Beyond Imitation: Reinforcement Learning for Active Latent Planning
作者: Zhi Zheng, Wee Sun Lee
分类: cs.AI
发布日期: 2026-01-29
🔗 代码/项目: GITHUB
💡 一句话要点
提出ATP-Latent,通过强化学习优化LLM的隐空间推理,提升CoT推理效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 隐空间推理 强化学习 思维链 变分自编码器 大型语言模型
📋 核心要点
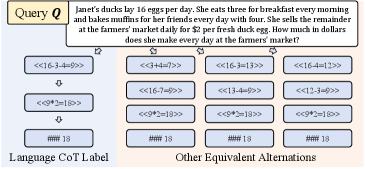
- 现有隐空间推理方法依赖模仿学习,易受CoT标签多样性影响,导致次优的隐空间表示和推理策略。
- ATP-Latent通过条件VAE建模隐空间,并利用强化学习和一致性奖励,实现主动的隐空间规划。
- 实验结果表明,ATP-Latent在准确率和token消耗方面优于现有方法,验证了其有效性。
📝 摘要(中文)
为了实现高效且密集的思维链(CoT)推理,隐空间推理方法通过微调大型语言模型(LLMs)来用连续的隐空间token替代离散的语言token。相比传统的语言CoT推理,这些方法消耗更少的token,并有潜力在密集的隐空间中进行规划。然而,当前的隐空间token通常基于模仿语言标签进行监督。考虑到一个问题可能存在多个等价但不同的CoT标签,被动地模仿任意一个标签可能导致较差的隐空间token表示和隐空间推理策略,从而削弱潜在的规划能力,并导致训练和测试之间存在明显的差距。在这项工作中,我们强调在隐空间token的表示空间上进行主动规划对于实现最佳隐空间推理策略的重要性。因此,我们提出了主动隐空间规划方法(ATP-Latent),该方法将隐空间token的监督过程建模为条件变分自编码器(VAE),以获得更平滑的隐空间。此外,为了促进最合理的隐空间推理策略,ATP-Latent利用辅助一致性奖励进行强化学习(RL),该奖励基于VAE解码的隐空间token内容之间的一致性计算,从而实现引导式RL过程。在LLaMA-1B上的实验表明,与先进的基线相比,ATP-Latent在四个基准测试中表现出+4.1%的准确率和-3.3%的token消耗。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在思维链(CoT)推理中效率低下的问题。现有的隐空间推理方法通过模仿学习训练隐空间token,但由于CoT标签的多样性,模仿任意一个标签可能导致次优的隐空间表示,限制了模型的推理能力和泛化性。
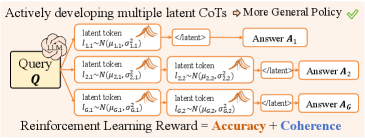
核心思路:论文的核心思路是采用主动规划的方式,通过强化学习(RL)优化隐空间token的表示,使其能够更好地支持CoT推理。通过引入一致性奖励,引导RL过程,鼓励模型生成更合理、连贯的推理路径。
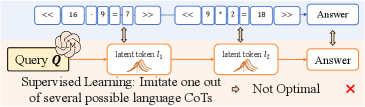
技术框架:ATP-Latent方法主要包含两个核心模块:条件变分自编码器(VAE)和强化学习(RL)模块。首先,使用条件VAE对隐空间token进行建模,以获得更平滑的隐空间表示。然后,利用RL算法,以VAE解码内容的一致性作为奖励信号,优化隐空间推理策略。整体流程为:输入问题 -> VAE编码为隐空间token -> RL策略选择下一个隐空间token -> VAE解码 -> 计算一致性奖励 -> 更新RL策略。
关键创新:该论文的关键创新在于将强化学习引入到隐空间推理中,实现了主动的隐空间规划。与传统的模仿学习方法不同,ATP-Latent通过RL优化隐空间token的表示,使其能够更好地适应不同的推理需求。此外,一致性奖励的设计也有效地引导了RL过程,提高了模型的推理能力。
关键设计:条件VAE的设计旨在生成更平滑的隐空间,提高模型的泛化能力。一致性奖励的计算方式是基于VAE解码内容之间的相似度,鼓励模型生成连贯的推理步骤。RL算法的选择和参数设置(例如奖励折扣因子、学习率等)也会影响模型的性能。具体的网络结构和损失函数细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ATP-Latent在LLaMA-1B模型上,与先进的基线方法相比,在四个基准测试中取得了显著的性能提升,准确率提高了4.1%,同时token消耗降低了3.3%。这表明ATP-Latent能够更有效地利用隐空间进行推理,提高了模型的效率和准确性。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的任务,例如数学问题求解、知识图谱推理、代码生成等。通过优化隐空间推理,可以显著提高LLMs的推理效率和准确性,降低计算成本,并为开发更智能的AI系统奠定基础。未来,该方法有望扩展到其他模态,例如图像和语音,实现更通用的推理能力。
📄 摘要(原文)
Aiming at efficient and dense chain-of-thought (CoT) reasoning, latent reasoning methods fine-tune Large Language Models (LLMs) to substitute discrete language tokens with continuous latent tokens. These methods consume fewer tokens compared to the conventional language CoT reasoning and have the potential to plan in a dense latent space. However, current latent tokens are generally supervised based on imitating language labels. Considering that there can be multiple equivalent but diverse CoT labels for a question, passively imitating an arbitrary one may lead to inferior latent token representations and latent reasoning policies, undermining the potential planning ability and resulting in clear gaps between training and testing. In this work, we emphasize the importance of active planning over the representation space of latent tokens in achieving the optimal latent reasoning policy. So, we propose the \underline{A}c\underline{t}ive Latent \underline{P}lanning method (ATP-Latent), which models the supervision process of latent tokens as a conditional variational auto-encoder (VAE) to obtain a smoother latent space. Moreover, to facilitate the most reasonable latent reasoning policy, ATP-Latent conducts reinforcement learning (RL) with an auxiliary coherence reward, which is calculated based on the consistency between VAE-decoded contents of latent tokens, enabling a guided RL process. In experiments on LLaMA-1B, ATP-Latent demonstrates +4.1\% accuracy and -3.3\% tokens on four benchmarks compared to advanced baselines. Codes are available on https://github.com/zz1358m/ATP-Latent-master.