Adaptive Confidence Gating in Multi-Agent Collaboration for Efficient and Optimized Code Generation
作者: Haoji Zhang, Yuzhe Li, Zhenqiang Liu, Chenyang Liu, Shenyang Zhang, Yi Zhou
分类: cs.SE, cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出 DebateCoder,利用多智能体协作和自适应置信门控提升小模型代码生成能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体协作 代码生成 小语言模型 自适应置信门控 自动化软件工程
📋 核心要点
- 小语言模型在处理复杂逻辑的代码生成任务时,常面临推理瓶颈和失败循环的挑战。
- DebateCoder 通过多智能体协作,模拟辩论过程,提升小语言模型的推理能力,并采用自适应置信门控机制平衡准确性和效率。
- 实验结果表明,DebateCoder 在 HumanEval 上取得了显著的性能提升,同时降低了 API 开销,验证了其有效性。
📝 摘要(中文)
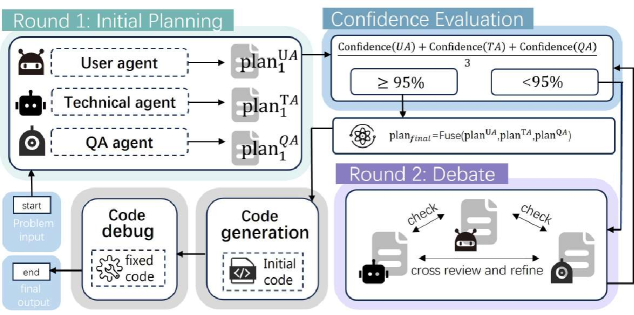
本文提出 DebateCoder,一个多智能体协作框架,旨在提升资源受限环境下小语言模型(SLMs,如Pangu-1B)的推理能力,以解决复杂逻辑需求的代码生成问题。DebateCoder采用结构化的角色扮演协议,包含用户代理(A_UA)、技术代理(A_TA)和质量保证代理(A_QA)三个智能体。此外,它还包含一个自适应置信门控机制(95%阈值),用于平衡准确性和推理效率。同时,引入了多轮审议模块和审查员引导的分析调试循环,分别用于生成前的辩论和生成后的改进。在HumanEval和MBPP上的实验表明,DebateCoder在HumanEval上实现了70.12%的Pass@1,优于MapCoder,同时降低了约35%的API开销。结果表明,协作协议可以缓解小参数模型的局限性,并为高质量的自动化软件工程提供可扩展、高效的方法。
🔬 方法详解
问题定义:论文旨在解决小语言模型(SLMs)在复杂代码生成任务中推理能力不足的问题。现有方法,如直接使用SLMs生成代码,容易陷入推理瓶颈和失败循环,难以满足复杂的逻辑需求。此外,现有方法可能需要大量的API调用,导致较高的计算成本。
核心思路:论文的核心思路是利用多智能体协作,模拟人类辩论的过程,从而激发SLMs的推理能力。通过让不同的智能体扮演不同的角色(用户、技术专家、质量保证),互相质疑和验证,可以有效地发现和纠正代码中的错误。同时,采用自适应置信门控机制,可以根据智能体的置信度动态调整推理过程,从而平衡准确性和效率。
技术框架:DebateCoder 的整体架构包含三个主要模块:角色扮演协议、自适应置信门控和多轮审议与调试。角色扮演协议定义了三个智能体的角色和交互方式:用户代理(A_UA)负责提出需求,技术代理(A_TA)负责生成代码,质量保证代理(A_QA)负责评估代码质量。自适应置信门控机制根据 A_QA 的置信度决定是否接受 A_TA 生成的代码。多轮审议与调试模块则允许智能体之间进行多轮辩论和调试,以进一步提高代码质量。
关键创新:DebateCoder 的关键创新在于将多智能体协作和自适应置信门控机制相结合,用于提升小语言模型的代码生成能力。与传统的单智能体方法相比,DebateCoder 可以更好地利用多个智能体的知识和能力,从而提高代码的准确性和可靠性。自适应置信门控机制则可以根据任务的难度和智能体的能力动态调整推理过程,从而提高效率。
关键设计:自适应置信门控机制的关键参数是置信度阈值,论文中设置为95%。这个阈值决定了 A_QA 认为代码质量足够高的最低标准。多轮审议与调试模块的关键设计在于定义了智能体之间的交互协议,包括辩论的轮数、提问的方式和回答的格式。这些设计旨在促进智能体之间的有效沟通和协作。
🖼️ 关键图片


📊 实验亮点
DebateCoder 在 HumanEval 上实现了 70.12% 的 Pass@1,显著优于 MapCoder。同时,DebateCoder 将 API 开销降低了约 35%。这些结果表明,DebateCoder 能够有效地提升小语言模型的代码生成能力,并降低计算成本。
🎯 应用场景
DebateCoder 有潜力应用于各种自动化软件工程场景,例如自动化代码生成、代码审查和代码调试。它可以帮助开发者更高效地生成高质量的代码,降低开发成本,并提高软件的可靠性。此外,该框架还可以扩展到其他领域,例如自然语言处理和机器人控制。
📄 摘要(原文)
While Large Language Models (LLMs) have catalyzed breakthroughs in automated code generation, Small Language Models (SLMs) often encounter reasoning bottlenecks and failure loops when addressing complex logical requirements. To overcome these challenges, we propose DebateCoder, a multi-agent collaborative framework designed to improve the reasoning ability of SLMs (e.g., Pangu-1B) in resource-constrained environments. DebateCoder uses a structured role-playing protocol with three agents: User Agent (A_UA), Technical Agent (A_TA), and Quality Assurance Agent (A_QA). It also includes an Adaptive Confidence Gating mechanism with a 95% threshold to balance accuracy and inference efficiency. In addition, we introduce a multi-turn deliberation module and a reviewer-guided analytical debugging loop for orthogonal pre-generation debate and post-generation refinement. Experiments on HumanEval and MBPP show that DebateCoder achieves 70.12% Pass@1 on HumanEval, outperforming MapCoder while reducing API overhead by about 35%. These results indicate that collaborative protocols can mitigate limitations of small-parameter models and provide a scalable, efficient approach to high-quality automated software engineering.