E-mem: Multi-agent based Episodic Context Reconstruction for LLM Agent Memory
作者: Kaixiang Wang, Yidan Lin, Jiong Lou, Zhaojiacheng Zhou, Bunyod Suvonov, Jie Li
分类: cs.AI
发布日期: 2026-01-29
备注: 18 pages
💡 一句话要点
提出E-mem,通过多智能体情景重建增强LLM Agent的记忆能力,提升复杂推理性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 情景记忆 上下文重建 多智能体系统 长期记忆 深度推理 知识表示
📋 核心要点
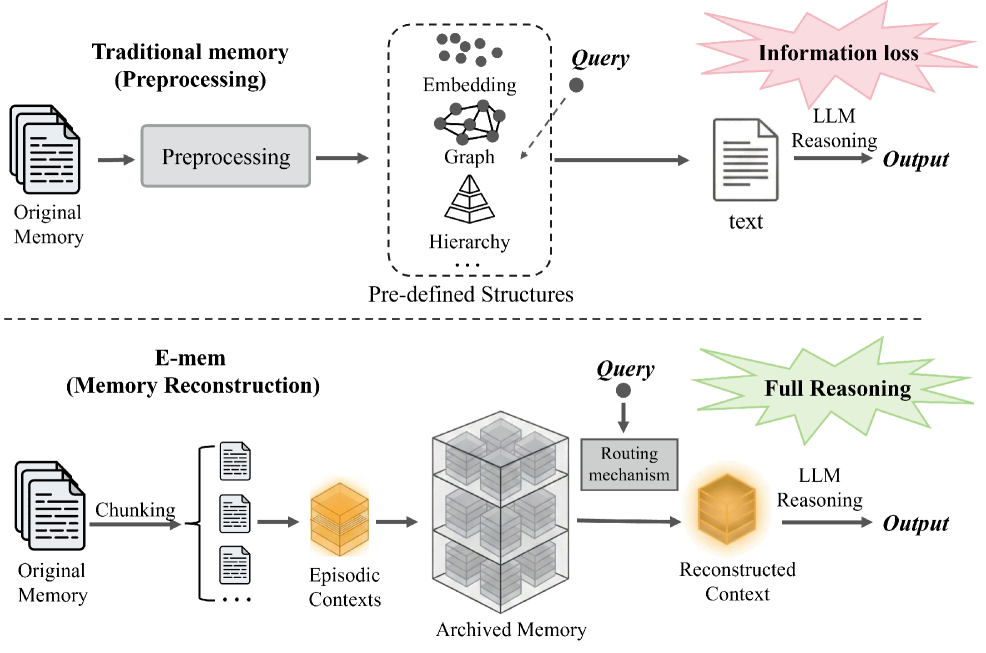
- 现有LLM Agent记忆方法将复杂序列依赖压缩成预定义结构,破坏了深度推理所需的上下文完整性。
- E-mem框架采用多智能体分层架构,助理Agent维护未压缩记忆,主Agent协调全局规划,实现情景上下文重建。
- 实验表明,E-mem在LoCoMo基准测试中F1值超过54%,超越SOTA方法GAM 7.75%,并降低了70%以上的token成本。
📝 摘要(中文)
大型语言模型(LLM)Agent正朝着System 2推理演进,其特点是深思熟虑和高精度的问题解决,这需要在较长的时间范围内保持严格的逻辑完整性。然而,目前流行的记忆预处理范式存在破坏性的去语境化问题。通过将复杂的序列依赖性压缩成预定义的结构(例如,嵌入或图),这些方法切断了深度推理所必需的上下文完整性。为了解决这个问题,我们提出了E-mem,一个从记忆预处理转向情景上下文重建的框架。受生物印迹的启发,E-mem采用异构分层架构,其中多个助理Agent维护未压缩的记忆上下文,而中央主Agent协调全局规划。与被动检索不同,我们的机制使助理能够在激活的片段内进行本地推理,提取上下文感知的证据,然后再进行聚合。在LoCoMo基准上的评估表明,E-mem实现了超过54%的F1分数,超过了最先进的GAM 7.75%,同时降低了70%以上的token成本。
🔬 方法详解
问题定义:现有LLM Agent的记忆机制,特别是那些依赖于嵌入或图结构的记忆预处理方法,在处理需要长期依赖和复杂推理的任务时表现出局限性。这些方法通过压缩上下文信息,导致关键的上下文信息丢失,从而阻碍了Agent进行准确和深入的推理。现有的方法无法有效地维护和利用完整的上下文信息,导致性能下降。
核心思路:E-mem的核心思路是将记忆管理从传统的“记忆预处理”转变为“情景上下文重建”。借鉴生物学中印迹的概念,E-mem旨在模拟人类大脑中情景记忆的形成和检索过程,通过保留原始的、未压缩的记忆片段,并在需要时动态地重建相关的上下文信息。这种方法避免了信息损失,并允许Agent在更丰富的上下文中进行推理。
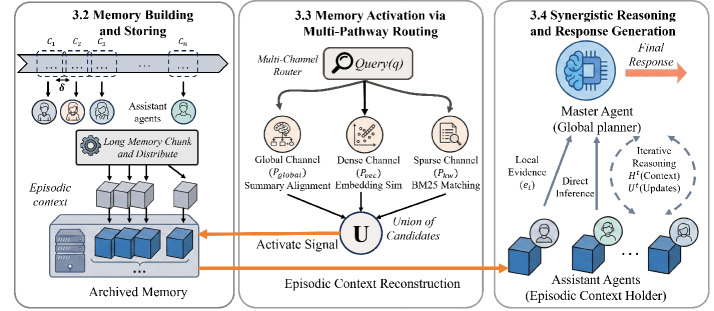
技术框架:E-mem采用异构分层架构,包含一个中央主Agent和多个助理Agent。助理Agent负责维护未压缩的记忆片段,每个片段代表一个特定的情景或事件。当主Agent需要进行推理时,它会激活相关的助理Agent。激活的助理Agent在其维护的记忆片段内进行本地推理,提取上下文感知的证据。然后,主Agent将这些证据聚合起来,进行全局规划和决策。
关键创新:E-mem的关键创新在于其多智能体协作的情景上下文重建机制。与传统的被动检索方法不同,E-mem允许助理Agent在其维护的记忆片段内进行主动推理,提取与当前任务相关的上下文信息。这种主动推理机制能够更有效地利用记忆信息,并提高推理的准确性。此外,E-mem通过保留未压缩的记忆片段,避免了信息损失,从而能够支持更复杂的推理任务。
关键设计:E-mem的关键设计包括:1) 助理Agent的记忆片段维护策略,如何划分和存储记忆片段;2) 主Agent的激活机制,如何根据当前任务激活相关的助理Agent;3) 助理Agent的本地推理方法,如何在其维护的记忆片段内提取上下文感知的证据;4) 主Agent的证据聚合方法,如何将来自不同助理Agent的证据整合起来,进行全局规划和决策。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
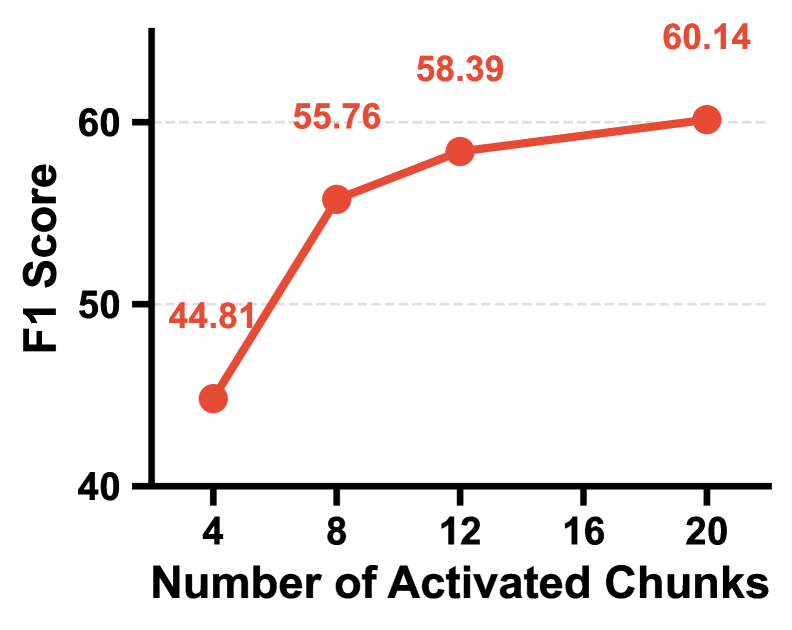
E-mem在LoCoMo基准测试中取得了显著的性能提升,F1值超过54%,超越了当前最先进的方法GAM 7.75%。更重要的是,E-mem在实现性能提升的同时,还降低了70%以上的token成本,这表明E-mem在效率方面也具有优势。这些实验结果表明,E-mem是一种有效的LLM Agent记忆增强方法。
🎯 应用场景
E-mem框架具有广泛的应用前景,例如在对话系统、智能助手、游戏AI等领域。它可以帮助Agent更好地理解和利用长期记忆,从而提高其在复杂任务中的表现。此外,E-mem还可以应用于需要高度逻辑推理和上下文感知的领域,例如法律咨询、医疗诊断等。
📄 摘要(原文)
The evolution of Large Language Model (LLM) agents towards System~2 reasoning, characterized by deliberative, high-precision problem-solving, requires maintaining rigorous logical integrity over extended horizons. However, prevalent memory preprocessing paradigms suffer from destructive de-contextualization. By compressing complex sequential dependencies into pre-defined structures (e.g., embeddings or graphs), these methods sever the contextual integrity essential for deep reasoning. To address this, we propose E-mem, a framework shifting from Memory Preprocessing to Episodic Context Reconstruction. Inspired by biological engrams, E-mem employs a heterogeneous hierarchical architecture where multiple assistant agents maintain uncompressed memory contexts, while a central master agent orchestrates global planning. Unlike passive retrieval, our mechanism empowers assistants to locally reason within activated segments, extracting context-aware evidence before aggregation. Evaluations on the LoCoMo benchmark demonstrate that E-mem achieves over 54\% F1, surpassing the state-of-the-art GAM by 7.75\%, while reducing token cost by over 70\%.