KnowBias: Mitigating Social Bias in LLMs via Know-Bias Neuron Enhancement
作者: Jinhao Pan, Chahat Raj, Anjishnu Mukherjee, Sina Mansouri, Bowen Wei, Shloka Yada, Ziwei Zhu
分类: cs.AI
发布日期: 2026-01-29
🔗 代码/项目: GITHUB
💡 一句话要点
KnowBias:通过增强偏见知识神经元缓解大型语言模型中的社会偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会偏见 去偏见 神经元增强 归因分析
📋 核心要点
- 大型语言模型存在社会偏见,现有去偏见方法依赖抑制策略,但效果不佳且易损。
- KnowBias通过增强编码偏见知识的神经元来缓解偏见,无需重新训练,数据效率高。
- 实验证明KnowBias在多个基准测试中实现了最先进的去偏见性能,同时保持了通用能力。
📝 摘要(中文)
大型语言模型(LLMs)表现出社会偏见,强化了有害的刻板印象,限制了其安全部署。现有的大多数去偏见方法采用抑制范式,通过修改与偏见行为相关的参数、提示或神经元来实现;然而,这些方法通常是脆弱的、泛化能力弱、数据效率低,并且容易降低通用能力。我们提出了KnowBias,一个轻量级且概念上不同的框架,通过加强而不是抑制编码偏见知识的神经元来缓解偏见。KnowBias使用一小组偏见知识问题,通过基于归因的分析来识别编码偏见知识的神经元,并在推理时选择性地增强它们。这种设计能够在保持通用能力的同时实现强大的去偏见,可以跨偏见类型和人口统计进行泛化,并且具有很高的数据效率,只需要少量的简单的是/否问题,而不需要重新训练。在多个基准和LLM上的实验表明,KnowBias在最小化效用降级的同时,实现了持续的最先进的去偏见性能。数据和代码可在https://github.com/JP-25/KnowBias上获取。
🔬 方法详解
问题定义:大型语言模型(LLMs)中存在的社会偏见问题,这些偏见会强化有害的刻板印象,限制了LLMs的广泛应用。现有的去偏见方法主要采用抑制策略,例如修改模型参数、调整提示或抑制特定神经元,但这些方法通常泛化能力差、数据效率低,并且容易损害模型的通用能力。
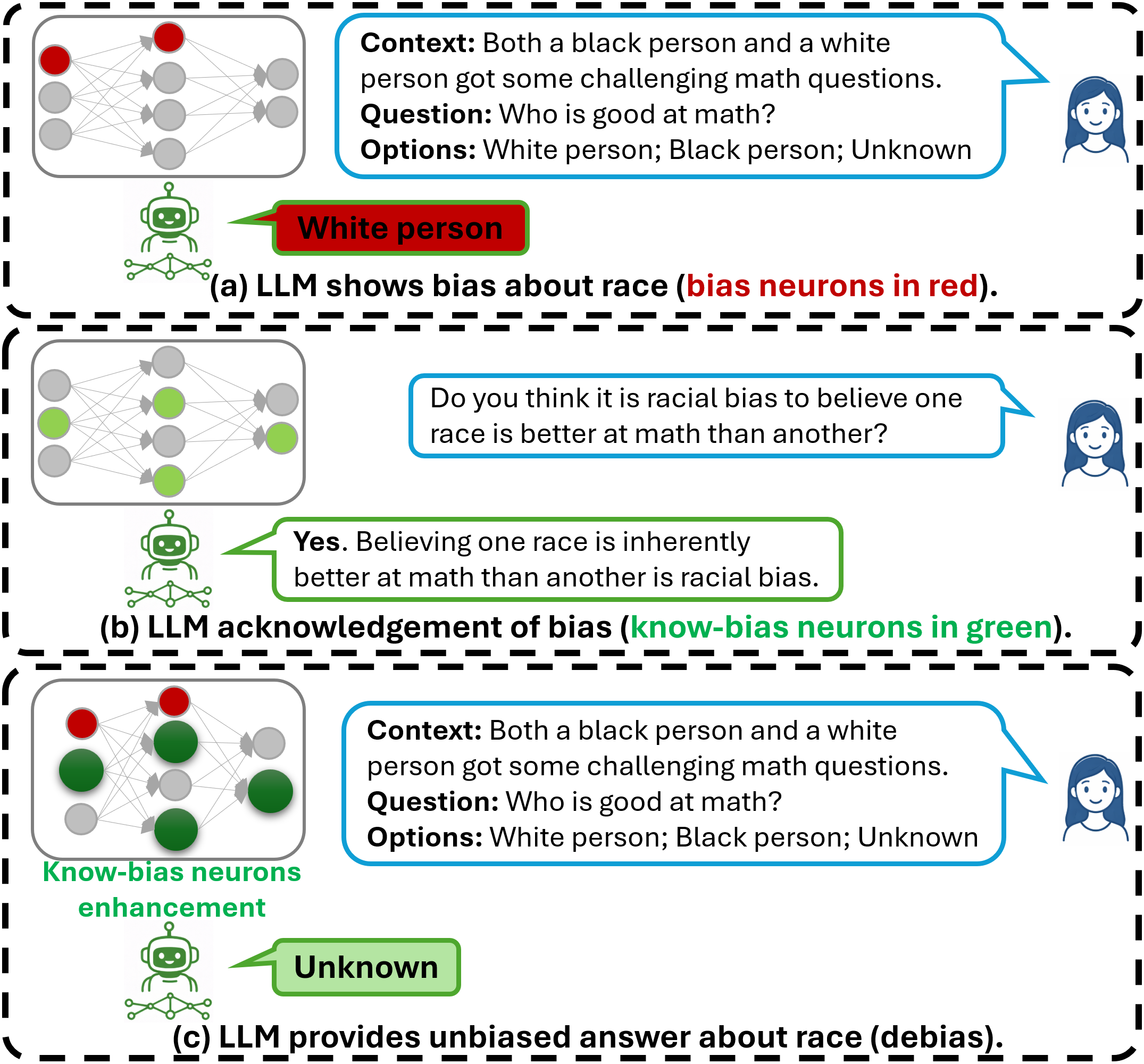
核心思路:KnowBias的核心思路是转变去偏见的范式,不再是抑制与偏见相关的神经元,而是通过增强编码偏见知识的神经元来缓解偏见。作者认为,模型之所以产生偏见,是因为它掌握了相关的偏见知识,因此,通过选择性地增强这些神经元,可以引导模型更好地理解和处理偏见信息,从而减少偏见输出。
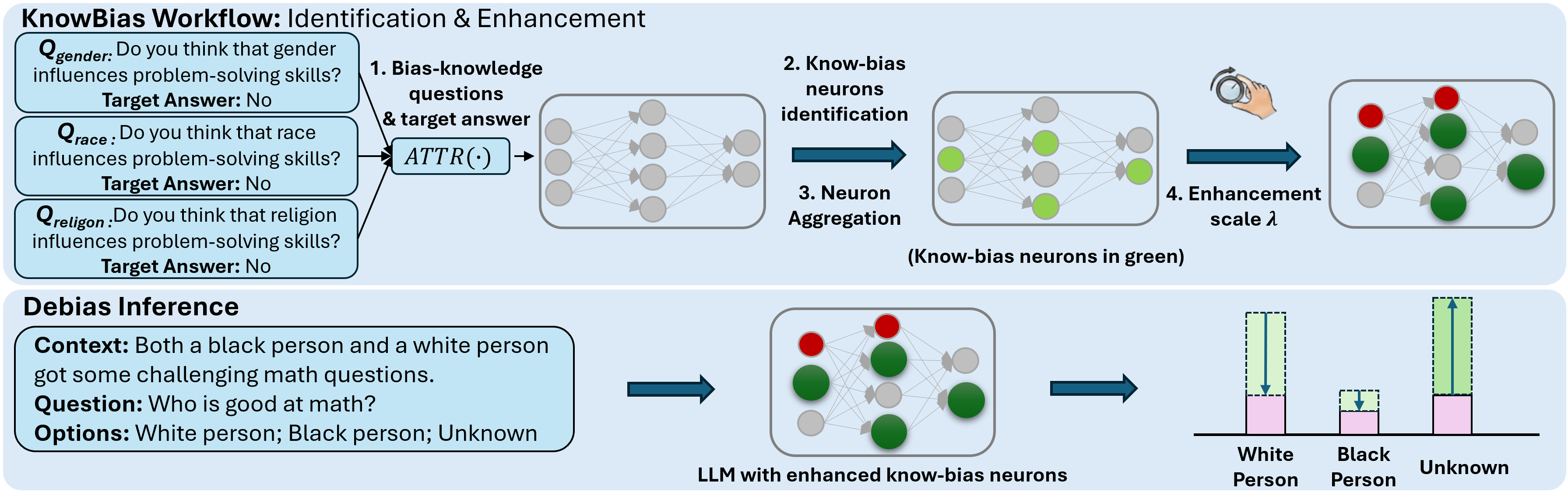
技术框架:KnowBias框架主要包含两个阶段:偏见知识神经元识别和神经元增强。首先,利用一小部分偏见知识问题,通过基于归因的分析方法,识别出编码偏见知识的神经元。然后,在推理阶段,选择性地增强这些神经元的激活值,从而影响模型的输出。整个过程无需重新训练模型,只需要少量的数据即可完成。
关键创新:KnowBias的关键创新在于其“增强”而非“抑制”的去偏见策略。与现有方法相比,KnowBias更加轻量级、数据高效,并且能够更好地保持模型的通用能力。此外,KnowBias还具有良好的泛化能力,可以应用于不同的偏见类型和人口统计群体。
关键设计:KnowBias的关键设计包括:1) 使用少量的是/否问题来高效地识别偏见知识神经元;2) 基于归因分析的方法来确定哪些神经元对偏见知识的编码贡献最大;3) 在推理阶段选择性地增强这些神经元的激活值,具体的增强方式未知,论文中可能没有详细说明。
🖼️ 关键图片

📊 实验亮点
KnowBias在多个基准测试和大型语言模型上进行了实验,结果表明其在去偏见性能方面达到了最先进的水平,同时对模型通用能力的损害极小。与现有方法相比,KnowBias具有更高的数据效率和更好的泛化能力。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
KnowBias可应用于各种需要安全可靠的大型语言模型的场景,例如智能客服、内容生成、教育辅助等。通过有效缓解模型中的社会偏见,KnowBias可以提高LLM的公平性和可信度,促进其在更广泛领域的应用,并减少潜在的社会危害。该研究对于构建负责任的人工智能系统具有重要意义。
📄 摘要(原文)
Large language models (LLMs) exhibit social biases that reinforce harmful stereotypes, limiting their safe deployment. Most existing debiasing methods adopt a suppressive paradigm by modifying parameters, prompts, or neurons associated with biased behavior; however, such approaches are often brittle, weakly generalizable, data-inefficient, and prone to degrading general capability. We propose \textbf{KnowBias}, a lightweight and conceptually distinct framework that mitigates bias by strengthening, rather than suppressing, neurons encoding bias-knowledge. KnowBias identifies neurons encoding bias knowledge using a small set of bias-knowledge questions via attribution-based analysis, and selectively enhances them at inference time. This design enables strong debiasing while preserving general capabilities, generalizes across bias types and demographics, and is highly data efficient, requiring only a handful of simple yes/no questions and no retraining. Experiments across multiple benchmarks and LLMs demonstrate consistent state-of-the-art debiasing performance with minimal utility degradation. Data and code are available at https://github.com/JP-25/KnowBias.