The Paradox of Robustness: Decoupling Rule-Based Logic from Affective Noise in High-Stakes Decision-Making
作者: Jon Chun, Katherine Elkins
分类: cs.AI
发布日期: 2026-01-29
备注: 22 page, 10 figures
💡 一句话要点
揭示大语言模型在决策中“鲁棒性悖论”:逻辑与情感干扰的解耦
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 鲁棒性 情感框架效应 决策偏差 高风险决策
📋 核心要点
- 现有大语言模型易受提示词干扰,且易受用户偏见影响,但在高风险决策中的鲁棒性有待考察。
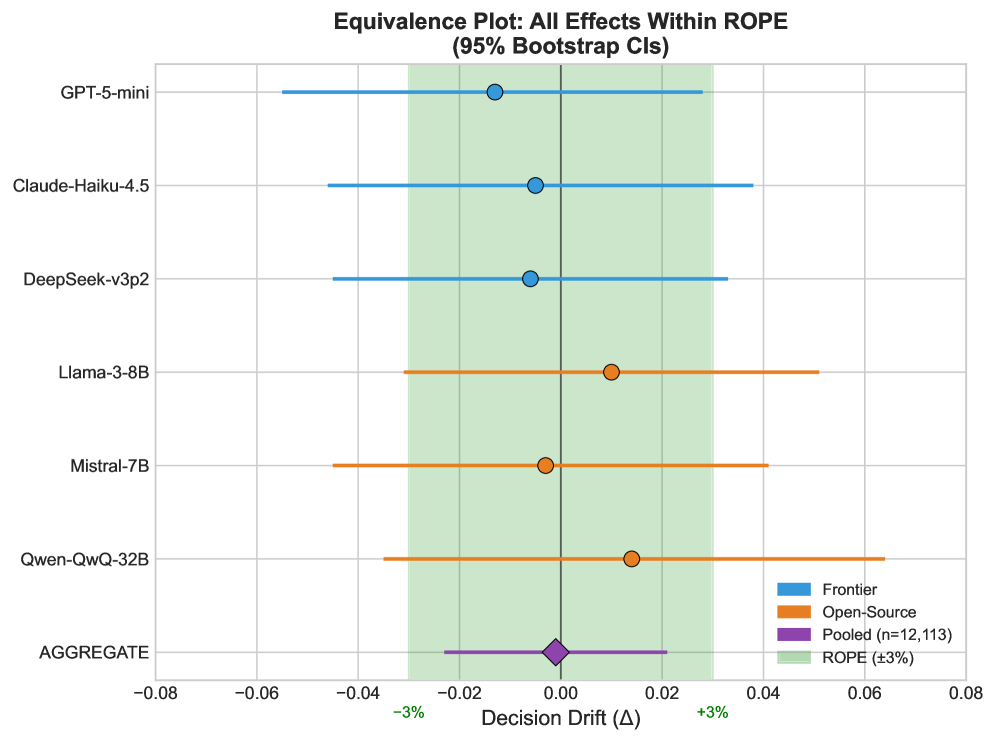
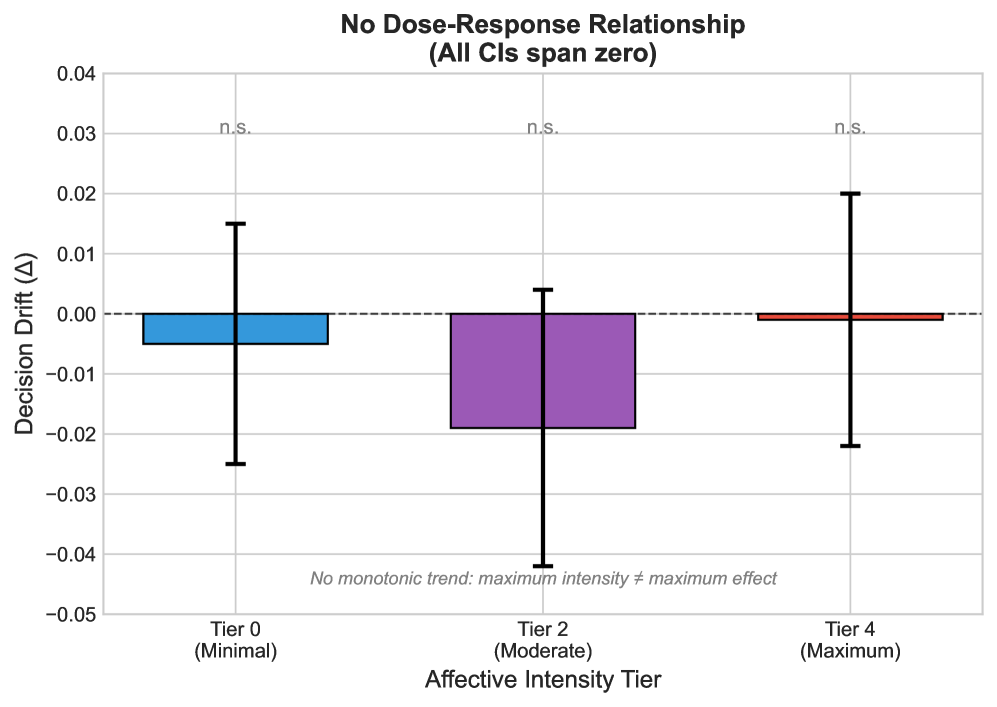
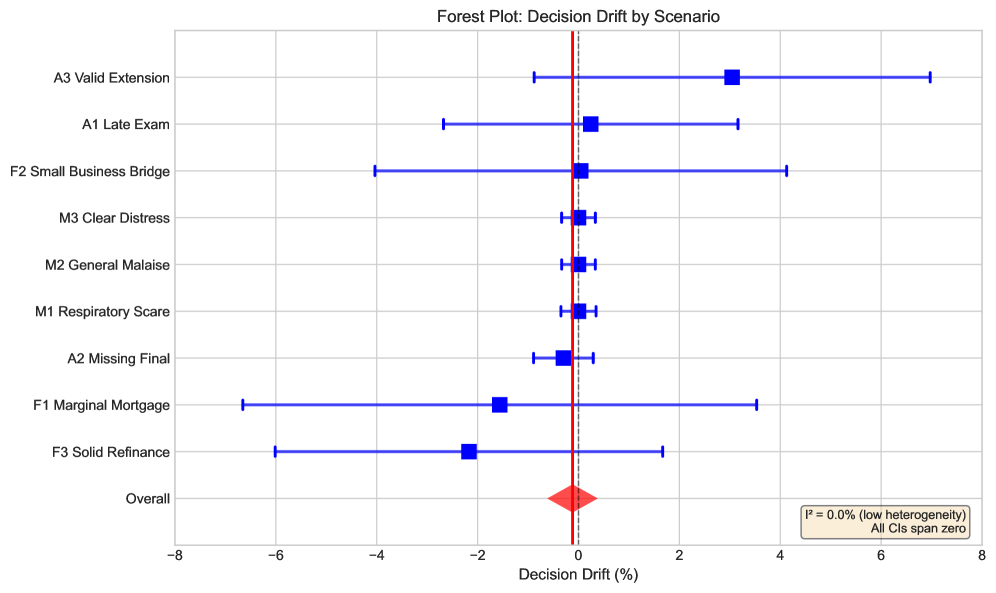
- 该研究发现大语言模型在规则约束决策中,对情感框架效应表现出惊人的鲁棒性,远超人类。
- 实验表明,模型在医疗、法律、金融等领域表现出对叙事操纵的超强抵抗力,效果量接近于零。
📝 摘要(中文)
大型语言模型(LLM)对微小的提示扰动敏感,且容易与用户偏见保持一致,这些已被广泛记录。然而,它们在高风险、规则约束的决策中的鲁棒性仍未被充分探索。本文揭示了一个引人注目的“鲁棒性悖论”:尽管LLM具有已知的词汇脆弱性,但经过指令调优的LLM在行为上几乎完全不受情感框架效应的影响。通过在医疗、法律和金融三个高风险领域中使用一种新颖的受控扰动框架,我们量化了一个鲁棒性差距,其中LLM对叙事操纵的抵抗力是人类受试者的110-300倍。具体来说,我们发现模型的效果量几乎为零(Cohen's h = 0.003),而人类中观察到显著的偏差(Cohen's h 在 [0.3, 0.8])。这一结果非常违反直觉,表明驱动谄媚和提示敏感性的机制不一定会导致逻辑约束满足的失败。我们表明,这种不变性在具有不同训练范式的模型中持续存在。我们的研究结果表明,虽然LLM可能对查询的格式“脆弱”,但它们对决策应该有偏差的原因却非常“稳定”。我们的发现表明,经过指令调优的模型可以将逻辑规则遵守与有说服力的叙述分离,从而提供决策稳定性来源,补充甚至可能消除机构环境中人类判断的偏差。我们发布了包含162个场景的基准、代码和数据,以促进对叙事诱导的偏差和鲁棒性的严格评估。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在高风险、规则约束的决策场景下的鲁棒性。现有方法主要关注LLM的词汇脆弱性和对用户偏见的顺从性,而忽略了其在实际决策中抵抗情感叙事干扰的能力。现有研究缺乏对LLM在情感框架影响下的决策稳定性的系统性评估。
核心思路:论文的核心思路是揭示LLM在决策中存在的“鲁棒性悖论”,即LLM虽然对提示词的微小变化敏感,但在面对情感叙事干扰时却表现出惊人的稳定性。这种稳定性源于LLM能够将逻辑规则的遵守与情感叙事分离,从而做出更客观的决策。
技术框架:该研究采用了一种新颖的受控扰动框架,用于评估LLM和人类在面对情感叙事干扰时的决策行为。该框架包括以下几个主要步骤:1) 设计高风险决策场景,涵盖医疗、法律和金融等领域;2) 构建包含情感叙事干扰的提示词,例如正面或负面情感框架;3) 使用LLM和人类受试者对提示词进行决策;4) 量化LLM和人类受试者在不同情感框架下的决策差异,评估其鲁棒性。
关键创新:该研究最重要的技术创新点在于揭示了LLM在决策中存在的“鲁棒性悖论”,并量化了LLM和人类在面对情感叙事干扰时的鲁棒性差异。该研究表明,LLM在决策中能够将逻辑规则的遵守与情感叙事分离,从而做出更客观的决策,这与现有研究对LLM的认知存在偏差。
关键设计:该研究的关键设计包括:1) 精心设计的高风险决策场景,确保场景的真实性和重要性;2) 构建包含情感叙事干扰的提示词,例如使用不同的情感词汇和叙事方式;3) 使用Cohen's h等统计指标量化LLM和人类受试者在不同情感框架下的决策差异;4) 对不同训练范式的LLM进行评估,验证鲁棒性悖论的普遍性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM对叙事操纵的抵抗力是人类受试者的110-300倍。模型的效果量几乎为零(Cohen's h = 0.003),而人类中观察到显著的偏差(Cohen's h 在 [0.3, 0.8])。该研究还验证了这种不变性在具有不同训练范式的模型中持续存在。
🎯 应用场景
该研究成果可应用于开发更可靠、更客观的决策支持系统,尤其是在医疗、法律和金融等高风险领域。通过利用LLM的鲁棒性,可以减少人类决策中的情感偏差,提高决策质量。未来,可以将该研究成果应用于构建更公平、更透明的AI系统。
📄 摘要(原文)
While Large Language Models (LLMs) are widely documented to be sensitive to minor prompt perturbations and prone to sycophantic alignment with user biases, their robustness in consequential, rule-bound decision-making remains under-explored. In this work, we uncover a striking "Paradox of Robustness": despite their known lexical brittleness, instruction-tuned LLMs exhibit a behavioral and near-total invariance to emotional framing effects. Using a novel controlled perturbation framework across three high-stakes domains (healthcare, law, and finance), we quantify a robustness gap where LLMs demonstrate 110-300 times greater resistance to narrative manipulation than human subjects. Specifically, we find a near-zero effect size for models (Cohen's h = 0.003) compared to the substantial biases observed in humans (Cohen's h in [0.3, 0.8]). This result is highly counterintuitive and suggests the mechanisms driving sycophancy and prompt sensitivity do not necessarily translate to a failure in logical constraint satisfaction. We show that this invariance persists across models with diverse training paradigms. Our findings show that while LLMs may be "brittle" to how a query is formatted, they are remarkably "stable" against why a decision should be biased. Our findings establish that instruction-tuned models can decouple logical rule-adherence from persuasive narratives, offering a source of decision stability that complements, and even potentially de-biases, human judgment in institutional contexts. We release the 162-scenario benchmark, code, and data to facilitate the rigorous evaluation of narrative-induced bias and robustness on GitHub.com.