EWSJF: An Adaptive Scheduler with Hybrid Partitioning for Mixed-Workload LLM Inference
作者: Bronislav Sidik, Chaya Levi, Joseph Kampeas
分类: cs.DC, cs.AI
发布日期: 2026-01-29
💡 一句话要点
EWSJF:一种混合负载LLM推理的自适应混合分区调度器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推理 请求调度 混合工作负载 自适应调度 贝叶斯优化
📋 核心要点
- 现有LLM服务中,FCFS调度策略在混合负载下存在队头阻塞,导致长尾延迟和资源利用率低。
- EWSJF通过实时学习工作负载结构,自适应地将请求划分到不同的性能同质组,并动态调整优先级。
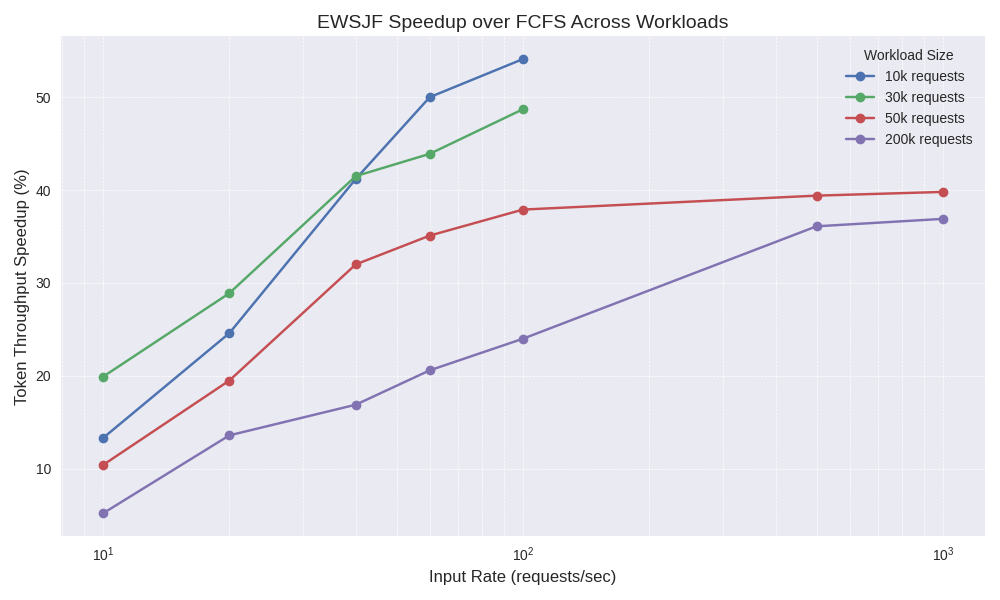
- 实验表明,EWSJF在vLLM中实现了显著的性能提升,吞吐量提高30%以上,短请求延迟降低4倍。
📝 摘要(中文)
本文提出EWSJF(Effective Workload-based Shortest Job First),一种自适应请求级别调度器,用于解决混合工作负载下(短时、延迟敏感的交互式查询与长时、吞吐量导向的批处理请求)的大型语言模型(LLM)服务调度难题。传统FCFS策略存在严重的队头阻塞问题,导致高尾部延迟和硬件利用率不足。EWSJF实时学习工作负载结构,以共同提高公平性和吞吐量。EWSJF运行于执行级别调度器上游,包含四个组件:(1)Refine-and-Prune,一种发现性能同质请求组的无监督分区算法;(2)动态队列路由,用于将请求分配到这些组;(3)密度加权评分,一种平衡紧急性和公平性的上下文感知优先级函数;(4)贝叶斯元优化,基于实时性能反馈持续调整评分和分区参数。在vLLM中实现后,EWSJF相比FCFS,端到端吞吐量提高30%以上,短请求的平均首token时间缩短高达4倍。结果表明,自适应、基于学习的请求调度是高效、响应式LLM服务的关键缺失层。
🔬 方法详解
问题定义:论文旨在解决混合工作负载下LLM推理服务的调度问题,即如何同时优化短时交互式请求的低延迟和长时批处理请求的高吞吐量。传统的FCFS调度策略无法有效区分不同类型的请求,导致短请求被长请求阻塞,产生较高的尾部延迟,并且整体硬件利用率不高。
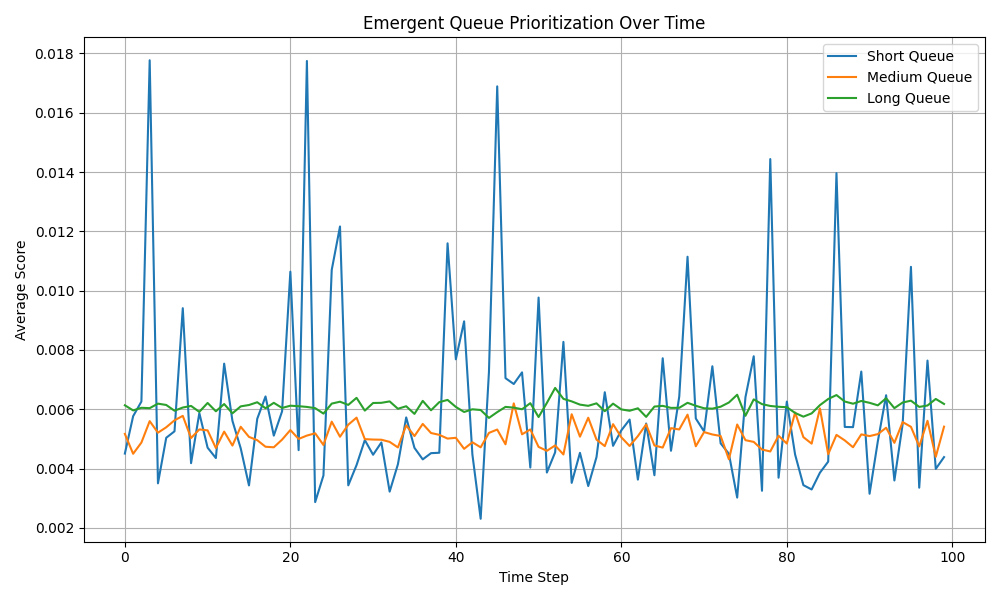
核心思路:EWSJF的核心思路是根据请求的特性,将混合工作负载划分为多个性能同质的请求组,并为每个组动态调整优先级,从而实现公平性和吞吐量的平衡。通过实时学习工作负载的结构,EWSJF能够自适应地调整分组策略和优先级,以适应不断变化的工作负载。
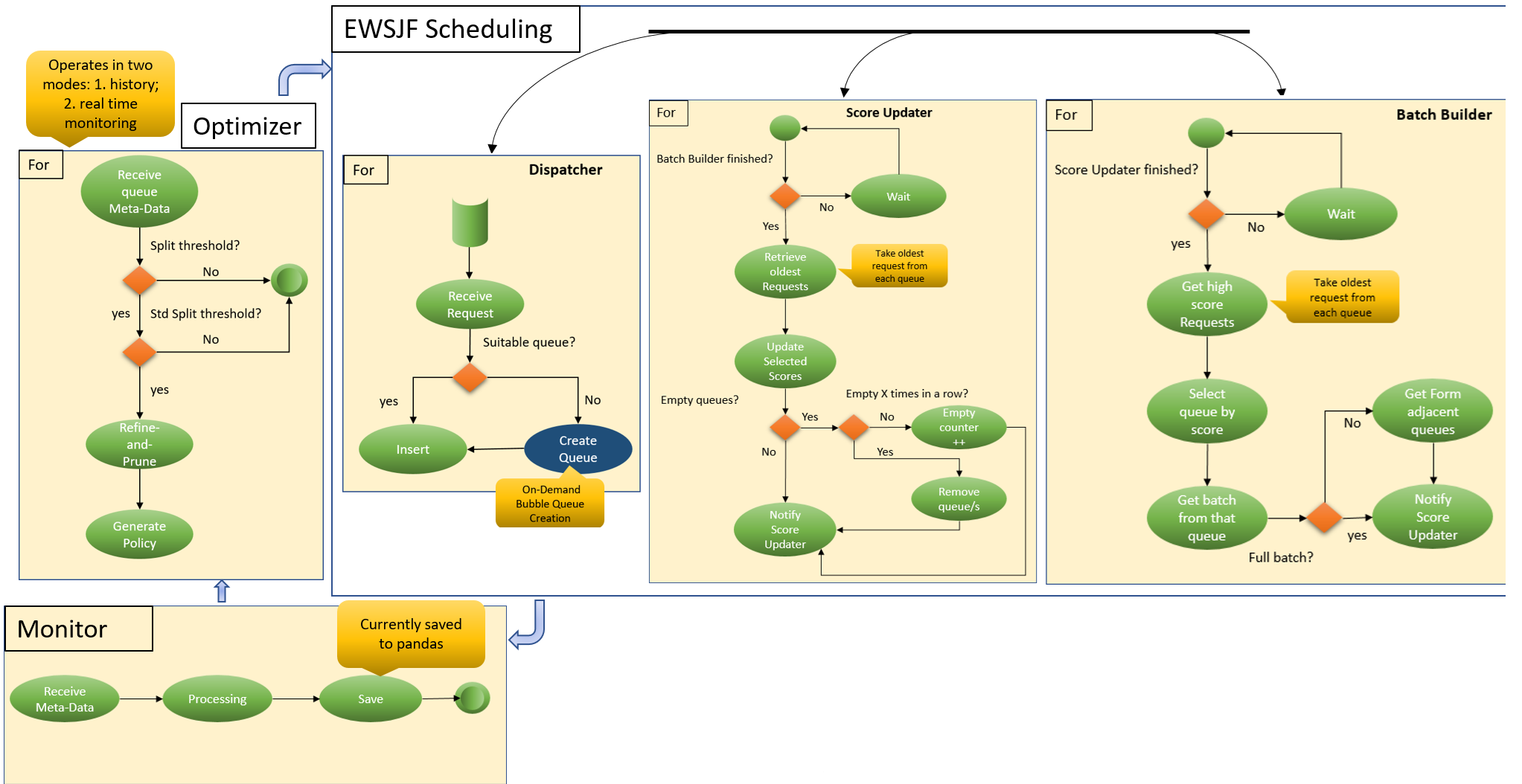
技术框架:EWSJF包含四个主要模块:(1) Refine-and-Prune:使用无监督学习算法将请求划分为性能同质的组。(2) 动态队列路由:根据请求的特征将其分配到相应的组。(3) 密度加权评分:根据请求的紧急程度和所属组的密度,计算请求的优先级。(4) 贝叶斯元优化:使用贝叶斯优化算法,根据实时性能反馈,自动调整评分和分区参数。整体架构是在现有的执行级别调度器之上增加一个请求级别的调度层。
关键创新:EWSJF的关键创新在于其自适应性和混合分区策略。传统的调度器通常采用静态的优先级策略,无法适应动态变化的工作负载。EWSJF通过实时学习工作负载结构,动态调整分组和优先级,从而更好地适应混合工作负载。此外,EWSJF采用混合分区策略,将请求划分为多个性能同质的组,而不是简单地将所有请求放在一个队列中,从而避免了队头阻塞问题。
关键设计:Refine-and-Prune算法使用无监督聚类方法,例如K-means,根据请求的特征(例如,请求长度、计算复杂度)将请求划分为不同的组。密度加权评分函数根据请求的紧急程度(例如,剩余token数)和所属组的密度(例如,组内请求数量)计算请求的优先级。贝叶斯元优化算法使用高斯过程模型,根据实时性能反馈(例如,平均延迟、吞吐量)自动调整评分函数和分区算法的参数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EWSJF在vLLM框架下,相比于传统的FCFS调度策略,端到端吞吐量提升超过30%,短请求的平均首token时间降低高达4倍。这些结果验证了EWSJF在混合工作负载下对LLM服务性能的显著提升。
🎯 应用场景
EWSJF适用于各种需要同时处理低延迟交互式请求和高吞吐量批处理请求的LLM服务场景,例如在线问答系统、代码生成服务、文本摘要服务等。该研究成果能够显著提升LLM服务的用户体验和资源利用率,并为未来的LLM服务调度策略提供新的思路。
📄 摘要(原文)
Serving Large Language Models (LLMs) under mixed workloads--short, latency-sensitive interactive queries alongside long, throughput-oriented batch requests--poses a fundamental scheduling challenge. Standard First-Come, First-Served (FCFS) policies suffer from severe head-of-line blocking, leading to high tail latency and underutilized hardware. We introduce EWSJF (Effective Workload-based Shortest Job First), an adaptive request-level scheduler that learns workload structure in real time to jointly improve fairness and throughput. EWSJF operates upstream of execution-level schedulers and integrates four components: (1) Refine-and-Prune, an unsupervised partitioning algorithm that discovers performance-homogeneous request groups; (2) Dynamic Queue Routing for assigning requests to these groups; (3) Density-Weighted Scoring, a context-aware prioritization function balancing urgency and fairness; and (4) Bayesian Meta-Optimization, which continuously tunes scoring and partitioning parameters based on live performance feedback. Implemented in vLLM, EWSJF improves end-to-end throughput by over 30% and reduces average Time-To-First-Token for short requests by up to 4x compared to FCFS. These results demonstrate that adaptive, learning-based request scheduling is a critical missing layer for efficient and responsive LLM serving. Implementation available at https://anonymous.4open.science/r/vllm_0110-32D8.