The Effectiveness of Style Vectors for Steering Large Language Models: A Human Evaluation
作者: Diaoulé Diallo, Katharina Dworatzyk, Sophie Jentzsch, Peer Schütt, Sabine Theis, Tobias Hecking
分类: cs.AI, cs.CL, cs.HC
发布日期: 2026-01-29
期刊: IEEE Access 13 (2025) 191443-191457
DOI: 10.1109/ACCESS.2025.3628500
💡 一句话要点
通过风格向量操控大型语言模型:一项人类评估研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 情感控制 激活操控 风格向量 人类评估
📋 核心要点
- 现有方法如提示工程和微调在控制LLM行为方面存在局限性,需要更轻量级的替代方案。
- 该研究提出通过直接修改LLM内部激活的激活操控方法,以引导生成特定情感基调的文本。
- 实验表明,适度的操控强度能有效放大目标情感,且升级模型架构能提升操控的一致性和显著性。
📝 摘要(中文)
在推理时控制大型语言模型(LLM)的行为对于使其输出与人类能力和安全要求对齐至关重要。激活操控提供了一种轻量级的替代方案,以替代提示工程和微调,它通过直接修改内部激活来指导生成。本研究在三个重要方向上推进了该领域的研究。首先,虽然之前的工作已经证明了使用自动分类器操控情感基调的技术可行性,但本文首次对LLM输出的情感基调进行了激活操控的人类评估,通过Prolific平台从190名参与者那里收集了超过7000个众包评分。这些评分评估了感知到的情感强度和整体文本质量。其次,我们发现人类和基于模型的质量评分之间存在很强的一致性(平均r=0.776,范围0.157-0.985),表明自动评分可以代表感知到的质量。适度的操控强度(λ≈0.15)能够可靠地放大目标情感,同时保持可理解性,其中对厌恶(ηp²=0.616)和恐惧(ηp²=0.540)的影响最强,而对惊讶的影响最小(ηp²=0.042)。最后,从Alpaca升级到LlaMA-3产生了更一致的操控效果,并且在各种情感和强度上都具有显著影响(所有p<0.001)。评分者间信度很高(ICC=0.71-0.87),突出了研究结果的稳健性。这些发现支持基于激活的控制作为一种可扩展的方法,用于跨情感维度操控LLM的行为。
🔬 方法详解
问题定义:大型语言模型(LLM)的行为控制是一个重要问题,尤其是在情感表达方面。现有的提示工程和微调方法虽然有效,但计算成本高昂,且不够灵活。因此,需要一种更轻量级、更易于操控的方法来控制LLM生成文本的情感基调。
核心思路:该论文的核心思路是通过修改LLM内部的激活值(activation steering)来控制其输出的情感。具体来说,通过学习或预定义一些“风格向量”,将这些向量添加到LLM的中间层激活中,从而影响模型的生成过程,使其输出具有目标情感。这种方法无需重新训练模型,具有更高的效率和灵活性。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择一个预训练的LLM(如Alpaca或LlaMA-3);2) 定义一组目标情感(如喜悦、悲伤、愤怒等);3) 确定或学习与这些情感相关的“风格向量”;4) 在推理阶段,将风格向量添加到LLM的中间层激活中;5) 生成文本并进行评估。评估包括自动评估(使用情感分类器)和人工评估(通过众包平台收集人类评分)。
关键创新:该研究的关键创新在于首次对激活操控方法进行了大规模的人工评估,验证了其在控制LLM情感表达方面的有效性。此外,该研究还发现,不同情感的操控效果存在差异,且更先进的LLM架构(如LlaMA-3)能够提供更一致的操控效果。
关键设计:研究中,操控强度λ是一个关键参数,它控制着风格向量添加到激活中的比例。研究发现,适度的操控强度(λ≈0.15)能够可靠地放大目标情感,同时保持文本的可理解性。此外,研究还使用了内部一致性系数(ICC)来评估人工评分的可靠性,并使用了方差分析(ANOVA)来评估不同情感和强度下的操控效果。
🖼️ 关键图片
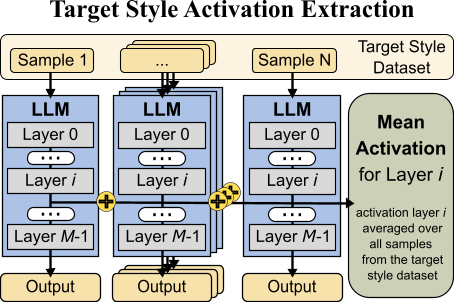
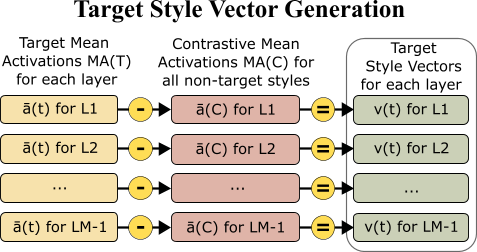
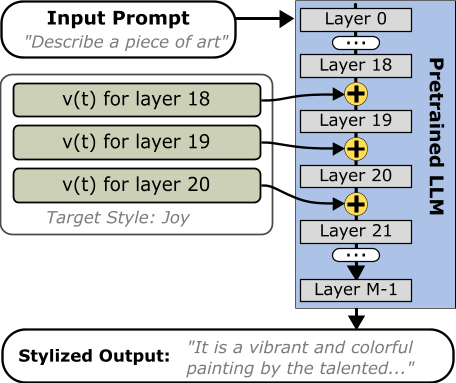
📊 实验亮点
该研究通过大规模人工评估(超过7000个评分)验证了激活操控方法在控制LLM情感表达方面的有效性。研究发现,适度的操控强度(λ≈0.15)能够可靠地放大目标情感,且升级到LlaMA-3模型后,操控效果更加一致和显著(所有p<0.001)。人类和模型质量评分之间存在高度一致性(平均r=0.776)。
🎯 应用场景
该研究成果可应用于多种场景,例如:情感聊天机器人、内容生成、心理健康支持等。通过控制LLM的情感表达,可以使其在不同应用场景中更好地与用户互动,提供更个性化和更有效的服务。未来,该技术还可用于生成更具创意和表现力的文本内容,例如诗歌、小说等。
📄 摘要(原文)
Controlling the behavior of large language models (LLMs) at inference time is essential for aligning outputs with human abilities and safety requirements. \emph{Activation steering} provides a lightweight alternative to prompt engineering and fine-tuning by directly modifying internal activations to guide generation. This research advances the literature in three significant directions. First, while previous work demonstrated the technical feasibility of steering emotional tone using automated classifiers, this paper presents the first human evaluation of activation steering concerning the emotional tone of LLM outputs, collecting over 7,000 crowd-sourced ratings from 190 participants via Prolific ($n=190$). These ratings assess both perceived emotional intensity and overall text quality. Second, we find strong alignment between human and model-based quality ratings (mean $r=0.776$, range $0.157$--$0.985$), indicating automatic scoring can proxy perceived quality. Moderate steering strengths ($λ\approx 0.15$) reliably amplify target emotions while preserving comprehensibility, with the strongest effects for disgust ($η_p^2 = 0.616$) and fear ($η_p^2 = 0.540$), and minimal effects for surprise ($η_p^2 = 0.042$). Finally, upgrading from Alpaca to LlaMA-3 yielded more consistent steering with significant effects across emotions and strengths (all $p < 0.001$). Inter-rater reliability was high (ICC $= 0.71$--$0.87$), underscoring the robustness of the findings. These findings support activation-based control as a scalable method for steering LLM behavior across affective dimensions.