Within-Model vs Between-Prompt Variability in Large Language Models for Creative Tasks
作者: Jennifer Haase, Jana Gonnermann-Müller, Paul H. P. Hanel, Nicolas Leins, Thomas Kosch, Jan Mendling, Sebastian Pokutta
分类: cs.AI
发布日期: 2026-01-29
💡 一句话要点
分析LLM在创意任务中提示与模型选择对输出方差的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 创意任务 提示工程 方差分析 输出质量 输出数量 模型评估
📋 核心要点
- 现有研究缺乏对LLM输出方差来源的系统分析,难以区分提示、模型和随机性的影响。
- 通过大规模实验,分析提示、模型选择和采样随机性对LLM输出质量和数量的影响。
- 实验表明,提示对输出质量影响显著,但LLM内部方差不可忽视,单样本评估存在风险。
📝 摘要(中文)
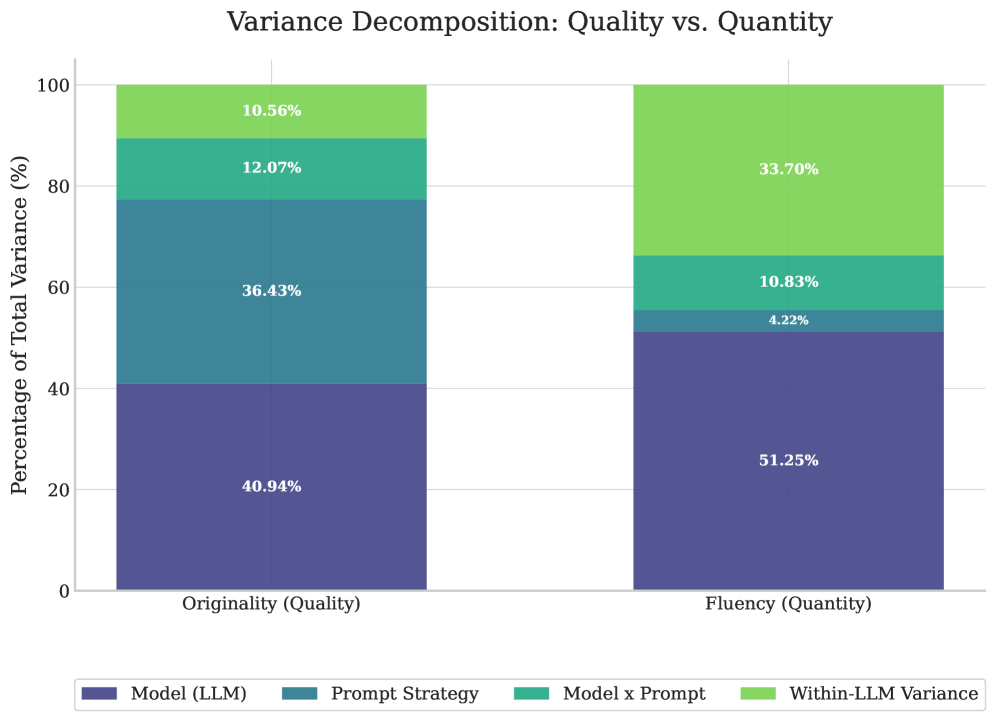
本文研究了大型语言模型(LLM)在创意任务中,提示、模型选择以及采样随机性对输出方差的影响程度。通过评估12个LLM在10个创意提示下的100个样本(N = 12,000),发现对于输出质量(原创性),提示解释了36.43%的方差,与模型选择(40.94%)相当。然而,对于输出数量(流畅性),模型选择(51.25%)和LLM内部方差(33.70%)占据主导,而提示仅解释了4.22%。提示是控制输出质量的有力工具,但考虑到LLM内部存在显著的方差(10-34%),单样本评估可能将采样噪声与真实的提示或模型效应混淆。
🔬 方法详解
问题定义:现有方法在评估大型语言模型(LLM)的创意能力时,往往难以区分是由提示工程、模型本身还是随机采样带来的输出差异。这使得我们难以准确评估不同提示或模型的优劣,也难以理解LLM生成过程中的内在机制。现有研究缺乏对这些因素的系统性分析,容易将采样噪声误判为提示或模型的效果。
核心思路:本文的核心思路是通过大规模的实验设计,系统性地分析提示、模型选择和LLM内部方差(即采样随机性)对输出质量(原创性)和数量(流畅性)的影响。通过方差分析,量化每个因素对输出方差的贡献,从而揭示LLM生成过程中的关键影响因素。
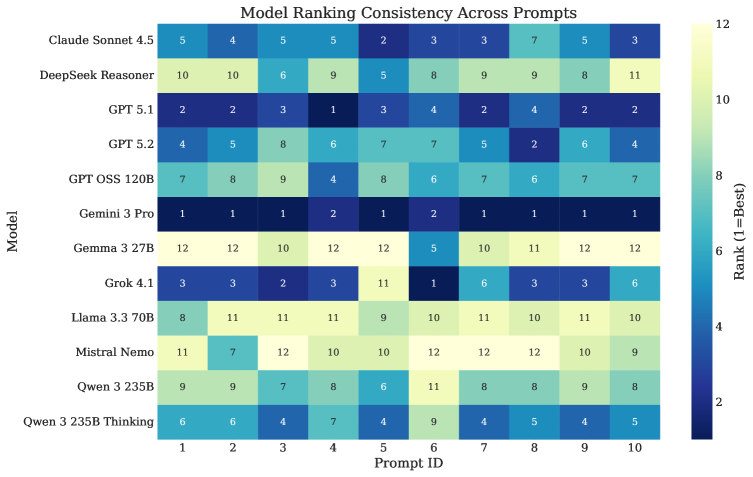
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 选择LLM和创意提示:选取12个具有代表性的大型语言模型,并设计10个不同的创意提示。 2. 生成样本:对于每个LLM和每个提示,生成100个输出样本,从而获得总共12,000个样本。 3. 评估输出:使用合适的指标评估每个样本的输出质量(原创性)和数量(流畅性)。 4. 方差分析:使用方差分析(ANOVA)来量化提示、模型选择和LLM内部方差对输出方差的贡献。
关键创新:该研究的关键创新在于其系统性的实验设计和方差分析方法,能够量化不同因素对LLM输出方差的贡献。这使得研究者能够更准确地评估提示和模型的效果,并更好地理解LLM的生成过程。此外,该研究强调了LLM内部方差的重要性,指出单样本评估可能存在风险。
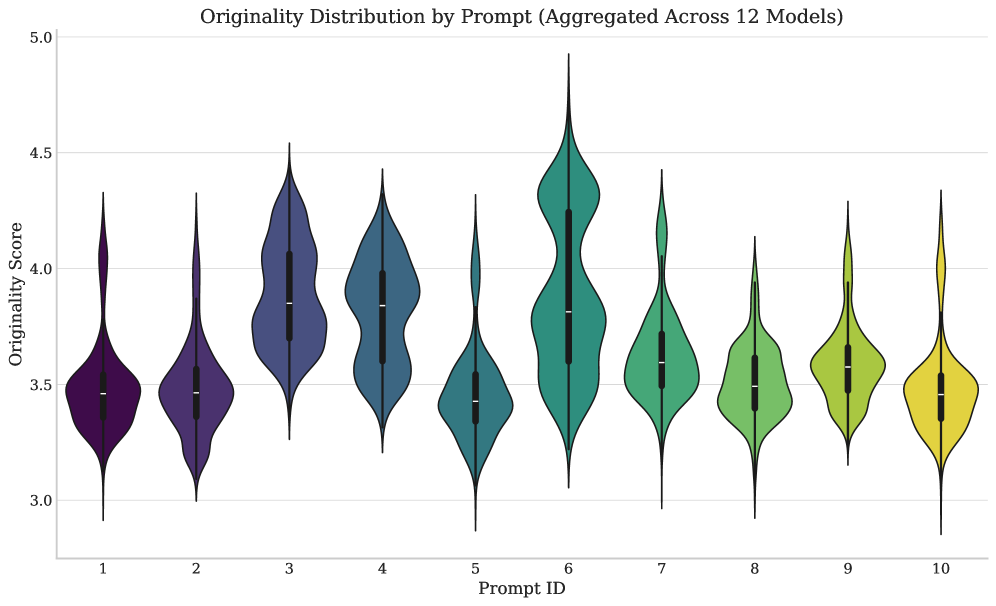
关键设计:该研究的关键设计包括: * 大规模样本:每个LLM和提示生成100个样本,保证了方差分析的统计效力。 * 多样化的提示:选择10个不同的创意提示,覆盖了不同的创意任务。 * 方差分析方法:使用方差分析来量化不同因素的贡献,能够有效地分离不同因素的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,对于输出质量(原创性),提示解释了36.43%的方差,与模型选择(40.94%)相当。而对于输出数量(流畅性),模型选择(51.25%)和LLM内部方差(33.70%)占据主导,提示仅解释了4.22%。这表明提示是控制输出质量的有力工具,但LLM内部方差不可忽视。
🎯 应用场景
该研究成果可应用于LLM的评估和优化。开发者可以更好地理解提示工程对输出质量的影响,从而设计更有效的提示。同时,研究结果也提醒研究者在评估LLM时,应考虑LLM内部方差,避免单样本评估带来的偏差。此外,该研究为LLM在创意领域的应用提供了指导,有助于开发更具创造力的LLM应用。
📄 摘要(原文)
How much of LLM output variance is explained by prompts versus model choice versus stochasticity through sampling? We answer this by evaluating 12 LLMs on 10 creativity prompts with 100 samples each (N = 12,000). For output quality (originality), prompts explain 36.43% of variance, comparable to model choice (40.94%). But for output quantity (fluency), model choice (51.25%) and within-LLM variance (33.70%) dominate, with prompts explaining only 4.22%. Prompts are powerful levers for steering output quality, but given the substantial within-LLM variance (10-34%), single-sample evaluations risk conflating sampling noise with genuine prompt or model effects.