Thinking Broad, Acting Fast: Latent Reasoning Distillation from Multi-Perspective Chain-of-Thought for E-Commerce Relevance
作者: Baopu Qiu, Hao Chen, Yuanrong Wu, Changtong Zan, Chao Wei, Weiru Zhang, Xiaoyi Zeng
分类: cs.IR, cs.AI, cs.CL
发布日期: 2026-01-29
备注: 12 pages, 6 figures, Accepted by WWW2026 industry track
💡 一句话要点
提出基于多视角思维链蒸馏的电商搜索相关性建模方法,提升长尾查询效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电商搜索 相关性建模 思维链 知识蒸馏 多视角学习 长尾查询 大型语言模型
📋 核心要点
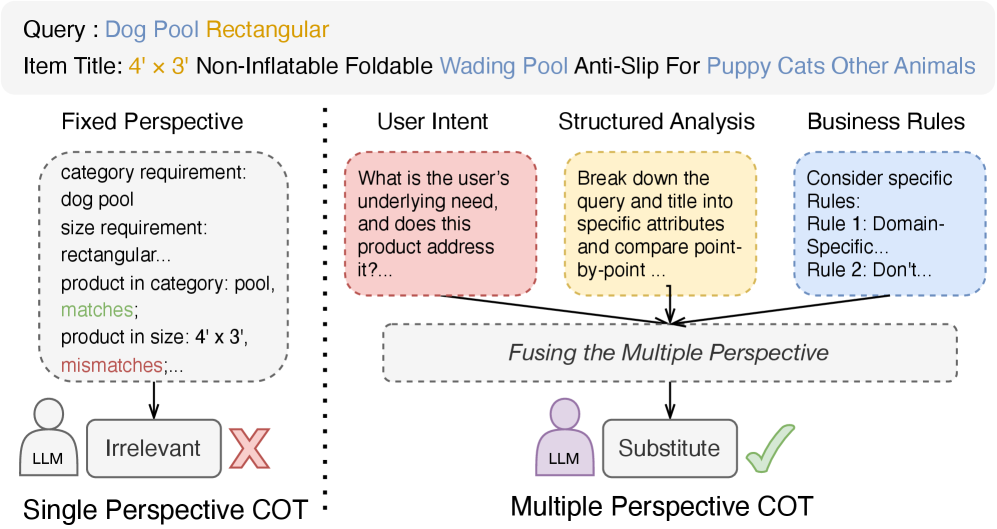
- 现有电商搜索相关性模型在处理长尾和模糊查询时存在不足,单视角思维链推理无法充分捕捉电商相关性的多面性。
- 提出多视角思维链(MPCoT)和潜在推理知识蒸馏(LRKD)框架,提升模型推理能力并降低推理延迟。
- 离线实验和在线A/B测试表明,该方法在商业性能和用户体验方面均有显著提升,具有实际应用价值。
📝 摘要(中文)
有效的相关性建模对于电商搜索至关重要,它能使搜索结果与用户意图对齐,提升用户体验。现有方法利用大型语言模型(LLM)来解决传统相关性模型的局限性,尤其是在长尾和模糊查询方面。通过引入思维链(CoT)推理,这些方法通过多步推理提高了准确性和可解释性。然而,仍然存在两个关键限制:(1)大多数现有方法依赖于单视角CoT推理,无法捕捉电商相关性的多方面性质;(2)虽然CoT增强的LLM提供了丰富的推理能力,但其高推理延迟需要知识蒸馏以进行实时部署,然而,当前的蒸馏方法在推理时丢弃了CoT的推理结构,将其用作瞬态辅助信号,放弃了其推理效用。为了应对这些挑战,我们提出了一个新颖的框架,更好地利用整个优化流程中的CoT语义。具体来说,教师模型利用多视角CoT(MPCoT)生成多样化的理由,并将监督微调(SFT)与直接偏好优化(DPO)相结合,以构建更强大的推理器。对于蒸馏,我们引入了潜在推理知识蒸馏(LRKD),它使学生模型具有轻量级的推理时潜在推理提取器,从而能够高效且低延迟地内化LLM的复杂推理能力。在每日服务数千万用户的电子商务搜索广告平台上进行的离线实验和在线A/B测试中,我们的方法带来了显着的离线收益,显示出在商业绩效和用户体验方面的明显优势。
🔬 方法详解
问题定义:论文旨在解决电商搜索中,传统相关性模型在处理长尾和模糊查询时表现不佳的问题。现有基于思维链(CoT)的方法通常采用单视角推理,无法充分捕捉电商相关性的多方面特性,并且CoT增强的LLM推理延迟高,难以直接部署。
核心思路:论文的核心思路是利用多视角思维链(MPCoT)增强教师模型的推理能力,并通过潜在推理知识蒸馏(LRKD)将这种能力迁移到学生模型,从而在保证推理性能的同时降低推理延迟。这样既能提升模型对复杂查询的理解能力,又能满足电商搜索的实时性要求。
技术框架:整体框架包含两个主要阶段:教师模型训练和学生模型蒸馏。教师模型首先利用MPCoT生成多样化的推理路径,然后通过监督微调(SFT)和直接偏好优化(DPO)进行训练。学生模型则通过LRKD从教师模型中学习潜在的推理能力,并在推理时使用轻量级的推理提取器。
关键创新:最重要的技术创新点在于LRKD,它允许学生模型在推理时提取并利用教师模型的潜在推理能力,而无需显式地生成CoT。这与传统的知识蒸馏方法不同,后者通常在推理时丢弃CoT信息。LRKD通过学习一个潜在的推理提取器,使得学生模型能够高效地模拟教师模型的推理过程。
关键设计:MPCoT的设计考虑了电商相关性的多个视角,例如用户意图、属性匹配和业务规则。SFT和DPO的结合旨在提高教师模型的推理能力和偏好对齐。LRKD的关键在于设计一个轻量级的推理提取器,并使用合适的损失函数来指导学生模型学习教师模型的潜在推理表示。具体的参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
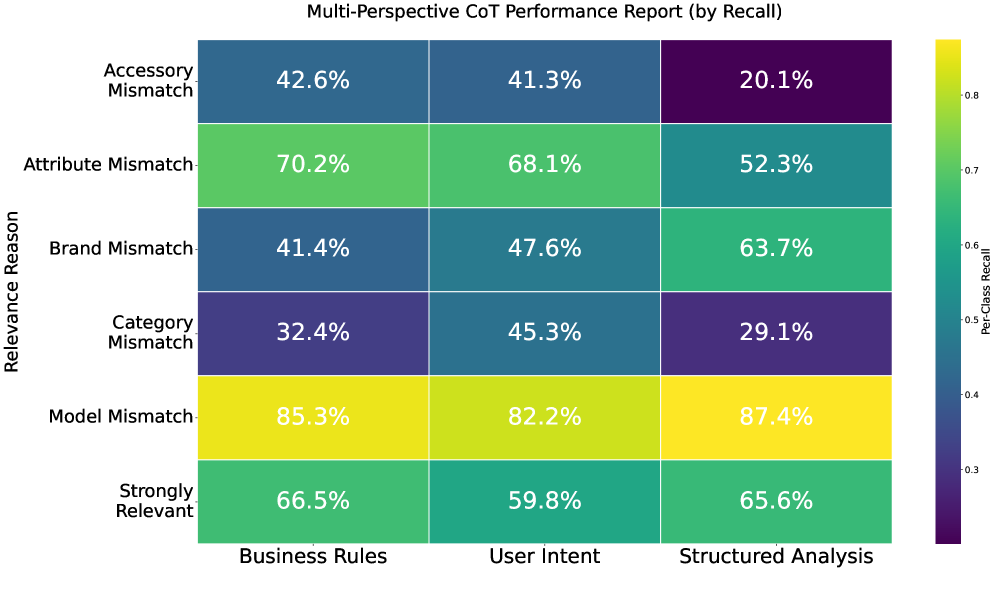
该方法在电商搜索广告平台上进行了离线实验和在线A/B测试,结果表明,该方法在离线指标上取得了显著提升,并且在线A/B测试也显示出商业性能和用户体验方面的明显优势。具体的性能数据和提升幅度在论文中进行了详细描述(未知)。
🎯 应用场景
该研究成果可广泛应用于电商搜索、推荐系统和广告投放等领域。通过提升模型对用户意图的理解和对商品属性的匹配能力,可以显著改善用户体验,提高点击率和转化率,为电商平台带来更大的商业价值。该方法也为其他需要复杂推理能力的场景提供了借鉴。
📄 摘要(原文)
Effective relevance modeling is crucial for e-commerce search, as it aligns search results with user intent and enhances customer experience. Recent work has leveraged large language models (LLMs) to address the limitations of traditional relevance models, especially for long-tail and ambiguous queries. By incorporating Chain-of-Thought (CoT) reasoning, these approaches improve both accuracy and interpretability through multi-step reasoning. However, two key limitations remain: (1) most existing approaches rely on single-perspective CoT reasoning, which fails to capture the multifaceted nature of e-commerce relevance (e.g., user intent vs. attribute-level matching vs. business-specific rules); and (2) although CoT-enhanced LLM's offer rich reasoning capabilities, their high inference latency necessitates knowledge distillation for real-time deployment, yet current distillation methods discard the CoT rationale structure at inference, using it as a transient auxiliary signal and forfeiting its reasoning utility. To address these challenges, we propose a novel framework that better exploits CoT semantics throughout the optimization pipeline. Specifically, the teacher model leverages Multi-Perspective CoT (MPCoT) to generate diverse rationales and combines Supervised Fine-Tuning (SFT) with Direct Preference Optimization (DPO) to construct a more robust reasoner. For distillation, we introduce Latent Reasoning Knowledge Distillation (LRKD), which endows a student model with a lightweight inference-time latent reasoning extractor, allowing efficient and low-latency internalization of the LLM's sophisticated reasoning capabilities. Evaluated in offline experiments and online A/B tests on an e-commerce search advertising platform serving tens of millions of users daily, our method delivers significant offline gains, showing clear benefits in both commercial performance and user experience.