MAR: Efficient Large Language Models via Module-aware Architecture Refinement
作者: Junhong Cai, Guiqin Wang, Kejie Zhao, Jianxiong Tang, Xiang Wang, Luziwei Leng, Ran Cheng, Yuxin Ma, Qinghai Guo
分类: cs.AI, cs.CL, cs.LG, cs.NE
发布日期: 2026-01-29
备注: Accepted by ICASSP 2026. 5 pages, 5 figures
💡 一句话要点
提出MAR框架,通过模块感知架构优化实现高效大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 架构优化 状态空间模型 脉冲神经网络 模型压缩
📋 核心要点
- 现有LLM计算成本高昂,主要瓶颈在于二次复杂度注意力机制和密集的FFN层。
- MAR框架通过集成SSM进行线性时间序列建模,并对FFN层进行激活稀疏化,降低计算复杂度。
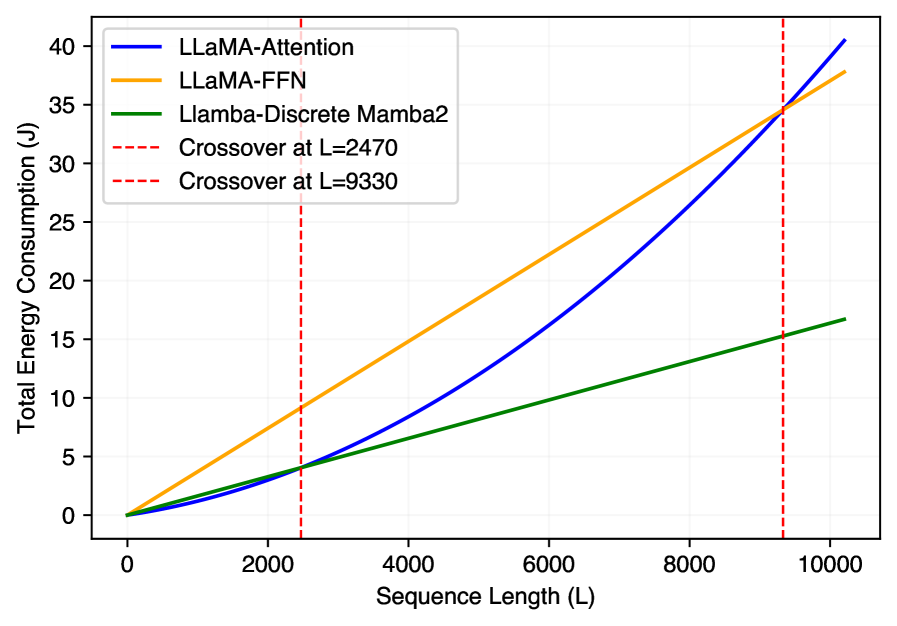
- 实验表明,MAR在资源受限情况下恢复了密集模型的性能,并显著降低了推理能耗,优于其他高效模型。
📝 摘要(中文)
大型语言模型(LLMs)在各个领域表现出色,但由于二次注意力机制和密集的Feed-Forward Network(FFN)运算,导致能源成本高昂。为了解决这些问题,我们提出了模块感知架构优化(MAR),这是一个两阶段框架,集成了状态空间模型(SSMs)以实现线性时间序列建模,并应用激活稀疏化来降低FFN成本。此外,为了减轻将脉冲神经网络(SNNs)与SSMs集成时出现的信息密度低和时间不匹配问题,我们设计了自适应三元多步神经元(ATMN)和脉冲感知双向蒸馏策略(SBDS)。大量实验表明,MAR在有限的资源下有效地恢复了其密集模型的性能,同时显著降低了推理能耗。此外,它优于同等规模甚至更大规模的高效模型,突显了其构建高效且实用的LLM的潜力。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在推理时面临高昂的计算成本和能源消耗,这主要是由于Transformer架构中二次复杂度自注意力机制以及密集的Feed-Forward Network(FFN)层导致的。现有的优化方法往往难以在性能和效率之间取得平衡,或者在将新兴的神经网络结构(如SNN)集成到LLM中时存在信息密度低和时间不匹配的问题。
核心思路:MAR的核心思路是通过模块化的架构优化,将状态空间模型(SSMs)集成到LLM中,以替代传统的自注意力机制,从而实现线性时间复杂度的序列建模。同时,通过激活稀疏化技术降低FFN层的计算成本。此外,针对SNN与SSM集成时的问题,设计了专门的神经元和训练策略,以提高信息密度和解决时间不匹配问题。
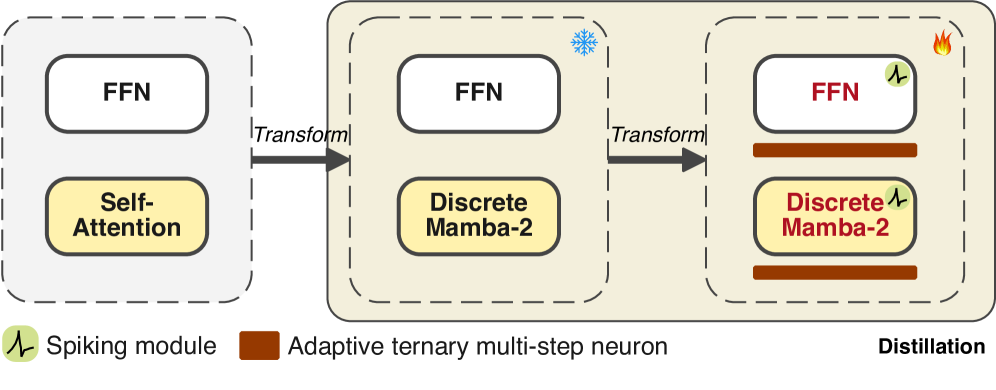
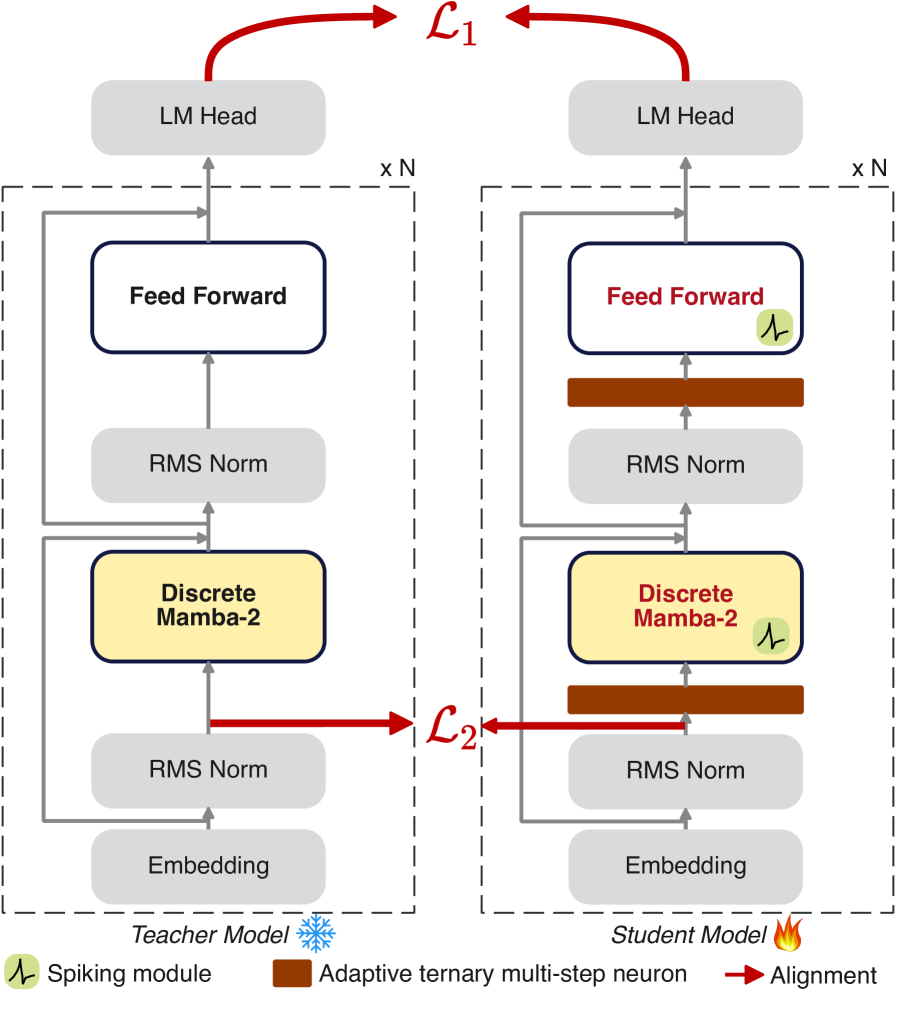
技术框架:MAR是一个两阶段的框架。第一阶段,使用SSM替换Transformer中的自注意力模块,从而降低序列建模的复杂度。第二阶段,对FFN层进行激活稀疏化,进一步降低计算成本。为了更好地将SNN集成到SSM中,MAR还包括ATMN(自适应三元多步神经元)和SBDS(脉冲感知双向蒸馏策略)两个关键模块。ATMN旨在提高SNN的信息密度,SBDS则用于解决SNN与SSM之间的时间不匹配问题。
关键创新:MAR的关键创新在于模块化的架构优化方法,它将SSM和激活稀疏化技术有效地结合起来,从而在降低计算成本的同时,保持了LLM的性能。此外,ATMN和SBDS的设计解决了SNN与SSM集成时面临的特有问题,使得SNN能够更好地应用于LLM中。与现有方法相比,MAR更加注重模块化的设计和针对性的优化,从而实现了更高的效率和更好的性能。
关键设计:ATMN是一种新型的脉冲神经元,它采用自适应的三元量化方法,可以根据输入动态地调整激活阈值,从而提高信息密度。SBDS是一种双向蒸馏策略,它将SSM的输出作为教师信号,指导SNN的训练,同时将SNN的输出作为学生信号,反过来优化SSM的参数,从而实现SNN和SSM之间的协同训练。在具体实现上,MAR采用了标准的Transformer架构,并将自注意力模块替换为Mamba等SSM变体。激活稀疏化采用了Magnitude-based Pruning等方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MAR框架在保持性能的同时,显著降低了推理能耗。例如,在某些任务上,MAR能够以更小的模型规模达到与更大规模的密集模型相当的性能,同时降低了高达50%的推理能耗。此外,MAR还优于其他高效LLM模型,证明了其在构建高效LLM方面的潜力。
🎯 应用场景
MAR框架具有广泛的应用前景,可用于构建低功耗、高效率的大型语言模型,适用于移动设备、边缘计算等资源受限的场景。该研究成果有助于推动LLM在实际应用中的普及,并为未来的高效LLM架构设计提供新的思路。
📄 摘要(原文)
Large Language Models (LLMs) excel across diverse domains but suffer from high energy costs due to quadratic attention and dense Feed-Forward Network (FFN) operations. To address these issues, we propose Module-aware Architecture Refinement (MAR), a two-stage framework that integrates State Space Models (SSMs) for linear-time sequence modeling and applies activation sparsification to reduce FFN costs. In addition, to mitigate low information density and temporal mismatch in integrating Spiking Neural Networks (SNNs) with SSMs, we design the Adaptive Ternary Multi-step Neuron (ATMN) and the Spike-aware Bidirectional Distillation Strategy (SBDS). Extensive experiments demonstrate that MAR effectively restores the performance of its dense counterpart under constrained resources while substantially reducing inference energy consumption. Furthermore, it outperforms efficient models of comparable or even larger scale, underscoring its potential for building efficient and practical LLMs.