The Path of Least Resistance: Guiding LLM Reasining Trajectories with Prefix Consensus
作者: Ishan Jindal, Sai Prashanth Akuthota, Jayant Taneja, Sachin Dev Sharma
分类: cs.AI, cs.CL
发布日期: 2026-01-29
备注: Accepted at ICLR 2026. https://openreview.net/forum?id=hrnSqERgPn
💡 一句话要点
PoLR:利用前缀一致性引导LLM推理,提升效率并保持准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理优化 自洽性 前缀一致性 计算效率
📋 核心要点
- 自洽性推理(SC)计算成本高,需完全展开所有推理路径,效率较低。
- PoLR通过聚类推理轨迹前缀,选择主要簇进行扩展,降低计算量。
- 实验表明,PoLR在多个数据集上匹配或超越SC,显著减少token使用和延迟。
📝 摘要(中文)
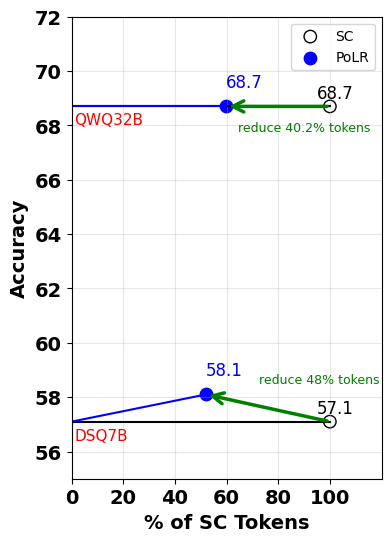
大型语言模型在推理方面表现出色,但诸如自洽性(SC)等推理策略计算成本高昂,因为它们会完全展开所有推理轨迹。我们引入PoLR(Path of Least Resistance),这是一种首个利用前缀一致性实现计算高效推理的推理时方法。PoLR对推理轨迹的短前缀进行聚类,识别出主要簇,并展开该簇中的所有路径,在显著减少token使用量和延迟的同时,保持SC的准确性优势。我们的理论分析,通过互信息和熵进行构建,解释了为什么早期的推理步骤编码了预测最终正确性的强信号。在GSM8K、MATH500、AIME24/25和GPQA-DIAMOND上,PoLR始终匹配或超过SC,token使用量最多减少60%,实际延迟最多减少50%。此外,PoLR与自适应推理方法(例如,自适应一致性、提前停止SC)完全互补,可以作为一种直接可用的预过滤器,使SC更高效和可扩展,而无需模型微调。
🔬 方法详解
问题定义:论文旨在解决大型语言模型推理过程中,自洽性(Self-Consistency, SC)方法计算成本过高的问题。SC通过生成多个推理路径并选择最一致的答案来提高准确性,但需要完全展开所有推理轨迹,导致token使用量大、延迟高,限制了其在资源受限场景下的应用。现有方法缺乏在保证准确性的前提下,有效降低计算复杂度的策略。
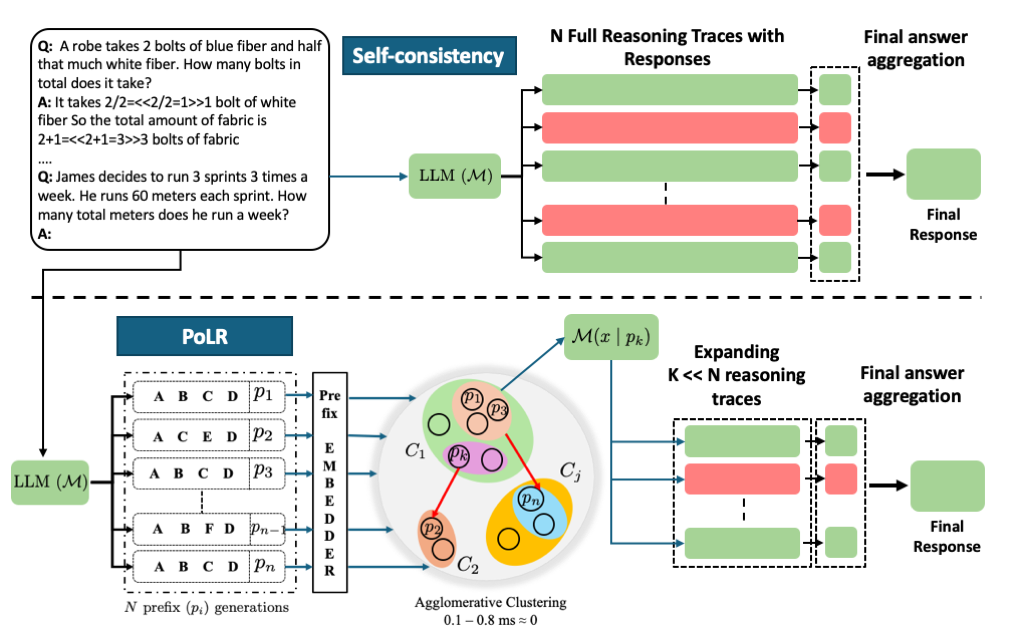
核心思路:PoLR的核心思路是观察到推理过程的早期步骤往往包含预测最终答案正确性的关键信息。因此,PoLR通过对推理轨迹的短前缀进行聚类,识别出最有可能产生正确答案的“主要簇”,然后只展开该簇中的路径。这样可以在很大程度上保留SC的准确性优势,同时显著减少需要处理的token数量和计算量。
技术框架:PoLR的整体流程如下: 1. 前缀采样:从LLM生成多个推理轨迹的短前缀。 2. 前缀聚类:使用聚类算法(如k-means)将这些前缀分组,形成不同的簇。 3. 簇选择:选择包含最多前缀的簇作为“主要簇”。 4. 路径扩展:仅扩展主要簇中的前缀,生成完整的推理轨迹。 5. 答案选择:使用SC方法从扩展后的轨迹中选择最终答案。
关键创新:PoLR的关键创新在于利用了推理轨迹前缀的一致性来指导推理过程,从而实现了计算效率和准确性的平衡。与传统的SC方法相比,PoLR避免了对所有推理路径的完全展开,显著降低了计算复杂度。与自适应推理方法相比,PoLR可以作为预过滤器,进一步提升效率。
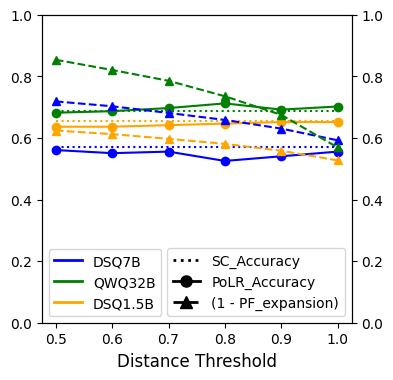
关键设计:PoLR的关键设计包括: 1. 前缀长度的选择:需要根据具体任务调整,过短可能无法有效区分不同路径,过长则计算成本增加。 2. 聚类算法的选择:可以使用不同的聚类算法,如k-means或层次聚类,选择合适的算法可以提高聚类效果。 3. 簇大小的阈值:可以设置一个阈值,只有当主要簇的大小超过该阈值时才进行扩展,以避免选择到错误的簇。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PoLR在GSM8K、MATH500、AIME24/25和GPQA-DIAMOND等数据集上,能够匹配或超过自洽性(SC)的准确率,同时将token使用量减少高达60%,实际延迟降低高达50%。PoLR还可以作为预过滤器,与自适应一致性等方法结合,进一步提升效率。
🎯 应用场景
PoLR可应用于各种需要LLM进行复杂推理的场景,例如数学问题求解、代码生成、知识问答等。该方法尤其适用于资源受限的环境,如移动设备或边缘计算平台,可以显著降低计算成本和延迟,提高用户体验。未来,PoLR可以与其他推理优化技术结合,进一步提升LLM的效率和可扩展性。
📄 摘要(原文)
Large language models achieve strong reasoning performance, but inference strategies such as Self-Consistency (SC) are computationally expensive, as they fully expand all reasoning traces. We introduce PoLR (Path of Least Resistance), the first inference-time method to leverage prefix consistency for compute-efficient reasoning. PoLR clusters short prefixes of reasoning traces, identifies the dominant cluster, and expands all paths in that cluster, preserving the accuracy benefits of SC while substantially reducing token usage and latency. Our theoretical analysis, framed via mutual information and entropy, explains why early reasoning steps encode strong signals predictive of final correctness. Empirically, PoLR consistently matches or exceeds SC across GSM8K, MATH500, AIME24/25, and GPQA-DIAMOND, reducing token usage by up to 60% and wall-clock latency by up to 50%. Moreover, PoLR is fully complementary to adaptive inference methods (e.g., Adaptive Consistency, Early-Stopping SC) and can serve as a drop-in pre-filter, making SC substantially more efficient and scalable without requiring model fine-tuning.