Self-Compression of Chain-of-Thought via Multi-Agent Reinforcement Learning
作者: Yiqun Chen, Jinyuan Feng, Wei Yang, Meizhi Zhong, Zhengliang Shi, Rui Li, Xiaochi Wei, Yan Gao, Yi Wu, Yao Hu, Zhiqiang Pu, Jiaxin Mao
分类: cs.AI, cs.CL
发布日期: 2026-01-29
💡 一句话要点
提出基于多智能体强化学习的思维链自压缩方法,提升大模型推理效率与精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链 自压缩 多智能体强化学习 大型语言模型 推理优化
📋 核心要点
- 现有基于强化学习的思维链压缩方法难以平衡推理的简洁性和准确性,强制缩短可能丢失关键逻辑。
- 提出一种多智能体强化学习框架SCMA,通过分割和评分智能体选择性惩罚冗余推理块,保留关键逻辑。
- 实验表明,SCMA在减少响应长度的同时,显著提升了推理准确性,验证了多智能体协同优化的有效性。
📝 摘要(中文)
大型推理模型(LRM)中冗余的推理过程会降低交互体验并严重阻碍部署。现有的基于强化学习(RL)的解决方案通过将长度惩罚与基于结果的奖励相结合来解决这个问题。然而,这种简单的奖励加权难以兼顾简洁性和准确性,因为强制简洁可能会损害关键的推理逻辑。本文提出了一种多智能体RL框架,该框架选择性地惩罚冗余块,同时保留必要的推理逻辑。该框架,即基于MARL的自压缩(SCMA),通过两个专门的智能体来实现冗余检测和评估:一个用于将推理过程分解为逻辑块的分割智能体,以及一个用于量化每个块重要性的评分智能体。分割和评分智能体在训练期间协同定义一个重要性加权的长度惩罚,从而激励推理智能体优先考虑必要的逻辑,而不会在部署期间引入推理开销。跨模型规模的实证评估表明,SCMA将响应长度减少了11.1%至39.0%,同时将准确性提高了4.33%至10.02%。此外,消融研究和定性分析验证了MARL框架内的协同优化促进了涌现行为,从而产生了比vanilla RL范式更强大的LRM。
🔬 方法详解
问题定义:论文旨在解决大型推理模型(LRM)中由于冗余推理过程导致的推理开销问题。现有基于强化学习的方法,通过简单的长度惩罚来压缩推理链,但这种方法难以区分重要和冗余的推理步骤,容易在压缩过程中丢失关键信息,导致推理精度下降。
核心思路:论文的核心思路是利用多智能体强化学习(MARL)框架,将推理链的压缩过程分解为多个子任务,并由不同的智能体协同完成。通过引入分割智能体和评分智能体,分别负责识别推理链中的逻辑块和评估每个块的重要性,从而实现对冗余块的选择性惩罚,保留关键推理逻辑。
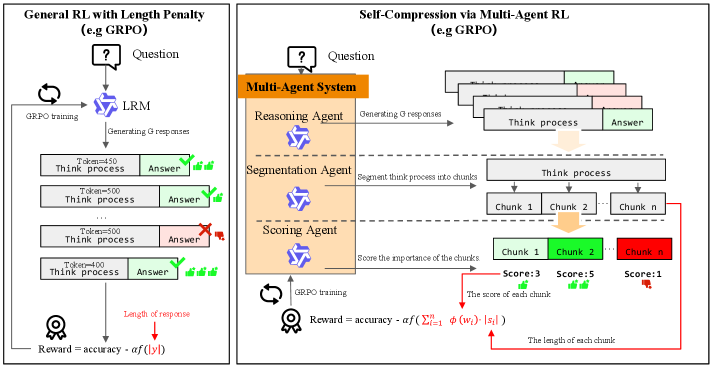
技术框架:SCMA框架包含三个主要智能体:推理智能体、分割智能体和评分智能体。推理智能体负责生成推理链,分割智能体将推理链分解为逻辑块,评分智能体评估每个块的重要性。在训练过程中,分割和评分智能体协同定义一个重要性加权的长度惩罚,用于指导推理智能体的训练,使其在生成推理链时优先考虑重要逻辑,避免冗余推理。在部署阶段,只需要推理智能体,无需额外的推理开销。
关键创新:论文的关键创新在于引入了多智能体强化学习框架,将推理链压缩问题分解为多个子任务,并由不同的智能体协同完成。这种方法能够更精细地控制推理链的压缩过程,避免了简单长度惩罚导致的精度下降问题。此外,通过分割和评分智能体的协同优化,可以学习到更有效的冗余检测和重要性评估策略。
关键设计:分割智能体和评分智能体的具体网络结构未知,但其目标是分别实现推理链的分割和重要性评估。重要性加权的长度惩罚是关键的设计,它将分割和评分智能体的输出与推理智能体的奖励函数相结合,引导推理智能体生成更简洁、更准确的推理链。具体的损失函数和训练算法细节未知。
🖼️ 关键图片

📊 实验亮点
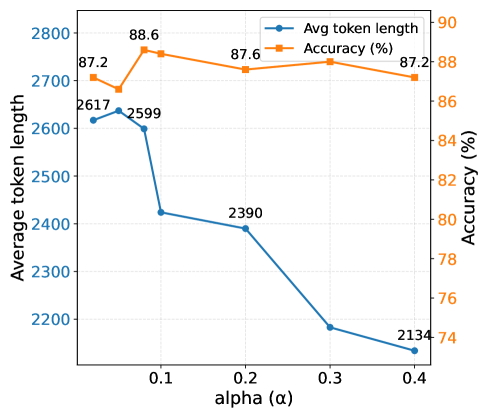
实验结果表明,SCMA在多个数据集和模型规模上均取得了显著的性能提升。例如,在某些任务上,SCMA可以将响应长度减少11.1%到39.0%,同时将准确性提高4.33%到10.02%。消融实验验证了分割和评分智能体的有效性,定性分析表明多智能体协同优化能够产生更强大的推理模型。
🎯 应用场景
该研究成果可应用于各种需要大型推理模型的场景,例如智能客服、自动问答、代码生成等。通过降低推理开销,可以提升用户交互体验,并降低部署成本。未来,该方法可以进一步扩展到其他类型的序列生成任务,例如机器翻译、文本摘要等。
📄 摘要(原文)
The inference overhead induced by redundant reasoning undermines the interactive experience and severely bottlenecks the deployment of Large Reasoning Models. Existing reinforcement learning (RL)-based solutions tackle this problem by coupling a length penalty with outcome-based rewards. This simplistic reward weighting struggles to reconcile brevity with accuracy, as enforcing brevity may compromise critical reasoning logic. In this work, we address this limitation by proposing a multi-agent RL framework that selectively penalizes redundant chunks, while preserving essential reasoning logic. Our framework, Self-Compression via MARL (SCMA), instantiates redundancy detection and evaluation through two specialized agents: \textbf{a Segmentation Agent} for decomposing the reasoning process into logical chunks, and \textbf{a Scoring Agent} for quantifying the significance of each chunk. The Segmentation and Scoring agents collaboratively define an importance-weighted length penalty during training, incentivizing \textbf{a Reasoning Agent} to prioritize essential logic without introducing inference overhead during deployment. Empirical evaluations across model scales demonstrate that SCMA reduces response length by 11.1\% to 39.0\% while boosting accuracy by 4.33\% to 10.02\%. Furthermore, ablation studies and qualitative analysis validate that the synergistic optimization within the MARL framework fosters emergent behaviors, yielding more powerful LRMs compared to vanilla RL paradigms.