Assessing the Business Process Modeling Competences of Large Language Models
作者: Chantale Lauer, Peter Pfeiffer, Alexander Rombach, Nijat Mehdiyev
分类: cs.SE, cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出BEF4LLM框架,评估大语言模型在业务流程建模中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 业务流程建模 BPMN 模型评估 BEF4LLM
📋 核心要点
- 现有方法缺乏对LLM生成业务流程模型(BPMN)的系统评估,无法有效衡量模型质量。
- 提出BEF4LLM框架,从句法、语用、语义和有效性四个维度全面评估LLM生成的BPMN模型。
- 实验表明,LLM在句法和语用质量上表现出色,但在语义质量和有效性方面仍有提升空间。
📝 摘要(中文)
创建业务流程模型和符号(BPMN)模型是一项复杂且耗时的任务,需要领域知识和建模规范的熟练掌握。大型语言模型(LLM)的最新进展极大地扩展了直接从自然语言生成BPMN模型的可能性,在早期文本到流程方法的基础上,增强了处理复杂描述的能力。然而,目前缺乏对LLM生成的流程模型的系统评估。现有的工作要么使用LLM作为评判者,要么不考虑已建立的模型质量维度。为此,我们引入了BEF4LLM,这是一个新颖的LLM评估框架,包含四个视角:句法质量、语用质量、语义质量和有效性。我们使用BEF4LLM对开源LLM进行了全面分析,并以人类建模专家为基准测试了它们的性能。结果表明,LLM在句法和语用质量方面表现出色,而人类在语义方面表现优于LLM;然而,分数差异相对较小,突显了LLM的竞争潜力,尽管在有效性和语义质量方面存在挑战。这些见解突出了使用LLM进行BPMN建模的当前优势和局限性,并指导未来的模型开发和微调。解决这些领域对于推进LLM在业务流程建模中的实际部署至关重要。
🔬 方法详解
问题定义:论文旨在解决如何系统性地评估大型语言模型(LLM)在业务流程建模(BPMN)方面的能力。现有方法要么依赖LLM自身进行评估(LLM-as-a-judge),可能存在偏差;要么忽略了已建立的模型质量维度,无法全面衡量LLM生成模型的优劣。这导致无法准确了解LLM在BPMN建模中的优势和不足,阻碍了其在实际业务场景中的应用。
核心思路:论文的核心思路是构建一个多维度的评估框架,即BEF4LLM,从句法、语用、语义和有效性四个角度对LLM生成的BPMN模型进行全面评估。通过对比LLM与人类专家的表现,揭示LLM在不同维度上的优势和劣势,从而为LLM的进一步开发和微调提供指导。这种多维度评估方法能够更客观、更全面地反映LLM在BPMN建模中的能力。
技术框架:BEF4LLM框架包含以下四个主要模块:1) 句法质量评估:评估模型是否符合BPMN的语法规则;2) 语用质量评估:评估模型是否易于理解和使用;3) 语义质量评估:评估模型是否准确地反映了业务流程的含义;4) 有效性评估:评估模型是否能够解决实际的业务问题。该框架使用一系列指标来量化每个维度的质量,并提供了一个统一的评估标准。
关键创新:BEF4LLM框架的关键创新在于其多维度的评估方法,它超越了传统的单一指标评估,能够更全面地评估LLM在BPMN建模中的能力。此外,该框架还引入了有效性评估,关注模型在解决实际业务问题中的表现,这使得评估结果更具实用价值。与现有方法相比,BEF4LLM能够更准确地识别LLM的优势和不足,为LLM的进一步开发提供更有效的指导。
关键设计:BEF4LLM框架的具体实现细节包括:针对每个维度设计了相应的评估指标,例如,句法质量可以使用BPMN验证工具进行检查;语用质量可以通过用户调查进行评估;语义质量可以通过专家评审进行评估;有效性可以通过模拟业务场景进行评估。论文还详细描述了如何收集和处理评估数据,以及如何使用统计方法分析评估结果。具体的参数设置、损失函数、网络结构等技术细节取决于所评估的LLM模型。
🖼️ 关键图片
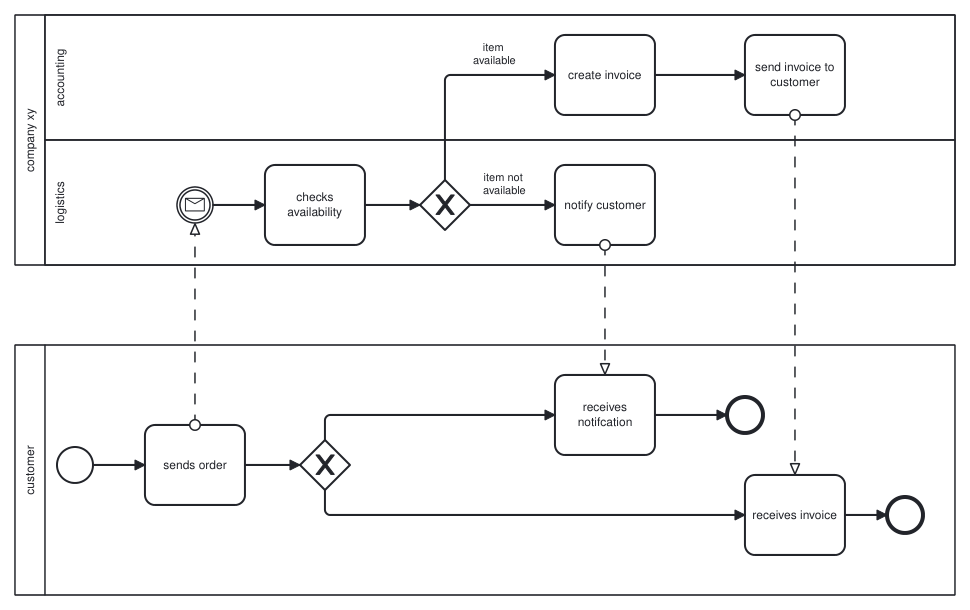
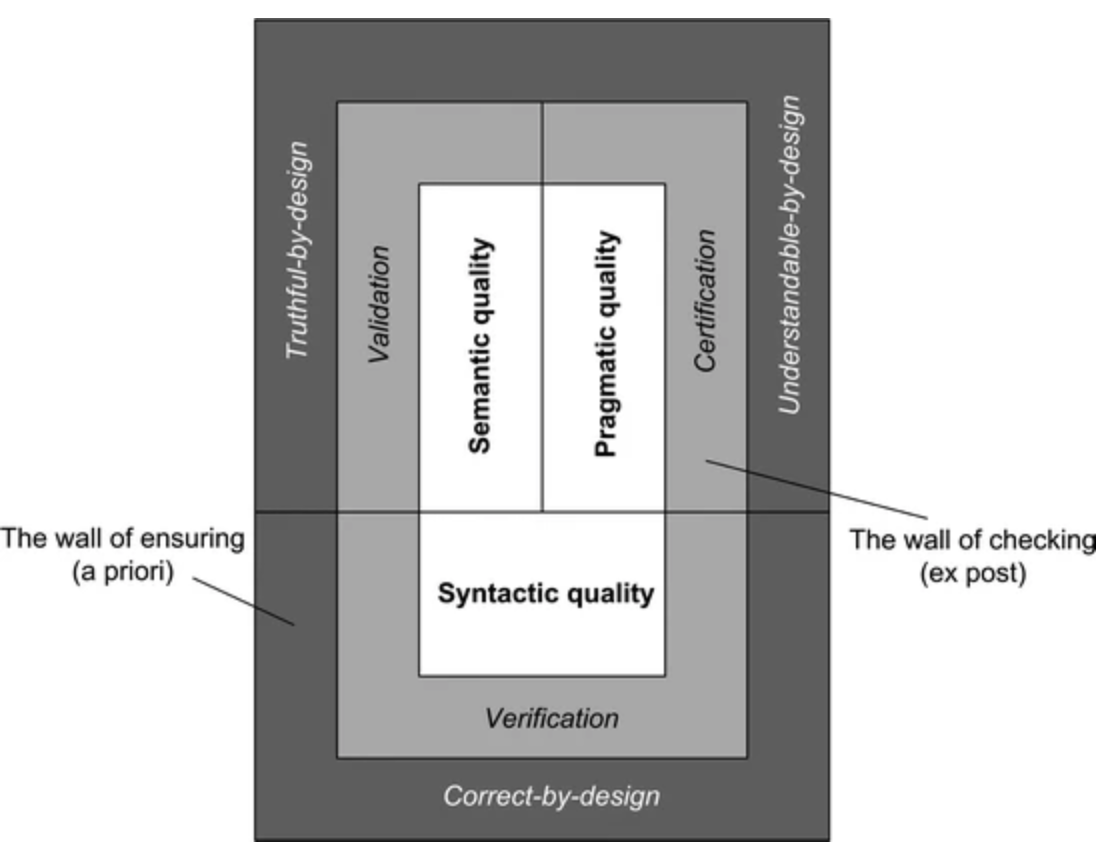
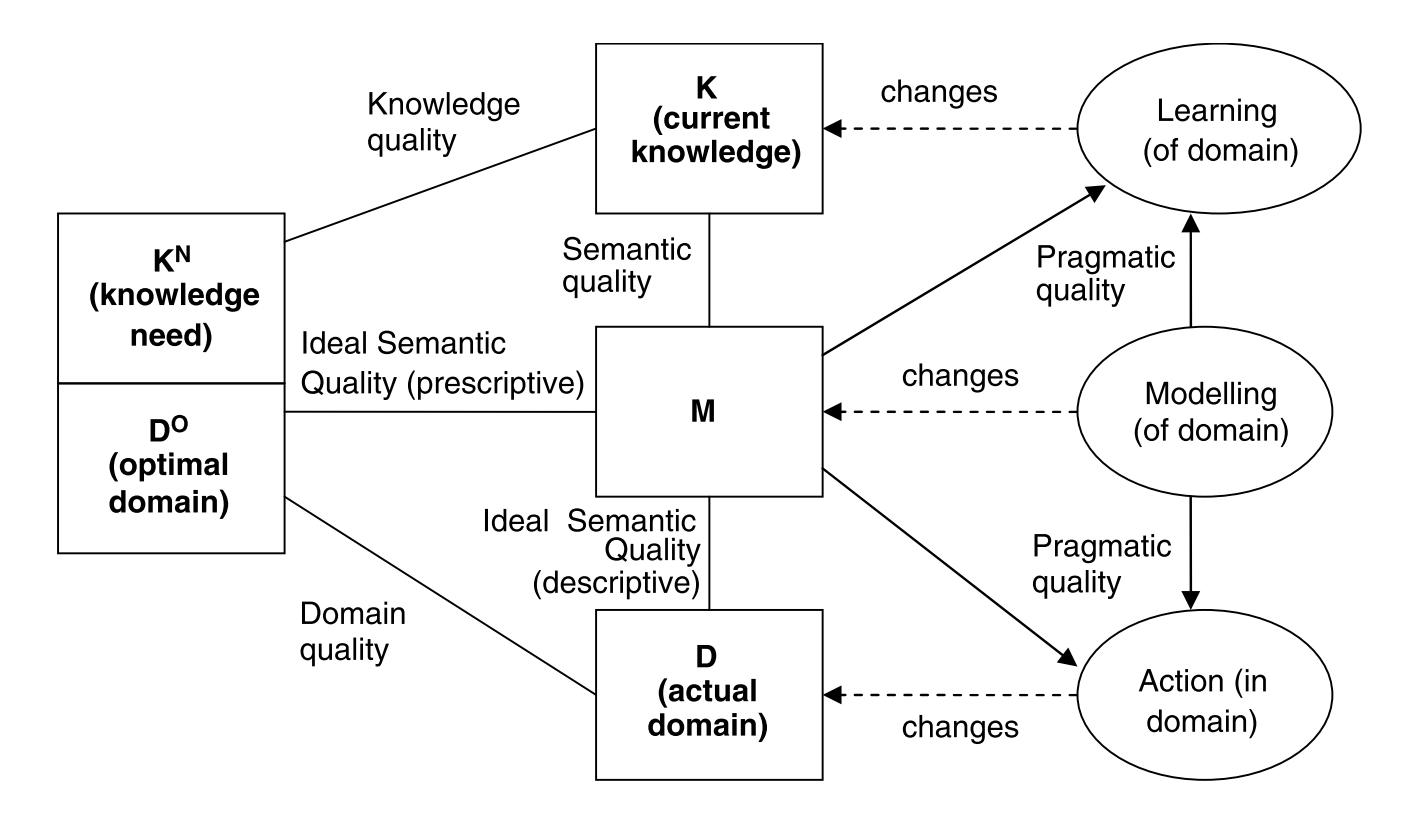
📊 实验亮点
实验结果表明,LLM在句法和语用质量方面表现出色,与人类专家相比差距较小。然而,在语义质量和有效性方面,LLM仍有提升空间。尽管如此,LLM在BPMN建模方面的潜力不容忽视,通过进一步的微调和优化,有望在未来实现与人类专家相媲美的性能。
🎯 应用场景
该研究成果可应用于自动化业务流程建模、智能流程优化、以及辅助业务分析师快速构建流程模型等领域。通过BEF4LLM框架,可以更有效地评估和选择适合特定业务场景的LLM,从而提高业务流程建模的效率和质量,降低建模成本,并加速数字化转型。
📄 摘要(原文)
The creation of Business Process Model and Notation (BPMN) models is a complex and time-consuming task requiring both domain knowledge and proficiency in modeling conventions. Recent advances in large language models (LLMs) have significantly expanded the possibilities for generating BPMN models directly from natural language, building upon earlier text-to-process methods with enhanced capabilities in handling complex descriptions. However, there is a lack of systematic evaluations of LLM-generated process models. Current efforts either use LLM-as-a-judge approaches or do not consider established dimensions of model quality. To this end, we introduce BEF4LLM, a novel LLM evaluation framework comprising four perspectives: syntactic quality, pragmatic quality, semantic quality, and validity. Using BEF4LLM, we conduct a comprehensive analysis of open-source LLMs and benchmark their performance against human modeling experts. Results indicate that LLMs excel in syntactic and pragmatic quality, while humans outperform in semantic aspects; however, the differences in scores are relatively modest, highlighting LLMs' competitive potential despite challenges in validity and semantic quality. The insights highlight current strengths and limitations of using LLMs for BPMN modeling and guide future model development and fine-tuning. Addressing these areas is essential for advancing the practical deployment of LLMs in business process modeling.