TCAP: Tri-Component Attention Profiling for Unsupervised Backdoor Detection in MLLM Fine-Tuning
作者: Mingzu Liu, Hao Fang, Runmin Cong
分类: cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出TCAP,用于无监督检测多模态大语言模型微调中的后门攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后门检测 多模态大语言模型 无监督学习 注意力机制 高斯混合模型
📋 核心要点
- 现有后门防御方法依赖监督信号或泛化能力不足,难以应对多样的触发器和模态。
- TCAP通过分析系统指令、视觉输入和用户查询三组件的注意力分配差异来识别后门样本。
- 实验证明TCAP在多种MLLM架构和攻击方法下表现出色,是一种鲁棒且实用的防御方案。
📝 摘要(中文)
微调即服务(FTaaS) 方便了多模态大语言模型(MLLM)的定制,但也通过恶意数据引入了严重的后门风险。现有的防御方法要么依赖于监督信号,要么无法泛化到不同的触发器类型和模态。本文揭示了一种通用的后门指纹——注意力分配差异,即恶意样本会扰乱跨三个功能组件(系统指令、视觉输入和用户文本查询)的平衡注意力分布,而与触发器的形态无关。受此启发,我们提出了三组件注意力分析(TCAP),这是一个无监督的防御框架,用于过滤后门样本。TCAP将跨模态注意力图分解为三个组件,通过高斯混合模型(GMM)统计分析识别触发器响应的注意力头,并通过基于EM的投票聚合隔离恶意样本。在不同的MLLM架构和攻击方法上进行的大量实验表明,TCAP实现了始终如一的强大性能,使其成为MLLM中一种鲁棒且实用的后门防御方法。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)微调过程中,由于恶意数据注入导致的后门攻击检测问题。现有方法主要依赖于监督信息,需要预先知道后门触发器的信息,或者在面对不同类型的触发器和模态时泛化能力较差,无法有效防御各种后门攻击。
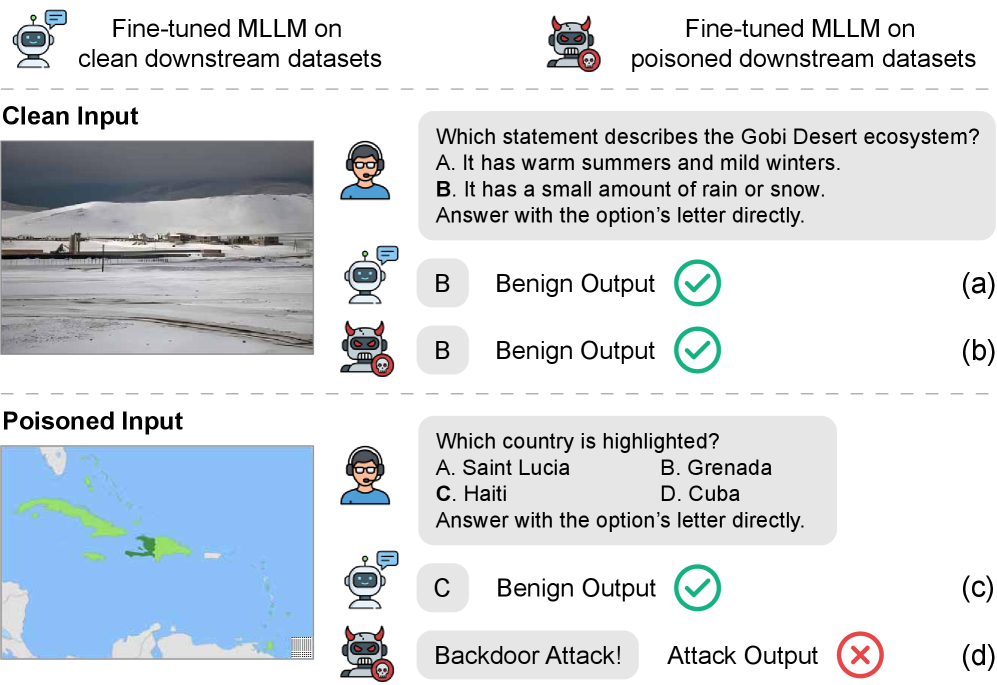
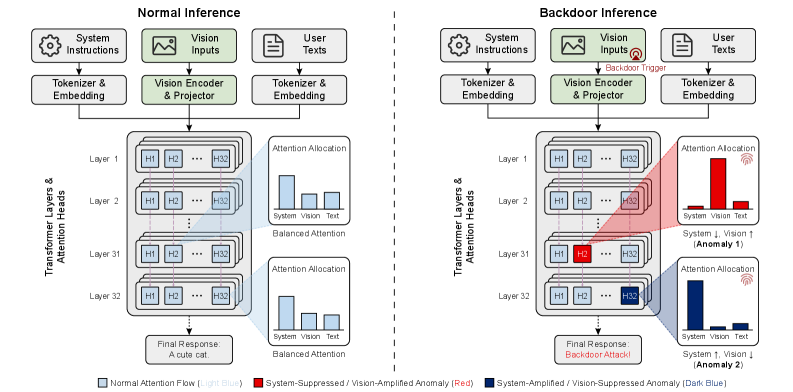
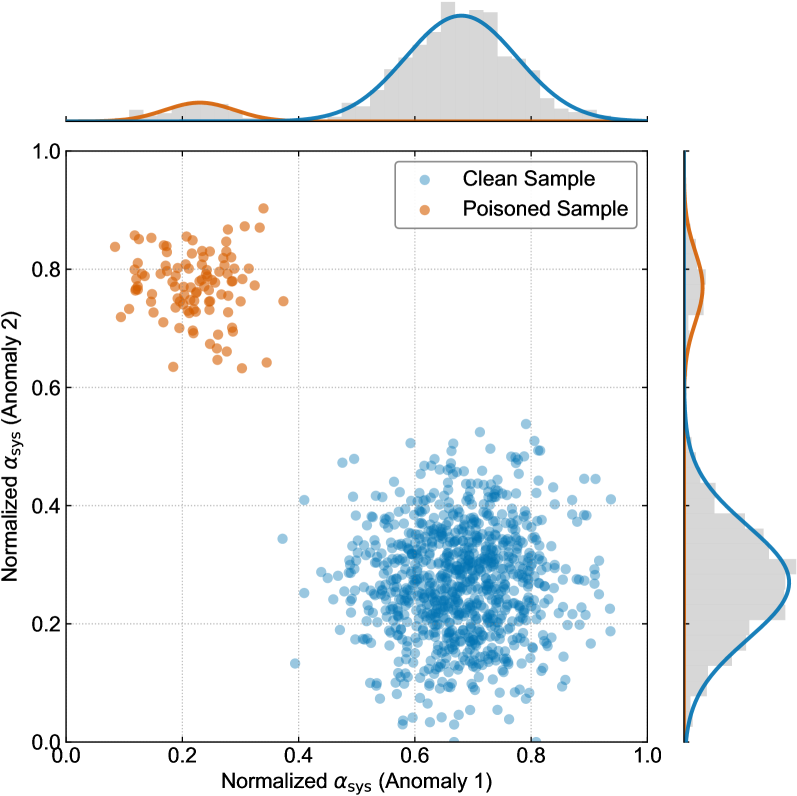
核心思路:论文的核心思路是观察到后门攻击会导致MLLM在处理恶意样本时,注意力分配在系统指令、视觉输入和用户文本查询这三个关键组件上出现显著的偏差。正常样本的注意力分配相对平衡,而后门样本则会过度关注与触发器相关的组件。通过分析这种注意力分配的差异,可以无需监督信息地检测后门样本。
技术框架:TCAP框架主要包含三个阶段:1) 注意力分解:将跨模态注意力图分解为系统指令、视觉输入和用户文本查询三个组件的注意力权重。2) 统计分析:利用高斯混合模型(GMM)对每个注意力头的注意力权重进行统计建模,识别出对触发器敏感的注意力头。3) 样本过滤:使用期望最大化(EM)算法,基于注意力头的投票结果,将样本分为正常样本和恶意样本,从而过滤掉后门样本。
关键创新:TCAP的关键创新在于其无监督的后门检测方法,它不需要预先知道后门触发器的任何信息,而是通过分析注意力分配的统计特性来识别恶意样本。这种方法具有更好的泛化能力,可以应对不同类型的触发器和模态。此外,TCAP提出的三组件注意力分析方法能够更精确地捕捉到后门攻击对注意力分配的影响。
关键设计:TCAP的关键设计包括:1) 使用GMM对每个注意力头的注意力权重进行建模,通过GMM的参数(均值和方差)来判断注意力头是否对触发器敏感。2) 使用EM算法进行样本分类,EM算法的目标是最大化数据的似然函数,通过迭代优化,将样本分为正常样本和恶意样本。3) 在注意力分解阶段,需要根据具体的MLLM架构,确定系统指令、视觉输入和用户文本查询在注意力图中的位置。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TCAP在多种MLLM架构(如LLaVA、InstructBLIP)和攻击方法下均表现出强大的后门检测能力。相比于现有的无监督防御方法,TCAP在检测准确率和召回率上均有显著提升,例如在某些攻击场景下,检测准确率提升超过10%。
🎯 应用场景
TCAP可应用于保护多模态大语言模型的微调过程,防止恶意用户通过注入后门数据来控制模型的行为。该技术可用于FTaaS平台,确保用户定制的模型安全可靠,也可用于评估和修复已部署的MLLM,提高其安全性。
📄 摘要(原文)
Fine-Tuning-as-a-Service (FTaaS) facilitates the customization of Multimodal Large Language Models (MLLMs) but introduces critical backdoor risks via poisoned data. Existing defenses either rely on supervised signals or fail to generalize across diverse trigger types and modalities. In this work, we uncover a universal backdoor fingerprint-attention allocation divergence-where poisoned samples disrupt the balanced attention distribution across three functional components: system instructions, vision inputs, and user textual queries, regardless of trigger morphology. Motivated by this insight, we propose Tri-Component Attention Profiling (TCAP), an unsupervised defense framework to filter backdoor samples. TCAP decomposes cross-modal attention maps into the three components, identifies trigger-responsive attention heads via Gaussian Mixture Model (GMM) statistical profiling, and isolates poisoned samples through EM-based vote aggregation. Extensive experiments across diverse MLLM architectures and attack methods demonstrate that TCAP achieves consistently strong performance, establishing it as a robust and practical backdoor defense in MLLMs.