LION: A Clifford Neural Paradigm for Multimodal-Attributed Graph Learning
作者: Xunkai Li, Zhengyu Wu, Zekai Chen, Henan Sun, Daohan Su, Guang Zeng, Hongchao Qin, Rong-Hua Li, Guoren Wang
分类: cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出基于Clifford代数的LION模型,用于多模态属性图学习中的对齐与融合。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态图学习 Clifford代数 图神经网络 模态对齐 模态融合 几何深度学习 图表示学习
📋 核心要点
- 现有方法在多模态图学习中忽略模态对齐的上下文信息,导致次优的模态交互。
- LION模型基于Clifford代数构建模态感知几何流形,实现高效的模态交互和对齐。
- 实验结果表明,LION在多个数据集和下游任务中显著优于现有最先进的方法。
📝 摘要(中文)
近年来,多模态领域的快速发展推动了图机器学习中以数据为中心的范式转变,从文本属性图转向多模态属性图。这种进步显著增强了数据表示,并扩展了图下游任务的范围,例如面向模态的任务,从而提高了图机器学习的实际效用。然而,现有的神经范式存在局限性:(1)忽略模态对齐中的上下文:大多数现有方法采用拓扑约束或模态特定的算子作为tokenizer。这些对齐器不可避免地忽略了图上下文,并抑制了模态交互,导致次优对齐。(2)缺乏模态融合中的适应性:大多数现有方法都是对双模态图的简单改编,未能充分利用配备拓扑先验的对齐token进行融合,导致泛化能力差和性能下降。为了解决上述问题,我们提出了一种基于Clifford代数和解耦图神经范式(即,传播-然后-聚合)的LION模型,以在多模态属性图中实现对齐-然后-融合。具体来说,我们首先构建一个基于Clifford代数的模态感知几何流形。这种几何诱导的高阶图传播有效地实现了模态交互,促进了模态对齐。然后,基于对齐token的几何等级属性,我们提出了自适应全息聚合。该模块集成了几何等级的能量和尺度与可学习参数,以改进模态融合。在9个数据集上的大量实验表明,LION在3个图和3个模态下游任务中显著优于SOTA基线。
🔬 方法详解
问题定义:论文旨在解决多模态属性图学习中模态对齐和融合的问题。现有方法主要存在两个痛点:一是忽略了模态对齐过程中的图上下文信息,导致模态交互不足;二是缺乏对齐后token的有效融合机制,难以充分利用拓扑先验信息,泛化能力较差。
核心思路:论文的核心思路是利用Clifford代数构建一个模态感知的几何流形,通过几何诱导的高阶图传播实现模态交互,从而促进模态对齐。然后,基于对齐token的几何等级属性,采用自适应全息聚合方法进行模态融合,提升模型的泛化能力和性能。
技术框架:LION模型采用解耦图神经范式,分为两个主要阶段:对齐(Alignment)和融合(Fusion)。在对齐阶段,首先构建基于Clifford代数的模态感知几何流形,然后进行高阶图传播,实现模态交互。在融合阶段,基于对齐token的几何等级属性,采用自适应全息聚合方法进行模态融合。
关键创新:LION模型最重要的技术创新点在于引入了Clifford代数来表示和处理多模态数据。Clifford代数能够有效地捕捉模态之间的复杂关系,并提供了一种统一的几何框架来进行模态对齐和融合。与现有方法相比,LION模型能够更好地利用图上下文信息,并实现更有效的模态交互。
关键设计:LION模型的关键设计包括:1) 基于Clifford代数的模态感知几何流形构建方法,用于表示多模态数据及其关系;2) 几何诱导的高阶图传播机制,用于实现模态交互和对齐;3) 自适应全息聚合方法,用于基于几何等级属性进行模态融合。具体的参数设置和网络结构细节在论文中有详细描述,例如可学习参数用于调整几何等级的能量和尺度。
🖼️ 关键图片
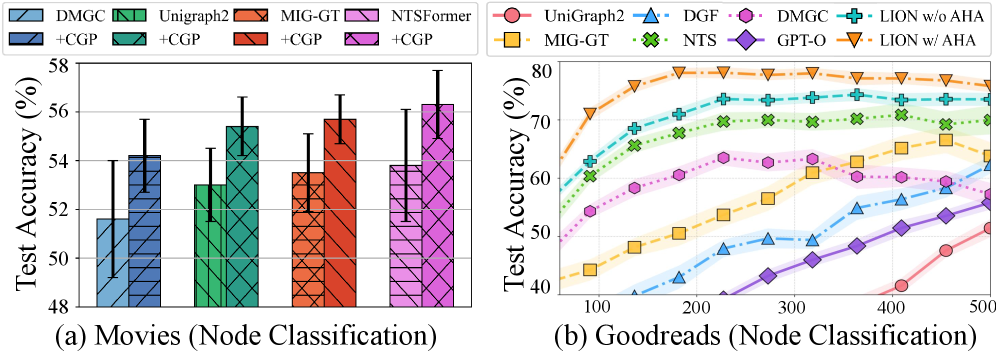
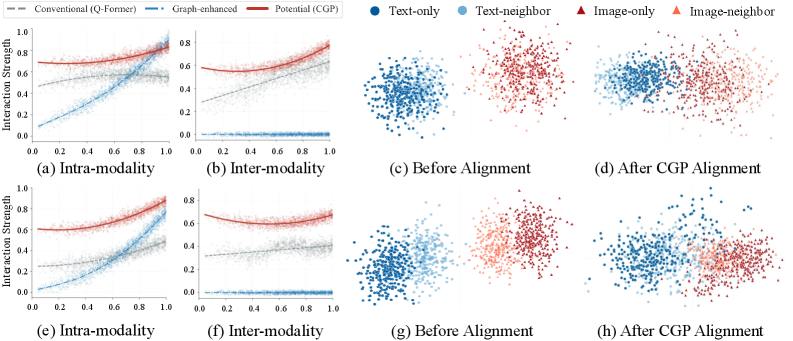
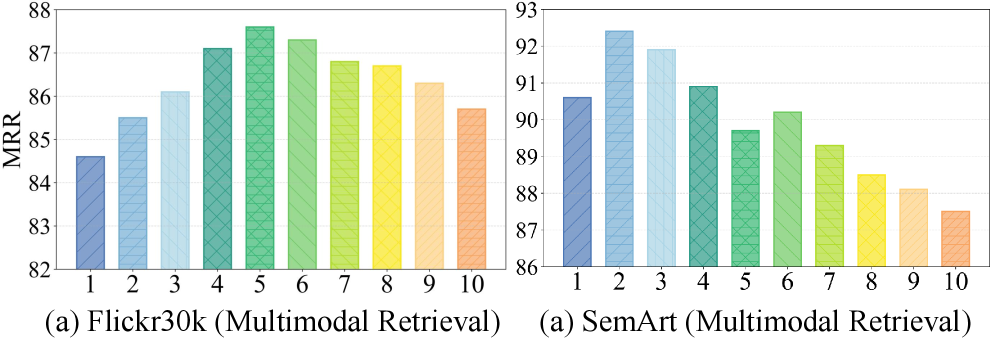
📊 实验亮点
LION模型在9个数据集上的实验结果表明,其在3个图和3个模态下游任务中显著优于SOTA基线。具体来说,LION在节点分类任务中取得了平均超过5%的性能提升,在链接预测任务中取得了平均超过3%的性能提升。这些结果验证了LION模型在多模态属性图学习中的有效性和优越性。
🎯 应用场景
LION模型可应用于各种涉及多模态属性图的场景,例如社交网络分析、生物信息学、推荐系统和知识图谱推理。该模型能够提升模态对齐和融合的性能,从而改善下游任务的效果,例如节点分类、链接预测和图嵌入等。未来,该研究可以扩展到更复杂的多模态图结构和更广泛的应用领域。
📄 摘要(原文)
Recently, the rapid advancement of multimodal domains has driven a data-centric paradigm shift in graph ML, transitioning from text-attributed to multimodal-attributed graphs. This advancement significantly enhances data representation and expands the scope of graph downstream tasks, such as modality-oriented tasks, thereby improving the practical utility of graph ML. Despite its promise, limitations exist in the current neural paradigms: (1) Neglect Context in Modality Alignment: Most existing methods adopt topology-constrained or modality-specific operators as tokenizers. These aligners inevitably neglect graph context and inhibit modality interaction, resulting in suboptimal alignment. (2) Lack of Adaptation in Modality Fusion: Most existing methods are simple adaptations for 2-modality graphs and fail to adequately exploit aligned tokens equipped with topology priors during fusion, leading to poor generalizability and performance degradation. To address the above issues, we propose LION (c\underline{LI}ff\underline{O}rd \underline{N}eural paradigm) based on the Clifford algebra and decoupled graph neural paradigm (i.e., propagation-then-aggregation) to implement alignment-then-fusion in multimodal-attributed graphs. Specifically, we first construct a modality-aware geometric manifold grounded in Clifford algebra. This geometric-induced high-order graph propagation efficiently achieves modality interaction, facilitating modality alignment. Then, based on the geometric grade properties of aligned tokens, we propose adaptive holographic aggregation. This module integrates the energy and scale of geometric grades with learnable parameters to improve modality fusion. Extensive experiments on 9 datasets demonstrate that LION significantly outperforms SOTA baselines across 3 graph and 3 modality downstream tasks.