明且可控的测试时推理。与黑盒方法不同,我们的法庭式编排明确定义了智能体角色(检察官、辩护律师、法官)、交互协议(7轮结构化辩论)和私有推理策略,从而创建一个完全可审计的决策过程。我们使用NLSY97数据集对青少年累犯预测任务进行了基准测试,并将其与传统的思维链(CoT)提示在近90种独特的模型和策略组合中进行了比较。结果表明,结构化的多智能体辩论比单智能体推理提供更稳定和更具泛化性的性能,并且准确率和F1分数指标之间具有更强的相关性。除了性能改进之外,AgenticSimLaw还提供对推理步骤的细粒度控制,生成完整的交互记录以提高可解释性,并能够系统地分析智能体行为。虽然我们在刑事司法领域实例化了这个框架,以强调在伦理复杂性下的推理,但该方法可以推广到任何需要透明度和人工监督的审议性、高风险决策任务。这项工作解决了基于LLM的多智能体系统的关键挑战:通过结构化角色进行组织,通过记录的交互进行可观察性,以及通过针对敏感领域的明确非部署约束来实现责任。数据、结果和代码将在github.com上以MIT许可证提供。
🔬 方法详解
问题定义:论文旨在解决高风险表格数据决策中黑盒模型缺乏透明性和可解释性的问题。现有方法,如直接使用机器学习模型或简单的思维链(CoT)提示,难以追踪推理过程,无法满足需要人工监督和审计的场景需求。
核心思路:论文的核心思路是将决策过程模拟为法庭辩论,通过构建具有明确角色(检察官、辩护律师、法官)的多智能体系统,并定义结构化的交互协议,使决策过程变得透明、可控和可审计。这种设计借鉴了人类的辩论过程,旨在模拟更严谨和全面的推理。
技术框架:AgenticSimLaw框架包含以下主要模块:1) 角色定义:明确定义每个智能体的角色和职责,例如检察官负责提出支持累犯风险的论点,辩护律师负责反驳,法官负责评估论点并做出最终判决。2) 交互协议:采用7轮结构化辩论,包括开场陈述、证据呈现、交叉询问、总结陈词等环节,确保辩论过程的规范性和完整性。3) 推理策略:每个智能体根据自身角色和目标,采用不同的推理策略,例如基于规则的推理、基于案例的推理或基于语言模型的推理。4) 决策模块:法官根据辩论过程中的论点和证据,做出最终的决策。
关键创新:该论文的关键创新在于将多智能体辩论框架应用于高风险表格数据决策,并明确定义了角色、协议和策略,从而实现了决策过程的透明化和可控化。与传统的黑盒模型或简单的CoT提示相比,AgenticSimLaw提供了一种更具解释性和可信度的决策方法。
关键设计:关键设计包括:1) 7轮辩论结构的设计,保证了辩论的完整性和效率。2) 智能体推理策略的选择,可以根据具体任务和数据进行调整。3) 损失函数的设计,用于训练智能体的推理能力,例如可以使用交叉熵损失函数来优化智能体的论点选择。
🖼️ 关键图片

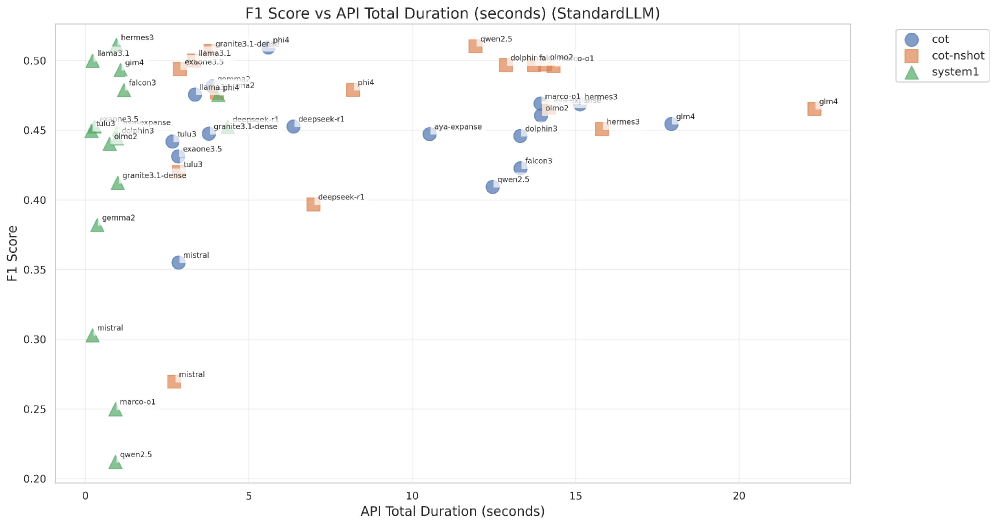
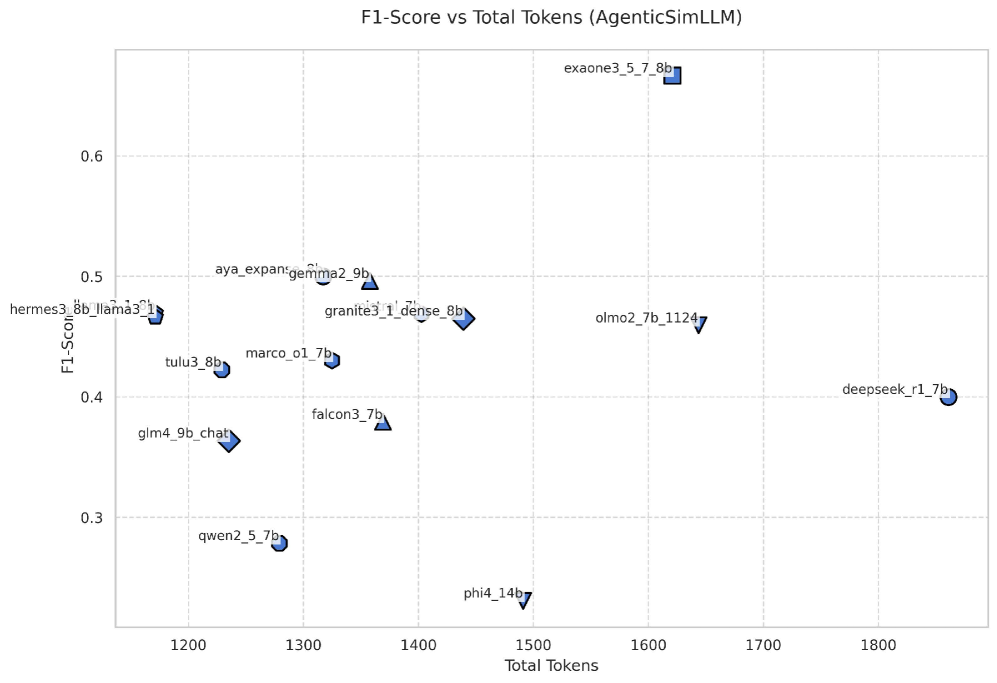
📊 实验亮点
在青少年累犯预测任务上,AgenticSimLaw框架表现出比传统CoT提示更稳定和泛化的性能。实验结果表明,结构化的多智能体辩论能够提高准确率和F1分数,并且准确率和F1分数之间具有更强的相关性。此外,AgenticSimLaw还提供了对推理步骤的细粒度控制,并生成完整的交互记录,从而提高了决策的可解释性。
🎯 应用场景
AgenticSimLaw可应用于各种高风险决策场景,例如刑事司法、医疗诊断、金融风险评估等。该框架能够提高决策的透明度和可解释性,增强决策的可信度和公正性,并为人工监督和审计提供便利。未来,该框架可以进一步扩展到更复杂的决策场景,并与其他技术(例如知识图谱、因果推理)相结合,以提高决策的准确性和可靠性。
📄 摘要(原文)
We introduce AgenticSimLaw, a role-structured, multi-agent debate framework that provides transparent and controllable test-time reasoning for high-stakes tabular decision-making tasks. Unlike black-box approaches, our courtroom-style orchestration explicitly defines agent roles (prosecutor, defense, judge), interaction protocols (7-turn structured debate), and private reasoning strategies, creating a fully auditable decision-making process. We benchmark this framework on young adult recidivism prediction using the NLSY97 dataset, comparing it against traditional chain-of-thought (CoT) prompting across almost 90 unique combinations of models and strategies. Our results demonstrate that structured multi-agent debate provides more stable and generalizable performance compared to single-agent reasoning, with stronger correlation between accuracy and F1-score metrics. Beyond performance improvements, AgenticSimLaw offers fine-grained control over reasoning steps, generates complete interaction transcripts for explainability, and enables systematic profiling of agent behaviors. While we instantiate this framework in the criminal justice domain to stress-test reasoning under ethical complexity, the approach generalizes to any deliberative, high-stakes decision task requiring transparency and human oversight. This work addresses key LLM-based multi-agent system challenges: organization through structured roles, observability through logged interactions, and responsibility through explicit non-deployment constraints for sensitive domains. Data, results, and code will be available on github.com under the MIT license.