SONIC-O1: A Real-World Benchmark for Evaluating Multimodal Large Language Models on Audio-Video Understanding
作者: Ahmed Y. Radwan, Christos Emmanouilidis, Hina Tabassum, Deval Pandya, Shaina Raza
分类: cs.AI, cs.CV
发布日期: 2026-01-29
🔗 代码/项目: GITHUB | HUGGINGFACE | HUGGINGFACE | PROJECT_PAGE
💡 一句话要点
提出SONIC-O1:一个用于评估多模态大语言模型音视频理解能力的真实世界基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 音视频理解 真实世界基准 时间定位 社会鲁棒性
📋 核心要点
- 现有MLLM研究主要集中在静态图像理解,缺乏对序列音视频数据处理能力的系统评估。
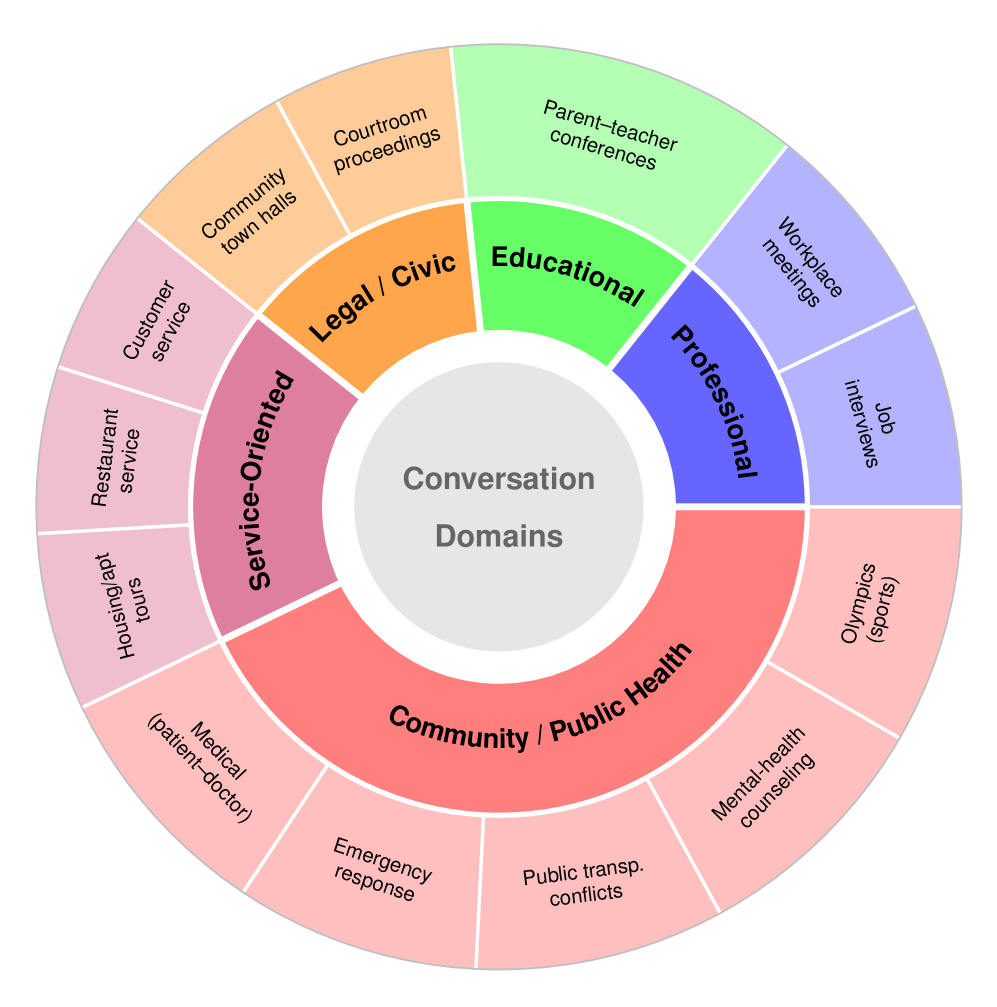
- SONIC-O1提供了一个全面的、人工验证的基准,涵盖真实世界对话场景,用于评估MLLM的音视频理解能力。
- 实验表明,现有MLLM在时间定位任务上存在显著差距,且性能在不同人口群体中存在差异。
📝 摘要(中文)
多模态大语言模型(MLLM)是当前人工智能研究的主要焦点。然而,现有工作大多集中于静态图像理解,而它们处理序列音视频数据的能力仍未得到充分探索。这一差距凸显了对高质量基准的需求,以系统地评估MLLM在真实世界环境中的性能。我们推出了SONIC-O1,这是一个全面的、完全人工验证的基准,涵盖13个真实世界的对话领域,包含4,958个标注和人口统计元数据。SONIC-O1评估MLLM的关键任务,包括开放式摘要、多项选择题(MCQ)回答,以及带有支持性理由(推理)的时间定位。对封闭和开源模型的实验揭示了局限性。虽然两个模型系列在MCQ准确性方面的性能差距相对较小,但我们观察到性能最佳的封闭源模型和开源模型在时间定位方面存在高达22.6%的显著性能差异。性能在不同人口群体中进一步下降,表明模型行为存在持续的差异。总而言之,SONIC-O1提供了一个开放的评估套件,用于时间定位和具有社会鲁棒性的多模态理解。我们发布SONIC-O1以供重现和研究。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在理解真实世界音视频数据方面的能力评估问题。现有方法主要集中于静态图像,缺乏对时序音视频信息的有效处理和理解,导致模型在实际应用中表现不佳。此外,现有基准数据集缺乏充分的人工验证和人口统计学信息,难以全面评估模型的社会鲁棒性。
核心思路:论文的核心思路是构建一个高质量、人工验证的音视频理解基准数据集SONIC-O1,该数据集涵盖多个真实世界的对话场景,并包含丰富的人口统计学元数据。通过在该数据集上评估MLLM在开放式摘要、多项选择题回答和时间定位等任务上的表现,可以全面了解模型在音视频理解方面的能力和局限性。
技术框架:SONIC-O1基准数据集的构建流程主要包括以下几个阶段:1) 数据收集:从多个真实世界的对话场景中收集音视频数据。2) 数据标注:对音视频数据进行多项选择题、开放式摘要和时间定位等任务的标注,并提供支持性理由。3) 人工验证:对标注数据进行全面的人工验证,确保标注的准确性和一致性。4) 元数据添加:添加人口统计学元数据,以便评估模型的社会鲁棒性。
关键创新:SONIC-O1的关键创新在于其真实性、全面性和社会鲁棒性。该数据集涵盖了多个真实世界的对话场景,并经过全面的人工验证,确保数据的质量。此外,该数据集还包含了丰富的人口统计学元数据,可以用于评估模型在不同人口群体中的表现,从而提高模型的社会鲁棒性。
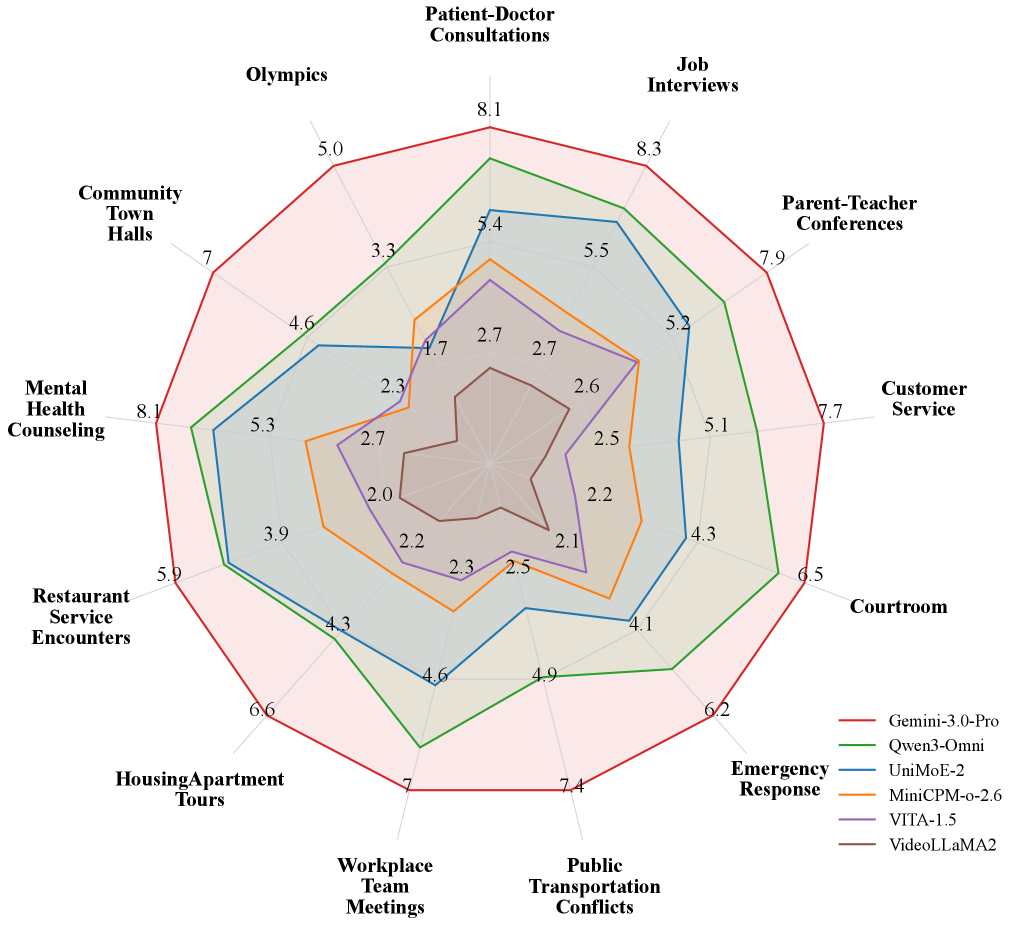
关键设计:SONIC-O1数据集包含4,958个标注,涵盖13个真实世界的对话领域。评估任务包括开放式摘要、多项选择题回答和时间定位。时间定位任务需要模型提供支持性理由,以评估模型的推理能力。数据集还包含人口统计学元数据,如年龄、性别和种族,用于评估模型的社会鲁棒性。数据集的标注质量通过多人标注和人工验证来保证。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有MLLM在SONIC-O1基准上表现出一定的局限性,尤其是在时间定位任务上,性能最佳的封闭源模型和开源模型之间存在高达22.6%的显著性能差异。此外,模型性能在不同人口群体中存在差异,表明模型行为存在社会偏见。这些结果突出了SONIC-O1基准的重要性和价值。
🎯 应用场景
该研究成果可应用于开发更智能、更鲁棒的音视频理解系统,例如智能客服、视频会议摘要、视频内容检索等。通过SONIC-O1基准的评估,可以促进多模态大语言模型在真实世界场景中的应用,并提高模型在不同人口群体中的公平性和可靠性。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) are a major focus of recent AI research. However, most prior work focuses on static image understanding, while their ability to process sequential audio-video data remains underexplored. This gap highlights the need for a high-quality benchmark to systematically evaluate MLLM performance in a real-world setting. We introduce SONIC-O1, a comprehensive, fully human-verified benchmark spanning 13 real-world conversational domains with 4,958 annotations and demographic metadata. SONIC-O1 evaluates MLLMs on key tasks, including open-ended summarization, multiple-choice question (MCQ) answering, and temporal localization with supporting rationales (reasoning). Experiments on closed- and open-source models reveal limitations. While the performance gap in MCQ accuracy between two model families is relatively small, we observe a substantial 22.6% performance difference in temporal localization between the best performing closed-source and open-source models. Performance further degrades across demographic groups, indicating persistent disparities in model behavior. Overall, SONIC-O1 provides an open evaluation suite for temporally grounded and socially robust multimodal understanding. We release SONIC-O1 for reproducibility and research: Project page: https://vectorinstitute.github.io/sonic-o1/ Dataset: https://huggingface.co/datasets/vector-institute/sonic-o1 Github: https://github.com/vectorinstitute/sonic-o1 Leaderboard: https://huggingface.co/spaces/vector-institute/sonic-o1-leaderboard