TeachBench: A Syllabus-Grounded Framework for Evaluating Teaching Ability in Large Language Models
作者: Zheng Li, Siyao Song, Jingyuan Ma, Rui Li, Ying Zeng, Minghao Li, Zhifang Sui
分类: cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出TeachBench:一个基于教学大纲评估大语言模型教学能力的框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 教学能力评估 教学大纲 知识图谱 智能教育
📋 核心要点
- 现有基准测试缺乏对LLM以知识为中心的教学能力的有效评估,主要集中于问题解决层面。
- TeachBench框架通过限制教师代理在结构化知识点和例题中,评估学生在多轮指导后的表现提升。
- 实验表明,不同LLM在不同学科的教学效果差异显著,且加入例题不一定能提升教学效果。
📝 摘要(中文)
大型语言模型(LLMs)在作为教学助手方面展现出潜力,但其教学能力仍未得到充分评估。现有的基准测试主要集中在问题解决或问题层面的指导,而以知识为中心的教学则未被充分探索。我们提出了一个基于教学大纲的评估框架,该框架通过学生在多轮指导后的表现提升来衡量LLM的教学能力。通过将教师代理限制在结构化的知识点和例题中,该框架避免了信息泄露,并实现了现有基准测试的重用。我们在多个学科的高考数据上实例化了该框架。实验表明,不同模型和领域之间的教学效果存在显著差异:一些模型在数学方面表现良好,但在物理和化学方面的教学仍然具有挑战性。我们还发现,加入例题并不一定能提高教学效果,因为模型通常会转向针对特定例子的错误纠正。总的来说,我们的结果强调了教学能力是LLM行为中一个独特且可衡量的维度。
🔬 方法详解
问题定义:现有的大语言模型教学能力评估主要集中在问题解决层面,缺乏对知识传授和学生理解程度提升的有效衡量。现有的评估方法容易出现信息泄露,并且难以复用现有的数据集。因此,如何设计一个能够有效、公平地评估LLM教学能力的框架是一个关键问题。
核心思路:论文的核心思路是通过构建一个基于教学大纲的评估框架,将LLM的教学行为限制在结构化的知识点和例题中,并通过学生在接受教学后的表现提升来衡量LLM的教学能力。这种方法避免了信息泄露,并允许复用现有的数据集。
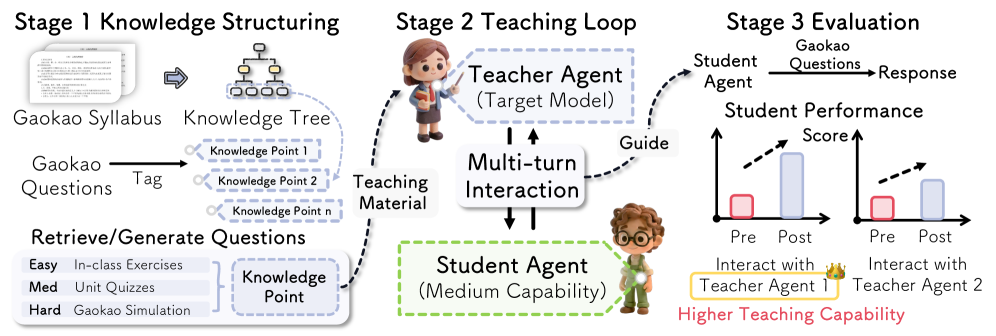
技术框架:TeachBench框架包含以下主要模块:1) 知识点提取模块:从教学大纲中提取结构化的知识点。2) 例题选择模块:根据知识点选择相应的例题。3) 教学交互模块:LLM作为教师,与学生进行多轮交互,讲解知识点和例题。4) 评估模块:通过学生在教学前后的测试成绩差异来评估LLM的教学能力。整体流程是,首先根据教学大纲提取知识点和例题,然后LLM根据这些知识点和例题进行教学,最后通过评估模块来衡量教学效果。
关键创新:该论文最重要的技术创新点在于提出了一个基于教学大纲的评估框架,该框架能够有效避免信息泄露,并允许复用现有的数据集。此外,该框架还能够衡量LLM在不同学科的教学能力,并分析不同教学策略的效果。与现有方法的本质区别在于,TeachBench更加关注知识传授和学生理解程度的提升,而不是仅仅关注问题解决能力。
关键设计:框架的关键设计包括:1) 知识点表示:使用结构化的知识图谱来表示知识点。2) 例题选择策略:根据知识点的难度和覆盖范围选择合适的例题。3) 教学策略:LLM可以采用不同的教学策略,例如讲解知识点、提供例题、进行提问等。4) 评估指标:使用学生在教学前后的测试成绩差异作为评估指标。具体的参数设置、损失函数、网络结构等技术细节在论文中没有详细描述,属于未知的实现细节。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同LLM在不同学科的教学效果存在显著差异。例如,某些模型在数学方面表现良好,但在物理和化学方面的教学仍然具有挑战性。此外,实验还发现,加入例题并不一定能提高教学效果,因为模型有时会过度关注特定例子的错误纠正。这些结果表明,教学能力是LLM行为中一个独特且可衡量的维度。
🎯 应用场景
该研究成果可应用于开发智能教学系统、个性化学习平台和虚拟辅导助手。通过评估和优化LLM的教学能力,可以提升在线教育的质量和效率,为学生提供更加个性化和有效的学习体验。此外,该框架还可以用于评估不同LLM在教育领域的应用潜力,为教育资源的合理分配提供依据。
📄 摘要(原文)
Large language models (LLMs) show promise as teaching assistants, yet their teaching capability remains insufficiently evaluated. Existing benchmarks mainly focus on problem-solving or problem-level guidance, leaving knowledge-centered teaching underexplored. We propose a syllabus-grounded evaluation framework that measures LLM teaching capability via student performance improvement after multi-turn instruction. By restricting teacher agents to structured knowledge points and example problems, the framework avoids information leakage and enables reuse of existing benchmarks. We instantiate the framework on Gaokao data across multiple subjects. Experiments reveal substantial variation in teaching effectiveness across models and domains: some models perform well in mathematics, while teaching remains challenging in physics and chemistry. We also find that incorporating example problems does not necessarily improve teaching, as models often shift toward example-specific error correction. Overall, our results highlight teaching ability as a distinct and measurable dimension of LLM behavior.