Looking Beyond Accuracy: A Holistic Benchmark of ECG Foundation Models
作者: Francesca Filice, Edoardo De Rose, Simone Bartucci, Francesco Calimeri, Simona Perri
分类: cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出心电图(ECG)基础模型的全面基准测试框架,超越传统准确率评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心电图分析 基础模型 基准测试 表征学习 SHAP UMAP 泛化能力 数据稀缺
📋 核心要点
- 现有ECG基础模型基准测试主要关注下游任务性能,缺乏对模型表征能力和泛化性的深入分析。
- 提出一种综合基准测试框架,结合性能评估和表征层面分析,利用SHAP和UMAP等技术。
- 通过跨大陆数据集和不同数据可用性设置的实验,揭示ECG基础模型的表征结构和泛化能力。
📝 摘要(中文)
心电图(ECG)是一种经济高效、易于获取且广泛使用的诊断工具。随着基础模型(FMs)的出现,AI辅助ECG判读领域开始发展,因为它们可以通过依赖嵌入来实现跨不同任务的模型重用。然而,为了负责任地使用FMs,至关重要的是严格评估它们产生的嵌入的泛化程度,尤其是在医疗保健等对错误敏感的领域。虽然之前的工作已经解决了ECG专家FMs的基准测试问题,但它们主要关注下游性能的评估。为了填补这一空白,本研究旨在为FMs找到一个深入、全面的基准测试框架,特别关注ECG专家FMs。为此,我们引入了一种基准测试方法,该方法通过利用SHAP和UMAP技术,用表征层面的分析来补充基于性能的评估。此外,我们依靠该方法对通过最先进技术在不同的跨大陆数据集和数据可用性设置下预训练的几个ECG专家FMs进行了广泛的评估;这包括数据稀缺的情况,这是现实世界医疗场景中相当常见的情况。实验结果表明,我们的基准测试协议提供了对ECG专家FMs嵌入模式的丰富见解,从而能够更深入地了解它们的表征结构和泛化能力。
🔬 方法详解
问题定义:现有ECG基础模型的评估主要集中在下游任务的准确率上,忽略了模型内部表征的质量和泛化能力。尤其是在医疗领域,模型的可靠性和可解释性至关重要,仅仅依靠准确率无法全面评估模型的优劣。数据稀缺是医疗领域常见的问题,现有方法在数据稀缺情况下的表现也需要深入研究。
核心思路:本研究的核心思路是构建一个更全面的基准测试框架,不仅评估模型的下游任务性能,还深入分析模型的表征空间。通过分析模型的表征,可以更好地理解模型的泛化能力、鲁棒性和可解释性。该框架旨在弥补现有基准测试的不足,为ECG基础模型的选择和改进提供更全面的依据。
技术框架:该基准测试框架包含以下几个主要模块:1) 性能评估:评估模型在各种下游任务上的性能,如心律失常分类、心肌梗塞检测等。2) 表征分析:利用SHAP和UMAP等技术,对模型的表征空间进行可视化和分析。SHAP用于解释模型的预测结果,UMAP用于降维和可视化高维表征。3) 泛化能力评估:在不同的数据集和数据可用性设置下评估模型的泛化能力,包括跨大陆数据集和数据稀缺情况。
关键创新:该研究的关键创新在于提出了一个综合的基准测试框架,将性能评估和表征分析相结合。通过表征分析,可以更深入地了解模型的内部机制和泛化能力。此外,该研究还关注了数据稀缺情况下的模型表现,这在现实世界的医疗场景中非常重要。
关键设计:在表征分析方面,使用了SHAP值来解释模型的预测结果,从而了解哪些输入特征对模型的预测影响最大。UMAP用于将高维表征降维到二维或三维空间,以便可视化和分析。在数据稀缺情况下,研究了不同的数据增强技术和迁移学习策略,以提高模型的性能。
🖼️ 关键图片
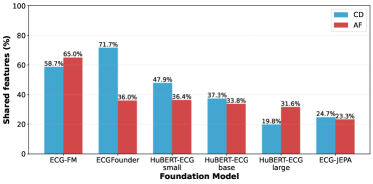

📊 实验亮点
实验结果表明,该基准测试框架能够提供对ECG专家FMs嵌入模式的丰富见解,从而能够更深入地了解它们的表征结构和泛化能力。通过SHAP和UMAP分析,可以发现不同模型在表征学习上的差异,并识别出模型可能存在的偏差。在数据稀缺情况下,一些模型表现出较好的泛化能力,而另一些模型则表现不佳,这为模型的选择和改进提供了重要的参考。
🎯 应用场景
该研究成果可应用于心电图自动诊断系统、远程医疗、可穿戴设备等领域。通过更全面地评估ECG基础模型,可以提高诊断的准确性和可靠性,降低误诊率,改善患者的医疗体验。此外,该基准测试框架可以促进ECG基础模型的研究和发展,推动AI在医疗领域的应用。
📄 摘要(原文)
The electrocardiogram (ECG) is a cost-effective, highly accessible and widely employed diagnostic tool. With the advent of Foundation Models (FMs), the field of AI-assisted ECG interpretation has begun to evolve, as they enable model reuse across different tasks by relying on embeddings. However, to responsibly employ FMs, it is crucial to rigorously assess to which extent the embeddings they produce are generalizable, particularly in error-sensitive domains such as healthcare. Although prior works have already addressed the problem of benchmarking ECG-expert FMs, they focus predominantly on the evaluation of downstream performance. To fill this gap, this study aims to find an in-depth, comprehensive benchmarking framework for FMs, with a specific focus on ECG-expert ones. To this aim, we introduce a benchmark methodology that complements performance-based evaluation with representation-level analysis, leveraging SHAP and UMAP techniques. Furthermore, we rely on the methodology for carrying out an extensive evaluation of several ECG-expert FMs pretrained via state-of-the-art techniques over different cross-continental datasets and data availability settings; this includes ones featuring data scarcity, a fairly common situation in real-world medical scenarios. Experimental results show that our benchmarking protocol provides a rich insight of ECG-expert FMs' embedded patterns, enabling a deeper understanding of their representational structure and generalizability.