ProRAG: Process-Supervised Reinforcement Learning for Retrieval-Augmented Generation
作者: Zhao Wang, Ziliang Zhao, Zhicheng Dou
分类: cs.AI, cs.CL, cs.IR
发布日期: 2026-01-29
备注: 11 pages, 6 figures
🔗 代码/项目: GITHUB
💡 一句话要点
ProRAG:面向检索增强生成的过程监督强化学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 检索增强生成 强化学习 过程监督 多跳推理 奖励塑造
📋 核心要点
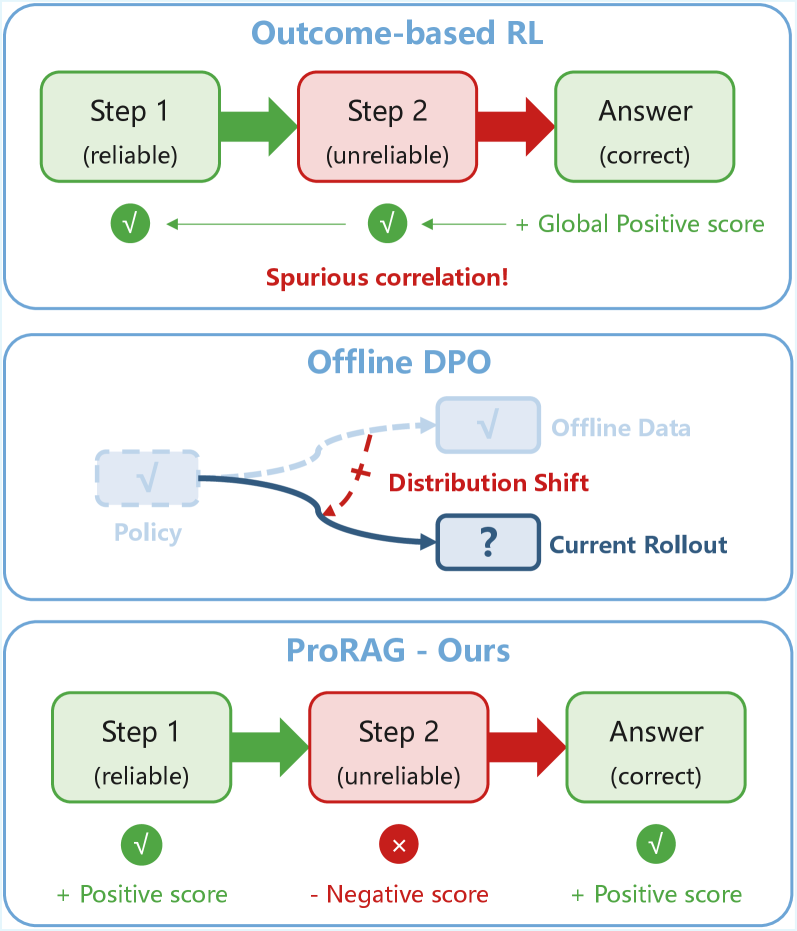
- 现有基于结果的强化学习方法在RAG中存在奖励稀疏和信用分配困难,导致模型产生“过程幻觉”。
- ProRAG通过构建过程奖励模型(PRM)并结合双粒度优势机制,将步骤级监督融入在线优化循环。
- 实验表明,ProRAG在多跳推理任务上优于现有方法,尤其在长序列任务中,验证了过程监督的有效性。
📝 摘要(中文)
强化学习(RL)已成为优化复杂推理任务中检索增强生成(RAG)的一种有前景的范例。然而,传统的基于结果的RL方法通常面临奖励稀疏和信用分配效率低下的问题,因为粗粒度的标量奖励无法识别长序列中特定的错误步骤。这种模糊性经常导致“过程幻觉”,即模型通过有缺陷的逻辑或冗余的检索步骤获得正确的答案。虽然最近的过程感知方法试图通过静态偏好学习或启发式奖励塑造来缓解这个问题,但它们通常缺乏解耦步骤级信用与全局结果所需的在线探索能力。为了解决这些挑战,我们提出了ProRAG,一个过程监督强化学习框架,旨在将学习到的步骤级监督集成到在线优化循环中。我们的框架包括四个阶段:(1)监督策略预热,以使用结构化的推理格式初始化模型;(2)构建基于MCTS的过程奖励模型(PRM)来量化中间推理质量;(3)PRM引导的推理细化,使策略与细粒度的过程偏好对齐;(4)具有双粒度优势机制的过程监督强化学习。通过将步骤级过程奖励与全局结果信号聚合,ProRAG为每个动作提供精确的反馈。在五个多跳推理基准上的大量实验表明,与强大的基于结果和过程感知的RL基线相比,ProRAG实现了卓越的整体性能,尤其是在复杂的长序列任务上,验证了细粒度过程监督的有效性。
🔬 方法详解
问题定义:论文旨在解决检索增强生成(RAG)中,使用强化学习进行优化时,由于奖励稀疏和信用分配困难导致模型产生“过程幻觉”的问题。现有方法,如基于结果的强化学习,无法有效区分推理过程中的正确与错误步骤,而过程感知方法又缺乏足够的在线探索能力。
核心思路:ProRAG的核心思路是通过引入过程监督,为强化学习提供更细粒度的反馈信号。具体来说,它构建了一个过程奖励模型(PRM),用于评估中间推理步骤的质量,并将这些评估结果作为强化学习的奖励信号,从而引导模型学习更合理的推理过程。
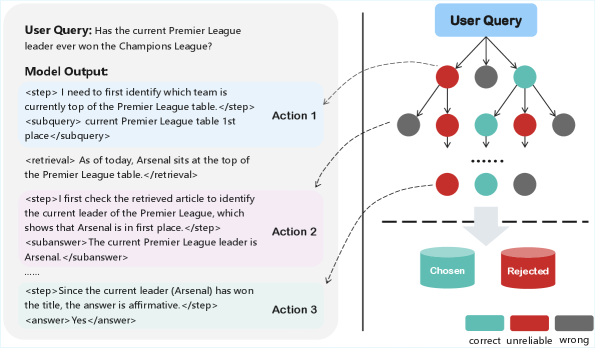
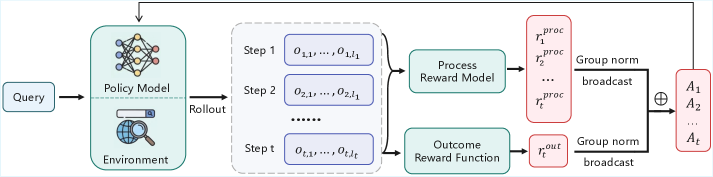
技术框架:ProRAG框架包含四个主要阶段:1) 监督策略预热:使用监督学习初始化模型,使其具备结构化的推理能力。2) 构建过程奖励模型(PRM):利用蒙特卡洛树搜索(MCTS)构建PRM,用于量化中间推理步骤的质量。3) PRM引导的推理细化:利用PRM的反馈,调整策略,使其与细粒度的过程偏好对齐。4) 过程监督强化学习:使用双粒度优势机制,结合步骤级过程奖励和全局结果信号,进行强化学习。
关键创新:ProRAG的关键创新在于将过程监督融入到强化学习的在线优化循环中。与传统的基于结果的强化学习相比,ProRAG能够提供更精确的反馈,从而避免模型陷入“过程幻觉”。与现有的过程感知方法相比,ProRAG具有更强的在线探索能力,能够更好地解耦步骤级信用与全局结果。
关键设计:ProRAG的关键设计包括:1) 过程奖励模型(PRM):PRM基于MCTS构建,用于评估中间推理步骤的质量。具体实现细节(如MCTS的搜索策略、奖励函数等)未知。2) 双粒度优势机制:该机制结合了步骤级过程奖励和全局结果信号,用于计算强化学习的优势函数。具体实现细节(如如何平衡两种奖励信号)未知。
🖼️ 关键图片
📊 实验亮点
ProRAG在五个多跳推理基准测试中表现优异,显著优于基于结果和过程感知的强化学习基线。尤其在复杂的长序列任务中,ProRAG的性能提升更为明显,验证了细粒度过程监督的有效性。具体性能数据和提升幅度在论文中给出,此处未提供。
🎯 应用场景
ProRAG可应用于需要复杂推理和知识检索的各种场景,例如问答系统、对话生成、代码生成等。通过提高模型推理过程的合理性和准确性,ProRAG能够提升这些应用的用户体验和可靠性,尤其是在需要长序列推理的任务中具有显著优势。
📄 摘要(原文)
Reinforcement learning (RL) has become a promising paradigm for optimizing Retrieval-Augmented Generation (RAG) in complex reasoning tasks. However, traditional outcome-based RL approaches often suffer from reward sparsity and inefficient credit assignment, as coarse-grained scalar rewards fail to identify specific erroneous steps within long-horizon trajectories. This ambiguity frequently leads to "process hallucinations", where models reach correct answers through flawed logic or redundant retrieval steps. Although recent process-aware approaches attempt to mitigate this via static preference learning or heuristic reward shaping, they often lack the on-policy exploration capabilities required to decouple step-level credit from global outcomes. To address these challenges, we propose ProRAG, a process-supervised reinforcement learning framework designed to integrate learned step-level supervision into the online optimization loop. Our framework consists of four stages: (1) Supervised Policy Warmup to initialize the model with a structured reasoning format; (2) construction of an MCTS-based Process Reward Model (PRM) to quantify intermediate reasoning quality; (3) PRM-Guided Reasoning Refinement to align the policy with fine-grained process preferences; and (4) Process-Supervised Reinforcement Learning with a dual-granularity advantage mechanism. By aggregating step-level process rewards with global outcome signals, ProRAG provides precise feedback for every action. Extensive experiments on five multi-hop reasoning benchmarks demonstrate that ProRAG achieves superior overall performance compared to strong outcome-based and process-aware RL baselines, particularly on complex long-horizon tasks, validating the effectiveness of fine-grained process supervision. The code and model are available at https://github.com/lilinwz/ProRAG.