Ostrakon-VL: Towards Domain-Expert MLLM for Food-Service and Retail Stores
作者: Zhiyong Shen, Gongpeng Zhao, Jun Zhou, Li Yu, Guandong Kou, Jichen Li, Chuanlei Dong, Zuncheng Li, Kaimao Li, Bingkun Wei, Shicheng Hu, Wei Xia, Wenguo Duan
分类: cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出面向餐饮和零售场景的领域专家多模态大语言模型Ostrakon-VL
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 餐饮零售场景 数据管理 领域自适应 基准测试
📋 核心要点
- 现有MLLM在餐饮零售场景应用受限,主要由于数据噪声大、缺乏高质量训练语料,以及缺少统一的评估基准。
- 论文提出Ostrakon-VL,一个面向餐饮零售场景的MLLM,并设计了QUAD数据管理流程,提升数据质量。
- 实验结果表明,Ostrakon-VL在ShopBench基准上超越了同等规模甚至更大规模的开源MLLM,展现了优越的性能。
📝 摘要(中文)
多模态大语言模型(MLLMs)在通用感知和推理方面取得了显著进展。然而,它们在餐饮服务和零售商店(FSRS)场景中的部署面临两个主要障碍:(i)从异构采集设备收集的真实FSRS数据噪声大,缺乏可审计的闭环数据管理,阻碍了高质量、可控和可复现的训练语料库的构建;(ii)现有的评估协议没有提供统一、细粒度和标准化的基准,涵盖单图像、多图像和视频输入,使得客观评估模型的鲁棒性具有挑战性。为了解决这些挑战,我们首先开发了基于Qwen3-VL-8B的面向FSRS的MLLM——Ostrakon-VL。其次,我们推出了ShopBench,这是第一个用于FSRS的公共基准。第三,我们提出了QUAD(质量感知的无偏自动化数据管理),这是一个多阶段多模态指令数据管理流程。通过多阶段训练策略,Ostrakon-VL在ShopBench上取得了60.1的平均分,在具有可比参数规模和不同架构的开源MLLM中建立了新的最先进水平。值得注意的是,它超过了规模更大的Qwen3-VL-235B-A22B(59.4),提升了+0.7,并超过了相同规模的Qwen3-VL-8B(55.3),提升了+4.8,表明参数效率显著提高。这些结果表明,Ostrakon-VL提供了更强大和可靠的以FSRS为中心的感知和决策能力。为了方便可复现的研究,我们将公开发布Ostrakon-VL和ShopBench基准。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型在餐饮服务和零售商店(FSRS)场景中应用时遇到的数据质量和评估标准问题。现有方法在处理真实场景的噪声数据时表现不佳,且缺乏统一的评估基准来客观衡量模型性能。
核心思路:论文的核心思路是构建一个领域专家MLLM,通过高质量的数据管理流程和专门设计的评估基准,提升模型在FSRS场景下的感知和决策能力。通过针对性训练,使模型能够更好地理解和处理FSRS场景中的复杂信息。
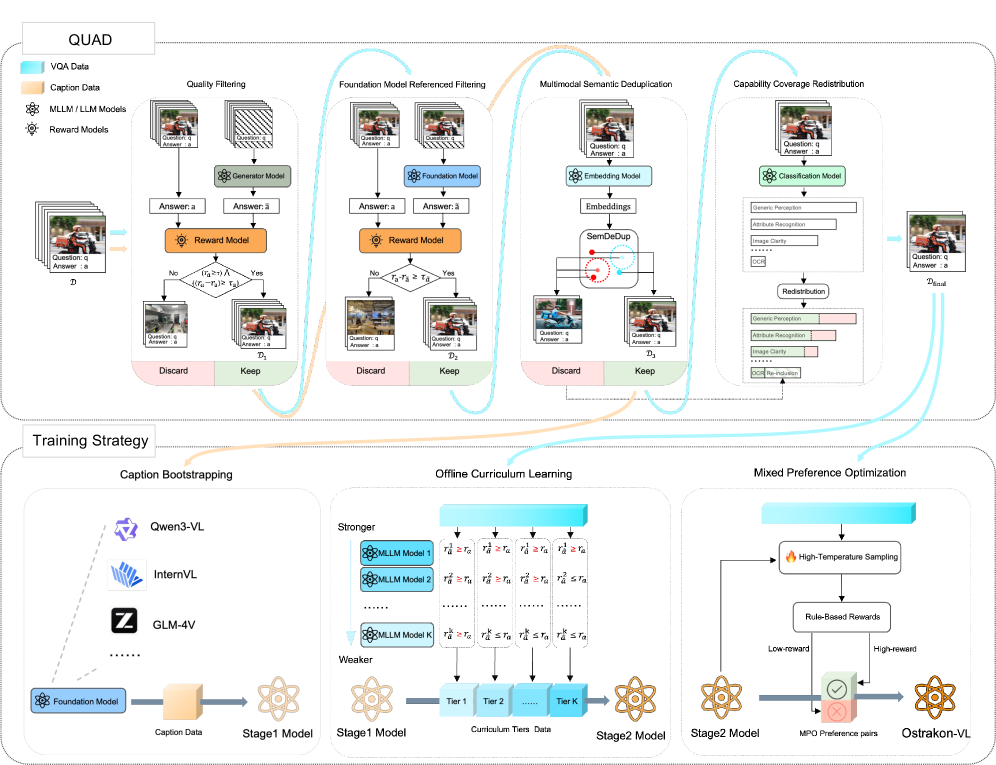
技术框架:Ostrakon-VL的整体框架包括以下几个主要部分:1) 基于Qwen3-VL-8B构建基础模型;2) 提出QUAD(Quality-aware Unbiased Automated Data-curation)多阶段数据管理流程,用于清洗和增强FSRS数据;3) 构建ShopBench基准,用于评估模型在FSRS场景下的性能;4) 采用多阶段训练策略,提升模型性能。
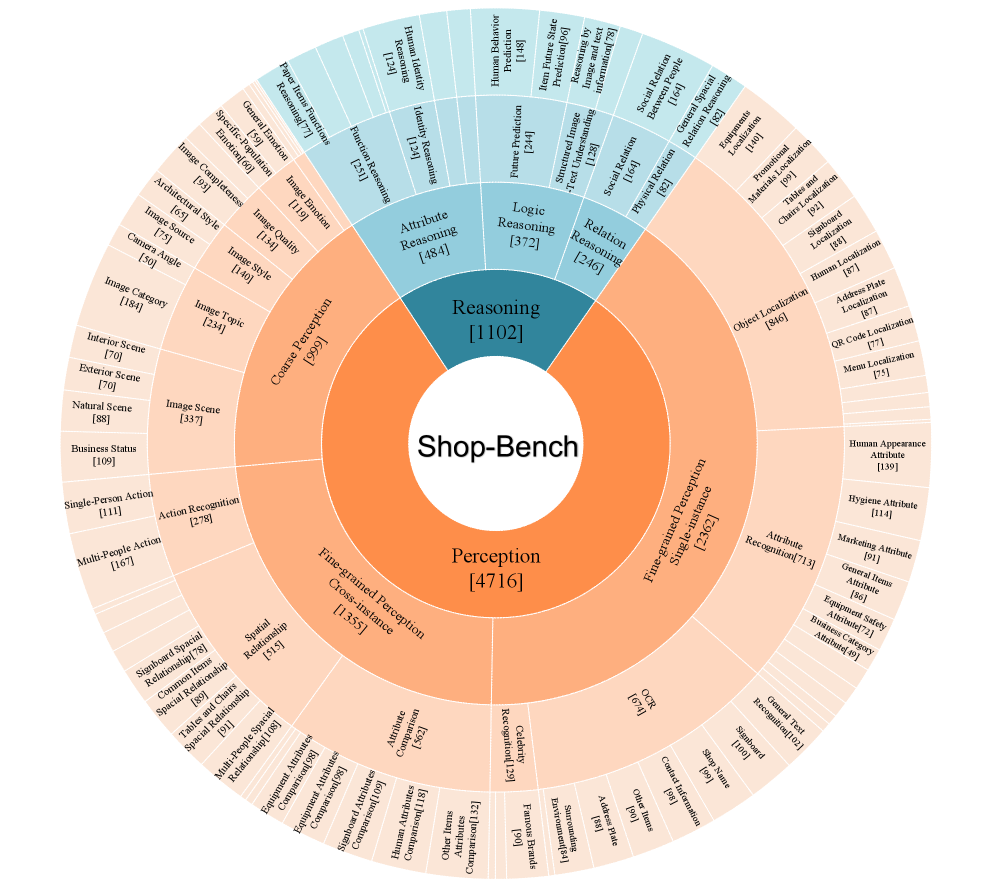
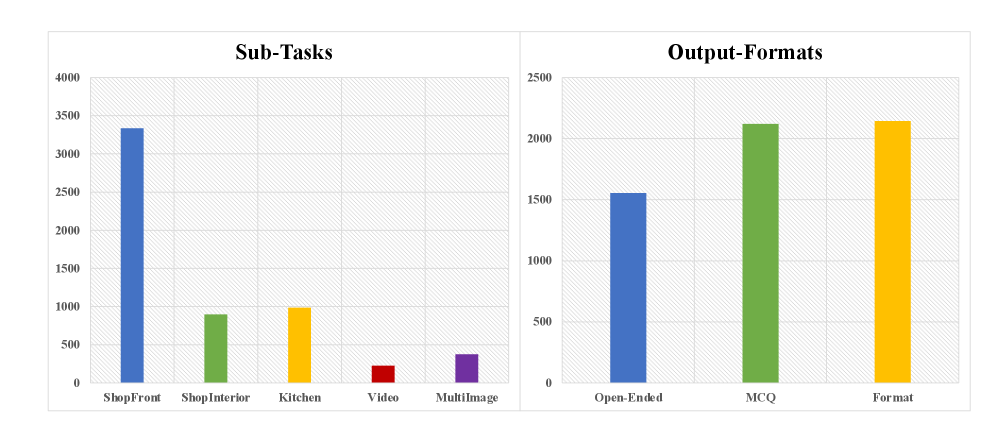
关键创新:论文的关键创新在于QUAD数据管理流程和ShopBench基准的提出。QUAD流程能够有效地处理FSRS场景中的噪声数据,生成高质量的训练数据。ShopBench基准提供了一个统一、细粒度和标准化的评估平台,可以客观地衡量模型在FSRS场景下的性能。
关键设计:QUAD数据管理流程包含多个阶段,例如数据清洗、数据增强和数据筛选等。具体的技术细节包括使用预训练模型进行数据质量评估,并根据评估结果进行数据过滤和修正。多阶段训练策略可能包括预训练、微调和领域自适应等步骤,以逐步提升模型在FSRS场景下的性能。具体的损失函数和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
Ostrakon-VL在ShopBench基准上取得了60.1的平均分,超越了同等规模的Qwen3-VL-8B(55.3),提升了+4.8,甚至超过了规模更大的Qwen3-VL-235B-A22B(59.4),提升了+0.7。这些结果表明,Ostrakon-VL在参数效率和性能方面都具有显著优势。
🎯 应用场景
该研究成果可应用于智能零售、餐饮服务等领域,例如智能货架识别、自动结算、顾客行为分析、食品安全监控等。通过提升模型在特定场景下的感知和决策能力,可以提高运营效率、降低成本、改善用户体验,并为商业决策提供数据支持。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have recently achieved substantial progress in general-purpose perception and reasoning. Nevertheless, their deployment in Food-Service and Retail Stores (FSRS) scenarios encounters two major obstacles: (i) real-world FSRS data, collected from heterogeneous acquisition devices, are highly noisy and lack auditable, closed-loop data curation, which impedes the construction of high-quality, controllable, and reproducible training corpora; and (ii) existing evaluation protocols do not offer a unified, fine-grained and standardized benchmark spanning single-image, multi-image, and video inputs, making it challenging to objectively gauge model robustness. To address these challenges, we first develop Ostrakon-VL, an FSRS-oriented MLLM based on Qwen3-VL-8B. Second, we introduce ShopBench, the first public benchmark for FSRS. Third, we propose QUAD (Quality-aware Unbiased Automated Data-curation), a multi-stage multimodal instruction data curation pipeline. Leveraging a multi-stage training strategy, Ostrakon-VL achieves an average score of 60.1 on ShopBench, establishing a new state of the art among open-source MLLMs with comparable parameter scales and diverse architectures. Notably, it surpasses the substantially larger Qwen3-VL-235B-A22B (59.4) by +0.7, and exceeds the same-scale Qwen3-VL-8B (55.3) by +4.8, demonstrating significantly improved parameter efficiency. These results indicate that Ostrakon-VL delivers more robust and reliable FSRS-centric perception and decision-making capabilities. To facilitate reproducible research, we will publicly release Ostrakon-VL and the ShopBench benchmark.