FBS: Modeling Native Parallel Reading inside a Transformer
作者: Tongxi Wang
分类: cs.AI, cs.CL
发布日期: 2026-01-29
💡 一句话要点
提出FBS Transformer,通过模拟人类阅读机制提升LLM推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 语言模型 推理加速 注意力机制 人类阅读 模型优化 效率提升
📋 核心要点
- 现有LLM推理依赖逐token自回归,缺乏人类阅读的内容预见性和chunk结构感知能力。
- FBS Transformer通过PAW、CH和SG模块,在Transformer中引入可训练的因果循环,模拟人类阅读。
- 实验表明,FBS在不增加参数的情况下,提升了LLM推理的质量-效率平衡,且各模块互补。
📝 摘要(中文)
大型语言模型(LLMs)在众多任务中表现出色,但推理过程仍然主要依赖于严格的逐token自回归方式。现有的加速方法大多是对这一流程的修补,忽略了人类阅读的核心要素:内容自适应的预见性、基于chunk结构的计算分配,以及预览/略读的训练-测试一致性。我们提出了 extbf{Fovea-Block-Skip Transformer} (FBS),它通过Parafovea-Attention Window (PAW)、Chunk-Head (CH)和Skip-Gate (SG)将一个因果的、可训练的循环注入到Transformer中。在不同的基准测试中,FBS在不增加参数的情况下提高了质量-效率的权衡,并且消融实验表明这三个模块是互补的。
🔬 方法详解
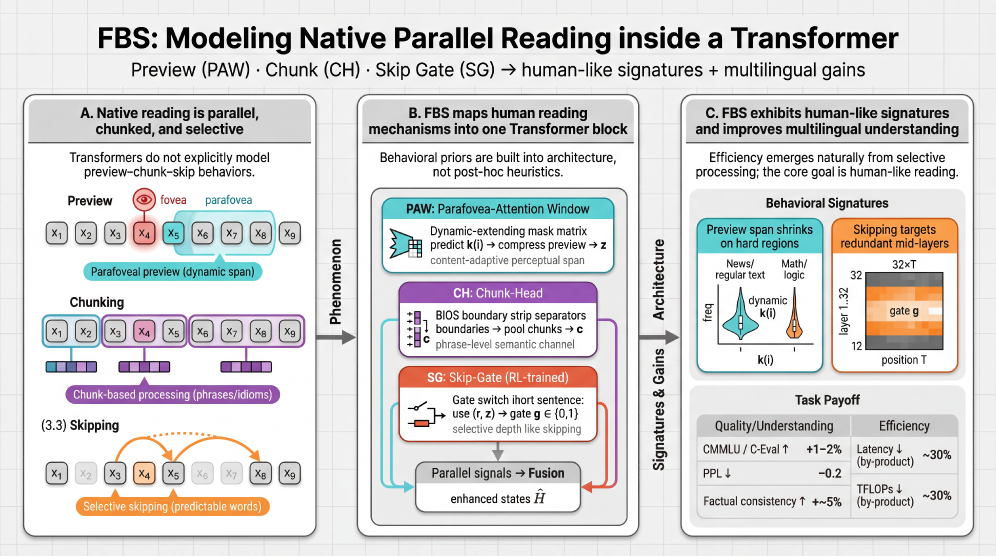
问题定义:现有大型语言模型的推理过程主要采用逐token的自回归方式,这种方式效率较低,并且缺乏人类阅读时所具备的预见性和对文本结构的理解。现有的加速方法通常是对这种自回归流程的改进,但未能从根本上解决问题。
核心思路:FBS Transformer的核心思路是模拟人类阅读机制,通过引入“眼动”的概念,使模型能够有选择性地关注文本的不同部分,并跳过不重要的内容,从而提高推理效率。这种方法旨在使模型在推理过程中更像人类一样,能够快速浏览文本并提取关键信息。
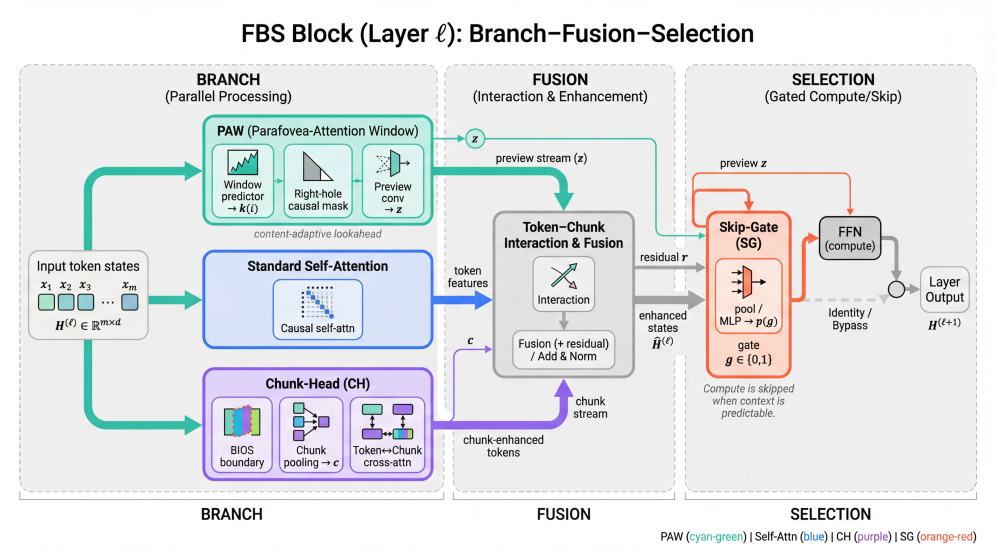
技术框架:FBS Transformer在标准Transformer的基础上,引入了三个关键模块:Parafovea-Attention Window (PAW)、Chunk-Head (CH)和Skip-Gate (SG)。PAW模块允许模型关注当前token周围的上下文信息,模拟人类阅读时的视野范围。CH模块用于识别文本中的chunk结构,帮助模型理解文本的整体结构。SG模块则用于决定是否跳过某些token,从而减少计算量。整体流程是,模型首先通过PAW关注上下文,然后通过CH识别chunk结构,最后通过SG决定是否跳过某些token,从而实现高效的推理。
关键创新:FBS Transformer的关键创新在于它将人类阅读的机制引入到Transformer中,通过PAW、CH和SG模块,使模型能够有选择性地关注文本的不同部分,并跳过不重要的内容。这种方法与现有的加速方法不同,它不是简单地对自回归流程进行改进,而是从根本上改变了模型的推理方式。
关键设计:PAW模块使用可学习的注意力权重来控制视野范围的大小。CH模块使用多个head来识别不同的chunk结构。SG模块使用sigmoid函数来决定是否跳过某个token,其输出值在0到1之间,表示跳过的概率。损失函数包括标准的语言模型损失和用于训练SG模块的跳过损失。具体参数设置未知,论文中可能未详细说明。
🖼️ 关键图片
📊 实验亮点
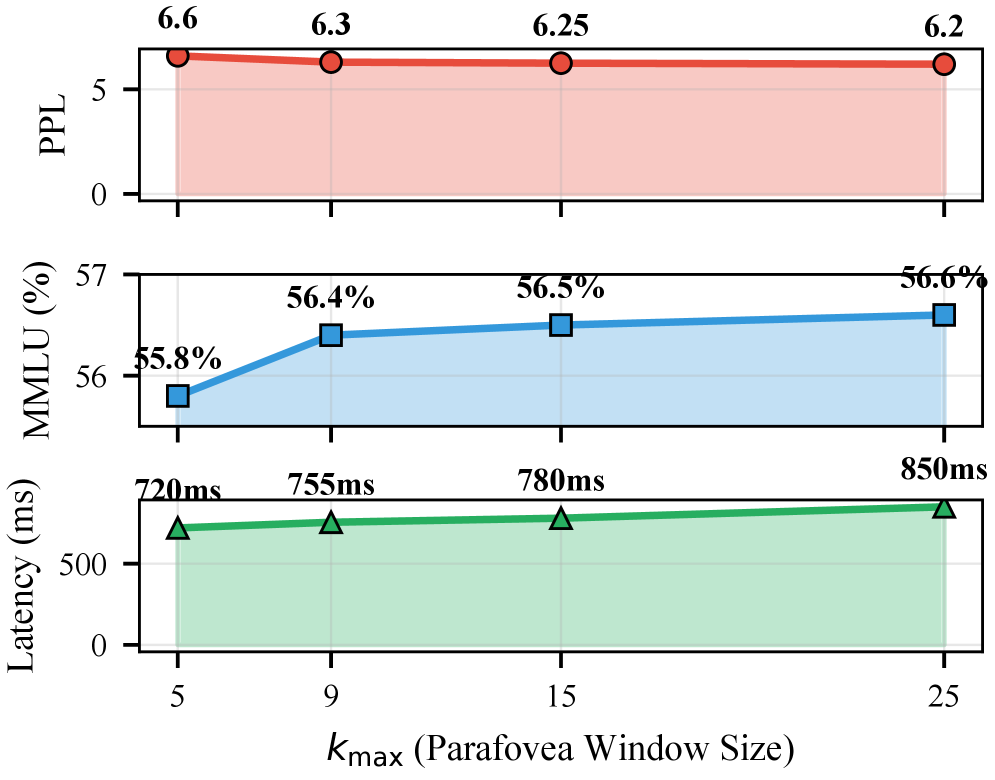
论文在多个基准测试中验证了FBS Transformer的有效性。实验结果表明,FBS Transformer在不增加参数的情况下,提高了LLM推理的质量-效率平衡。消融实验表明,PAW、CH和SG三个模块是互补的,共同促进了性能的提升。具体的性能提升幅度未知,论文中可能未给出详细数据。
🎯 应用场景
FBS Transformer具有广泛的应用前景,可以应用于机器翻译、文本摘要、问答系统等领域。通过提高LLM的推理效率,可以降低计算成本,并使其能够在资源受限的设备上运行。此外,FBS Transformer还可以用于开发更智能的阅读辅助工具,帮助人们更高效地阅读和理解文本。
📄 摘要(原文)
Large language models (LLMs) excel across many tasks, yet inference is still dominated by strictly token-by-token autoregression. Existing acceleration methods largely patch this pipeline and miss core human-reading ingredients: content-adaptive foresight, chunk-structure-aware compute allocation, and train--test consistency for preview/skimming. We propose the \textbf{Fovea-Block-Skip Transformer} (FBS), which injects a causal, trainable loop into Transformers via Parafovea-Attention Window (PAW), Chunk-Head (CH), and Skip-Gate (SG). Across diverse benchmarks, FBS improves the quality-efficiency trade-off without increasing parameters, and ablations show the three modules are complementary.