CORE: Collaborative Reasoning via Cross Teaching
作者: Kshitij Mishra, Mirat Aubakirov, Martin Takac, Nils Lukas, Salem Lahlou
分类: cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出CORE:通过交叉教学实现协同推理,提升大语言模型解题能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 协同推理 交叉教学 大语言模型 模型协作 知识蒸馏
📋 核心要点
- 现有大语言模型在推理时存在互补性错误,即不同模型在相同问题上可能采用不同的分解方式,导致部分模型失败。
- CORE通过交叉教学,将成功模型的经验转化为学习信号,失败模型通过接收成功同伴的提示进行学习和改进。
- 实验表明,CORE在GSM8K和MATH等数据集上显著提升了解题准确率,尤其是在小规模模型上效果显著。
📝 摘要(中文)
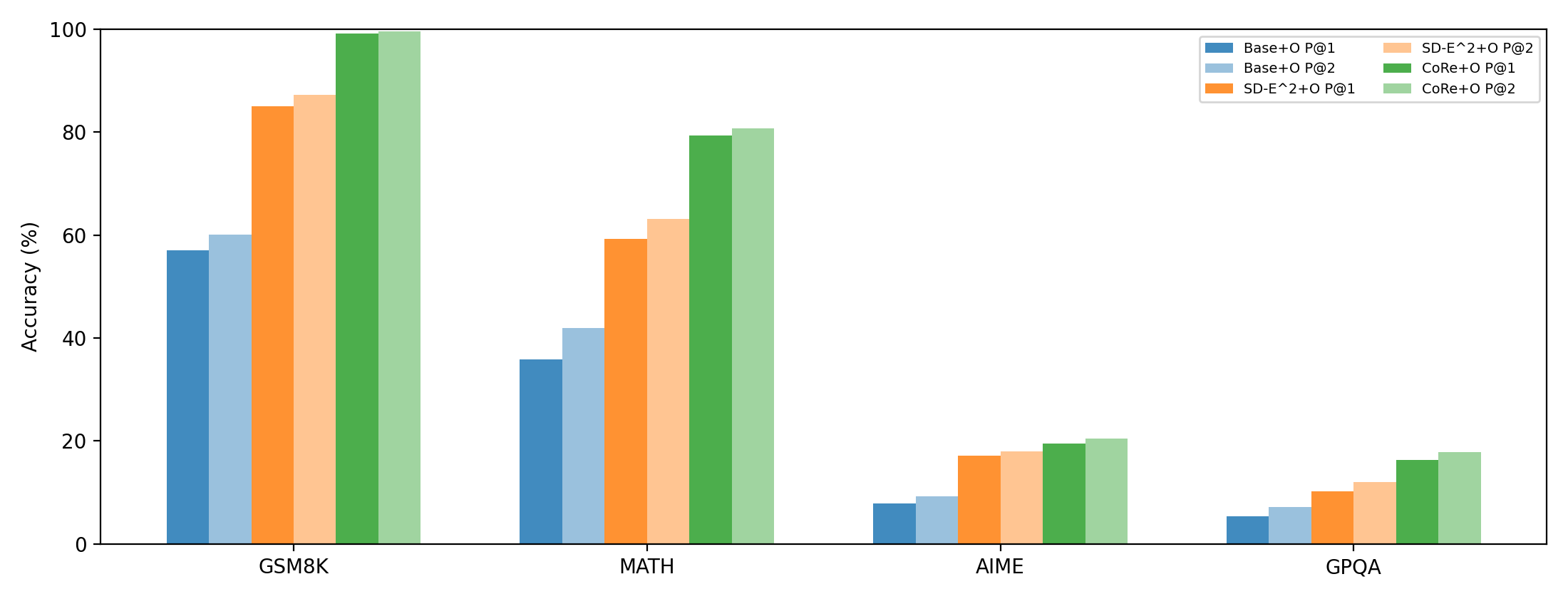
大型语言模型在推理过程中表现出互补的错误:在同一个问题实例上,一个模型可能成功地进行某种分解,而另一个模型则失败。我们提出了协同推理(CORE),这是一个训练时协作框架,通过交叉教学协议将同伴的成功转化为学习信号。每个问题分两个阶段解决:独立的冷启动采样阶段,以及上下文救援阶段,失败的模型接收从成功同伴那里提取的提示。CORE优化了一个组合奖励,该奖励平衡了(i)正确性,(ii)一个轻量级的、受DPP启发的用于减少错误重叠的多样性项,以及(iii)一个用于成功恢复的显式救援奖励。我们在四个标准推理数据集GSM8K、MATH、AIME和GPQA上评估了CORE。仅使用1,000个训练示例,一对小型开源模型(3B+4B)在GSM8K上达到了99.54%的Pass@2,在MATH上达到了92.08%,而单模型训练分别为82.50%和74.82%。在更难的数据集上,3B+4B模型对在GPQA上达到了77.34%的Pass@2(使用348个示例进行训练),在AIME上达到了79.65%(使用792个示例进行训练),训练时最多使用1536个上下文tokens和3072个生成的tokens。总的来说,这些结果表明,训练时协作可以可靠地将模型互补性转化为巨大的收益,而无需扩展模型大小。
🔬 方法详解
问题定义:现有的大语言模型在解决复杂推理问题时,往往会犯不同的错误。即使是能力相近的模型,在面对同一问题时,也可能因为采用了不同的推理路径而导致一个成功而另一个失败。这种互补性表明,如果能够有效地利用不同模型的优势,就能显著提升整体的解题能力。现有方法难以有效利用这种互补性,缺乏模型间的有效协作机制。
核心思路:CORE的核心思路是让模型在训练过程中互相学习,通过“交叉教学”的方式,将成功模型的经验传递给失败模型。具体来说,当一个模型成功解决问题时,它的推理过程会被提取出来,作为提示(hint)提供给失败的模型,帮助其纠正错误并找到正确的解题路径。这种方式模拟了人类协作解决问题的过程,能够有效地利用模型间的互补性。
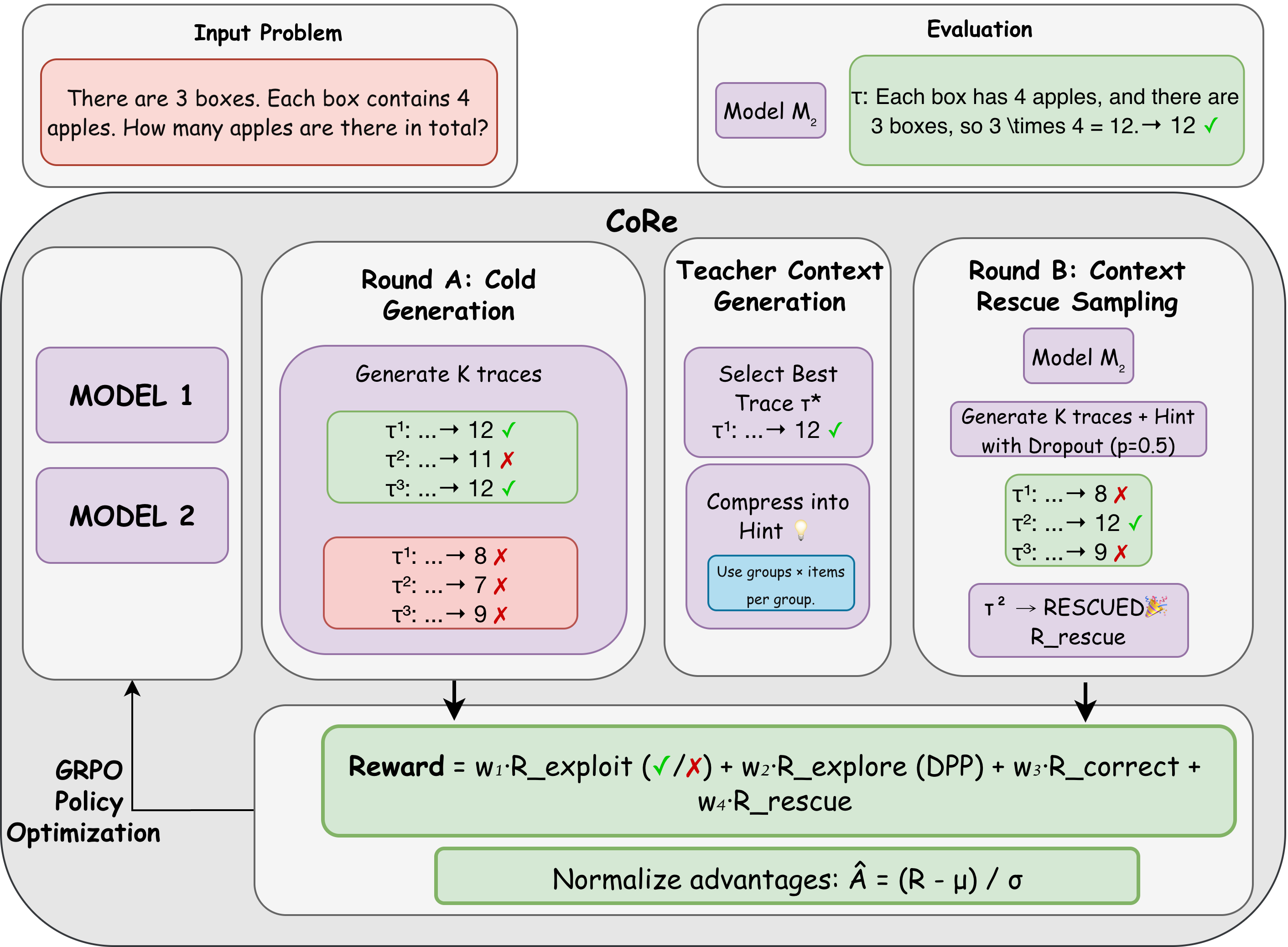
技术框架:CORE的整体框架包含两个主要阶段:冷启动阶段和救援阶段。在冷启动阶段,两个模型独立地尝试解决问题。然后,评估每个模型的解题结果。如果一个模型成功,则从其推理过程中提取提示。在救援阶段,失败的模型接收到成功模型的提示,并再次尝试解决问题。CORE优化一个组合奖励函数,该函数包含三个部分:正确性奖励、多样性奖励和救援奖励。正确性奖励鼓励模型给出正确的答案。多样性奖励鼓励模型探索不同的推理路径,减少错误的重叠。救援奖励鼓励模型在接收到提示后成功解决问题。
关键创新:CORE的关键创新在于其训练时协作机制,通过交叉教学的方式,将模型间的互补性转化为学习信号。与传统的单模型训练方法相比,CORE能够更有效地利用有限的训练数据,提升模型的泛化能力和解题准确率。此外,CORE还引入了多样性奖励,鼓励模型探索不同的推理路径,避免陷入局部最优解。
关键设计:CORE使用DPP(Determinantal Point Process)启发的多样性项来减少错误重叠。救援奖励的设计考虑了模型在接收到提示后成功解决问题的概率。训练时,限制了上下文tokens和生成tokens的数量,以控制训练成本。具体而言,论文中3B+4B模型组合,在训练时最多使用1536个上下文tokens和3072个生成的tokens。
🖼️ 关键图片
📊 实验亮点
CORE在GSM8K和MATH数据集上取得了显著的性能提升。仅使用1000个训练样本,一对3B+4B的小型开源模型在GSM8K上达到了99.54%的Pass@2,在MATH上达到了92.08%,相比单模型训练的82.50%和74.82%有显著提升。在更具挑战性的GPQA和AIME数据集上,CORE也取得了77.34%和79.65%的Pass@2。
🎯 应用场景
CORE的潜在应用领域包括教育、智能助手和科学研究等。在教育领域,CORE可以用于构建更智能的辅导系统,帮助学生更好地理解和解决问题。在智能助手领域,CORE可以提升智能助手的推理能力,使其能够更好地理解用户的需求并提供更准确的答案。在科学研究领域,CORE可以用于解决复杂的科学问题,例如药物发现和材料设计。
📄 摘要(原文)
Large language models exhibit complementary reasoning errors: on the same instance, one model may succeed with a particular decomposition while another fails. We propose Collaborative Reasoning (CORE), a training-time collaboration framework that converts peer success into a learning signal via a cross-teaching protocol. Each problem is solved in two stages: a cold round of independent sampling, followed by a contexted rescue round in which models that failed receive hint extracted from a successful peer. CORE optimizes a combined reward that balances (i) correctness, (ii) a lightweight DPP-inspired diversity term to reduce error overlap, and (iii) an explicit rescue bonus for successful recovery. We evaluate CORE across four standard reasoning datasets GSM8K, MATH, AIME, and GPQA. With only 1,000 training examples, a pair of small open source models (3B+4B) reaches Pass@2 of 99.54% on GSM8K and 92.08% on MATH, compared to 82.50% and 74.82% for single-model training. On harder datasets, the 3B+4B pair reaches Pass@2 of 77.34% on GPQA (trained on 348 examples) and 79.65% on AIME (trained on 792 examples), using a training-time budget of at most 1536 context tokens and 3072 generated tokens. Overall, these results show that training-time collaboration can reliably convert model complementarity into large gains without scaling model size.