ChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design
作者: Zhongkai Yu, Chenyang Zhou, Yichen Lin, Hejia Zhang, Haotian Ye, Junxia Cui, Zaifeng Pan, Jishen Zhao, Yufei Ding
分类: cs.AI, cs.AR
发布日期: 2026-01-29
🔗 代码/项目: GITHUB
💡 一句话要点
ChipBench:用于评估LLM在AI辅助芯片设计中性能的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 芯片设计 大型语言模型 基准测试 Verilog生成 代码调试 参考模型生成 AI辅助设计 硬件工程
📋 核心要点
- 现有硬件工程基准测试已饱和,且任务类型单一,无法真实反映LLM在芯片设计工业流程中的性能。
- 提出ChipBench基准,包含Verilog生成、调试和参考模型生成三大任务,更贴近实际芯片设计流程。
- 实验表明,即使是SOTA模型在ChipBench上的表现也远低于现有基准,揭示了LLM在芯片设计领域的挑战。
📝 摘要(中文)
大型语言模型(LLM)在硬件工程中展现出巨大潜力,但现有基准测试存在饱和和任务多样性有限的问题,无法反映LLM在实际工业工作流程中的性能。为了解决这一差距,我们提出了一个全面的AI辅助芯片设计基准,严格评估LLM在三个关键任务中的表现:Verilog生成、调试和参考模型生成。我们的基准包含44个具有复杂分层结构的真实模块,89个系统调试案例,以及跨Python、SystemC和CXXRTL的132个参考模型样本。评估结果显示存在显著的性能差距,最先进的Claude-4.5-opus在Verilog生成方面仅达到30.74%,在Python参考模型生成方面仅达到13.33%,与现有饱和基准测试(SOTA模型达到95%以上的通过率)相比,面临着巨大的挑战。此外,为了帮助增强LLM参考模型生成,我们提供了一个自动化的工具箱,用于生成高质量的训练数据,从而促进该未被充分探索的领域中的未来研究。我们的代码可在https://github.com/zhongkaiyu/ChipBench.git上找到。
🔬 方法详解
问题定义:现有的大语言模型(LLM)在硬件工程领域展现出潜力,但现有的评估基准存在两个主要问题。一是基准测试已经饱和,即最先进的模型已经接近或达到完美的性能,难以区分不同模型的优劣。二是任务多样性不足,无法全面评估LLM在实际芯片设计工作流程中的能力,例如Verilog生成、调试和参考模型生成等。
核心思路:为了解决现有基准的局限性,论文提出了ChipBench,一个专门为AI辅助芯片设计而设计的综合性基准测试。ChipBench的核心思路是提供更具挑战性和现实性的任务,以更准确地评估LLM在芯片设计中的实际能力。通过引入复杂的分层结构、系统性的调试案例和多种编程语言的参考模型,ChipBench旨在模拟真实的工业工作流程,从而更好地反映LLM的性能。
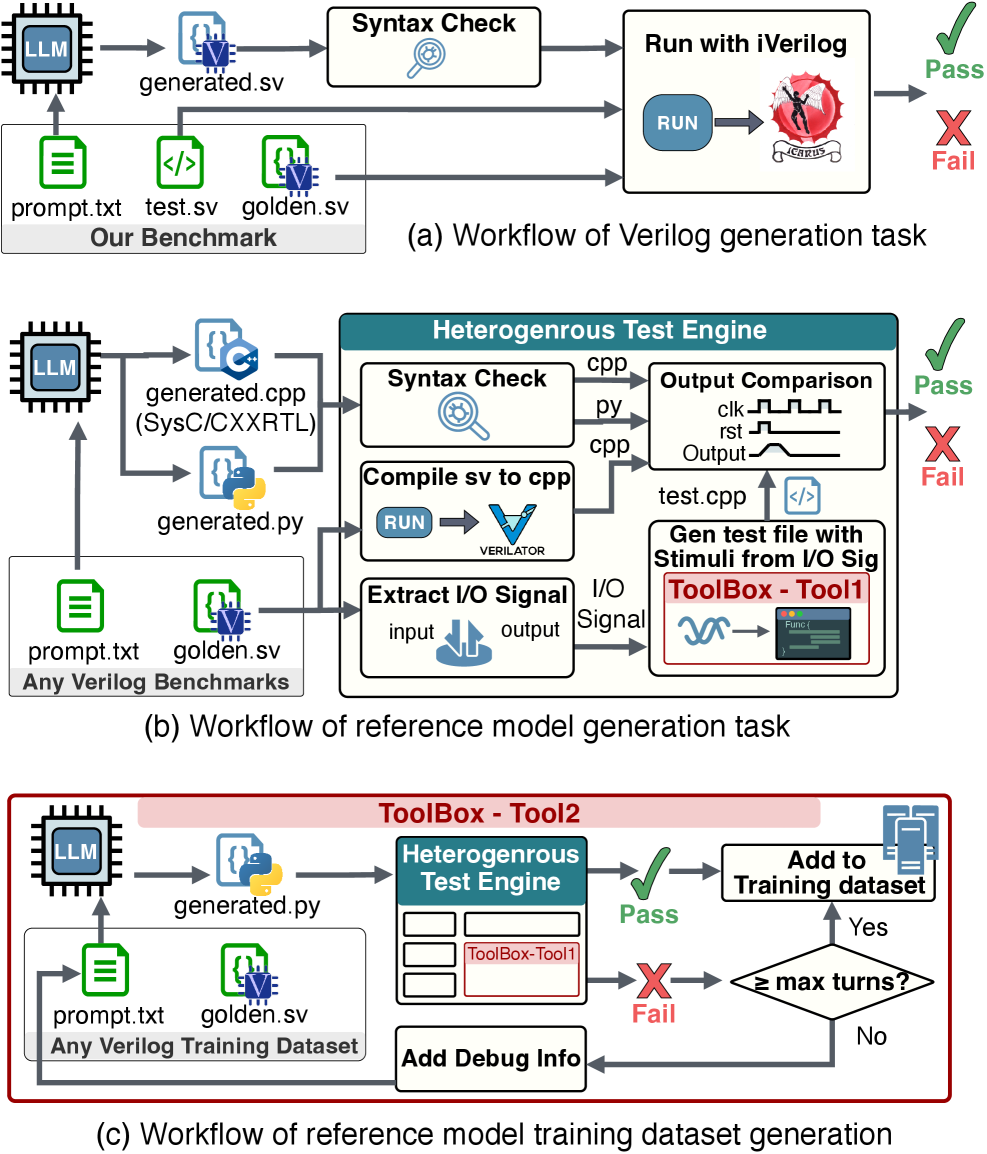
技术框架:ChipBench基准测试主要包含三个关键任务:Verilog生成、调试和参考模型生成。Verilog生成任务要求LLM根据给定的规格生成Verilog代码。调试任务涉及识别和修复Verilog代码中的错误。参考模型生成任务要求LLM生成与Verilog代码等效的Python、SystemC或CXXRTL模型。此外,论文还提供了一个自动化的工具箱,用于生成高质量的训练数据,以促进LLM在参考模型生成方面的研究。
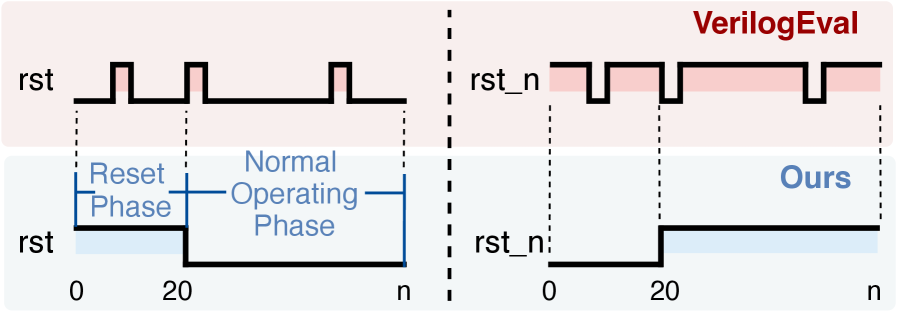
关键创新:ChipBench的主要创新在于其更贴近实际工业流程的任务设计和更具挑战性的数据集。与现有基准相比,ChipBench引入了更复杂的模块结构、更系统的调试案例和更多样化的参考模型,从而更全面地评估LLM在芯片设计中的能力。此外,自动化训练数据生成工具箱的提供也为未来的研究提供了便利。
关键设计:ChipBench包含44个具有复杂分层结构的真实模块,89个系统调试案例,以及跨Python、SystemC和CXXRTL的132个参考模型样本。Verilog生成任务的评估指标是生成的代码是否能够通过功能验证。调试任务的评估指标是LLM是否能够正确识别和修复代码中的错误。参考模型生成任务的评估指标是生成的模型是否与Verilog代码等效。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是最先进的Claude-4.5-opus模型在ChipBench上的表现也远低于现有饱和基准。例如,Claude-4.5-opus在Verilog生成方面仅达到30.74%的通过率,在Python参考模型生成方面仅达到13.33%的通过率。这表明LLM在实际芯片设计任务中仍面临着巨大的挑战,ChipBench能够有效区分不同LLM的性能差异。
🎯 应用场景
ChipBench可用于评估和比较不同LLM在AI辅助芯片设计中的性能,帮助研究人员和工程师选择最适合其需求的模型。该基准还可以促进LLM在芯片设计领域的应用,例如自动化Verilog代码生成、辅助代码调试和生成参考模型,从而提高芯片设计的效率和质量。未来,ChipBench可以扩展到支持更多的芯片设计任务和编程语言,并集成到实际的芯片设计流程中。
📄 摘要(原文)
While Large Language Models (LLMs) show significant potential in hardware engineering, current benchmarks suffer from saturation and limited task diversity, failing to reflect LLMs' performance in real industrial workflows. To address this gap, we propose a comprehensive benchmark for AI-aided chip design that rigorously evaluates LLMs across three critical tasks: Verilog generation, debugging, and reference model generation. Our benchmark features 44 realistic modules with complex hierarchical structures, 89 systematic debugging cases, and 132 reference model samples across Python, SystemC, and CXXRTL. Evaluation results reveal substantial performance gaps, with state-of-the-art Claude-4.5-opus achieving only 30.74\% on Verilog generation and 13.33\% on Python reference model generation, demonstrating significant challenges compared to existing saturated benchmarks where SOTA models achieve over 95\% pass rates. Additionally, to help enhance LLM reference model generation, we provide an automated toolbox for high-quality training data generation, facilitating future research in this underexplored domain. Our code is available at https://github.com/zhongkaiyu/ChipBench.git.