More Code, Less Reuse: Investigating Code Quality and Reviewer Sentiment towards AI-generated Pull Requests
作者: Haoming Huang, Pongchai Jaisri, Shota Shimizu, Lingfeng Chen, Sota Nakashima, Gema Rodríguez-Pérez
分类: cs.SE, cs.AI, cs.HC
发布日期: 2026-01-29
备注: Accepted to MSR 2026
💡 一句话要点
研究表明AI生成的Pull Request代码质量较低,但评审者情绪更积极
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 代码质量 情绪分析 技术债务
📋 核心要点
- 现有评估LLM生成代码的方法侧重于通过率,忽略了代码质量、可维护性以及人类开发者的主观感受。
- 该研究通过代码指标分析LLM生成代码的质量,并进行情绪分析,评估开发者对LLM生成PR的反应。
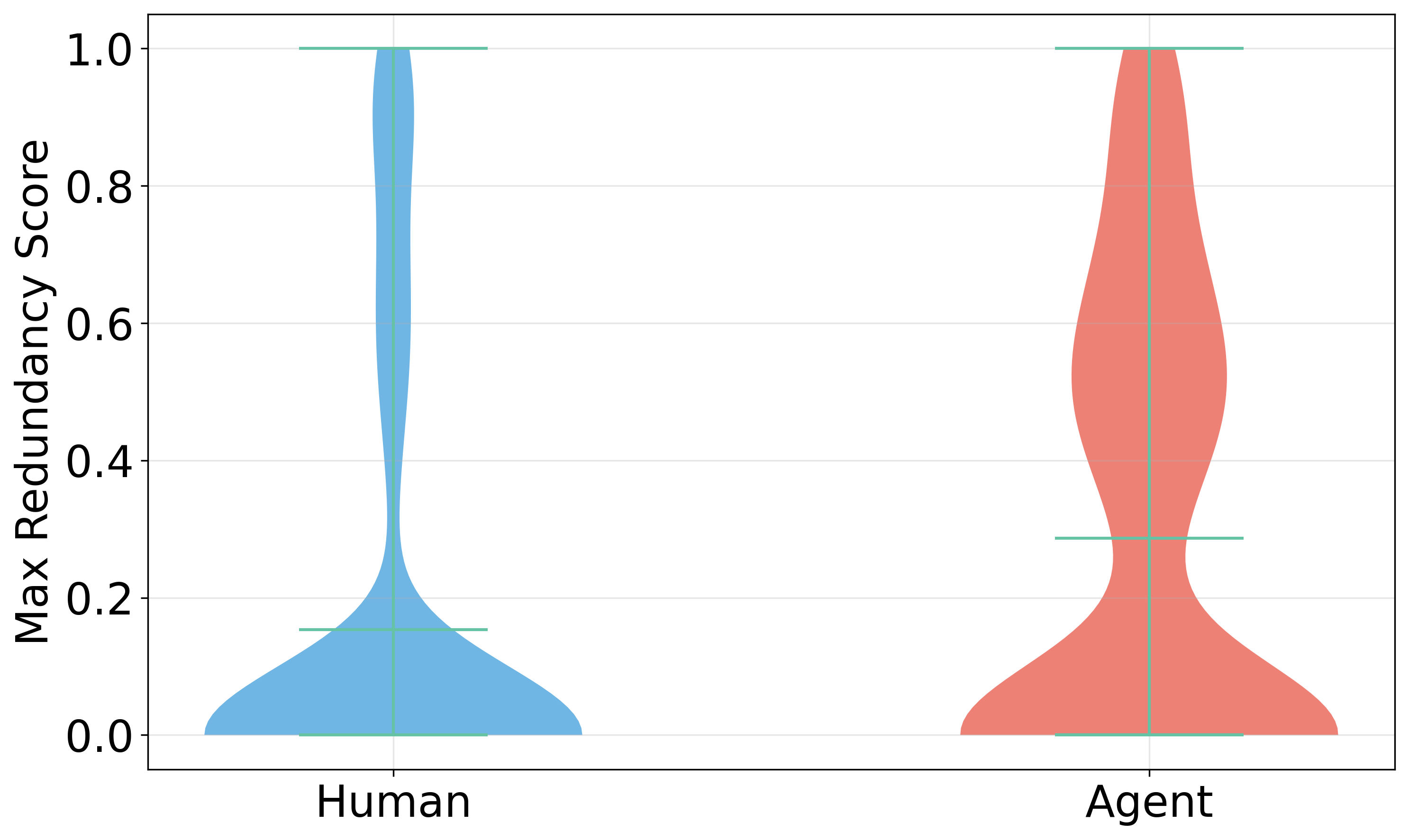
- 实验结果表明,LLM生成代码冗余度较高,但开发者对其评价更积极,暗示了技术债务累积的风险。
📝 摘要(中文)
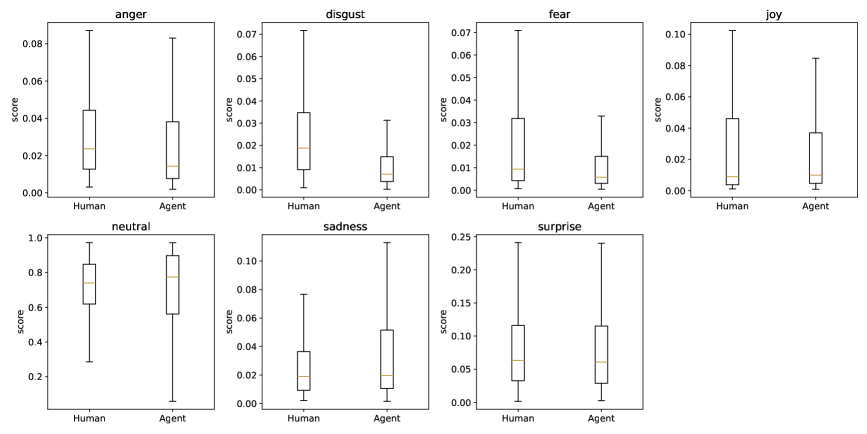
大型语言模型(LLM)Agent正快速发展,越来越多地被用于代码生成等开发任务。虽然LLM Agent加速了代码生成,但研究表明它们可能对开发产生不利影响。然而,现有的评估指标仅衡量通过率,未能反映对长期可维护性和可读性的影响,也未能捕捉人类对PR的直观评价。为了更全面地了解这个问题,我们研究并评估了LLM的特性,以了解PR中除通过率之外的特征。我们基于代码指标观察PR中的代码质量和可维护性,以评估客观特征,并评估开发人员对人类和LLM生成的pull request的反应。评估结果表明,LLM Agent经常忽略代码重用机会,导致比人类开发人员更高的冗余度。与质量问题相反,我们的情绪分析显示,评审者倾向于对AI生成的贡献表达更中性或积极的情绪。这种脱节表明,AI代码的表面合理性掩盖了冗余,导致技术债务在实际开发环境中悄然积累。我们的研究为改善人机协作提供了见解。
🔬 方法详解
问题定义:现有评估LLM生成代码的指标主要关注功能性,即代码是否能通过测试,而忽略了代码质量、可维护性以及开发者对代码的主观感受。这导致无法全面评估LLM在软件开发中的影响,可能掩盖潜在的技术债务风险。
核心思路:该研究的核心思路是通过结合客观的代码质量指标和主观的情绪分析,更全面地评估LLM生成代码的优缺点。通过分析代码的冗余度、复杂度等指标,以及开发者对PR的情绪表达,揭示LLM生成代码的潜在问题。
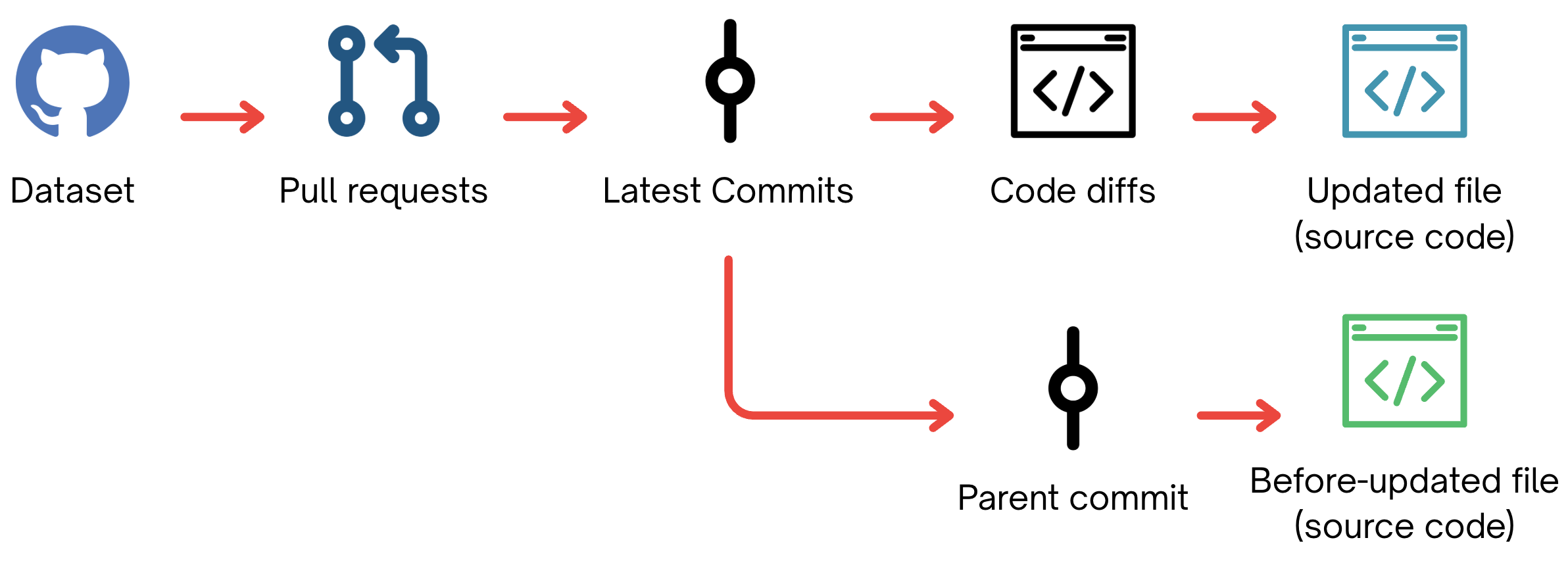
技术框架:该研究主要分为两个部分:代码质量评估和情绪分析。代码质量评估部分,使用代码指标(如代码重复率、圈复杂度等)来衡量LLM和人类开发者生成的代码质量。情绪分析部分,分析开发者在代码评审过程中对LLM和人类开发者提交的PR的情绪表达。
关键创新:该研究的关键创新在于将代码质量的客观评估与开发者情绪的主观评估相结合,从而更全面地了解LLM生成代码的优缺点。这种综合评估方法能够揭示仅通过功能性测试难以发现的问题,例如LLM生成代码的冗余性和潜在的技术债务风险。
关键设计:研究中使用的代码指标包括代码重复率、圈复杂度、代码行数等,这些指标用于衡量代码的冗余度、复杂度和可维护性。情绪分析采用自然语言处理技术,分析开发者在代码评审过程中使用的词语和表达方式,判断其情绪倾向(如积极、消极、中性)。具体的情绪分析模型和参数设置在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM Agent生成的代码冗余度明显高于人类开发者,表明LLM在代码重用方面存在不足。然而,评审者对AI生成的PR表达的情绪更偏向中性或积极,这可能导致开发者忽略AI代码中存在的潜在问题,从而积累技术债务。
🎯 应用场景
该研究成果可应用于改进LLM辅助代码生成的工具和流程,帮助开发者更好地利用LLM提高开发效率,同时避免引入技术债务。此外,该研究也为评估其他AI生成内容的质量提供了参考,例如AI生成的文档、设计等。
📄 摘要(原文)
Large Language Model (LLM) Agents are advancing quickly, with the increasing leveraging of LLM Agents to assist in development tasks such as code generation. While LLM Agents accelerate code generation, studies indicate they may introduce adverse effects on development. However, existing metrics solely measure pass rates, failing to reflect impacts on long-term maintainability and readability, and failing to capture human intuitive evaluations of PR. To increase the comprehensiveness of this problem, we investigate and evaluate the characteristics of LLM to know the pull requests' characteristics beyond the pass rate. We observe the code quality and maintainability within PRs based on code metrics to evaluate objective characteristics and developers' reactions to the pull requests from both humans and LLM's generation. Evaluation results indicate that LLM Agents frequently disregard code reuse opportunities, resulting in higher levels of redundancy compared to human developers. In contrast to the quality issues, our emotions analysis reveals that reviewers tend to express more neutral or positive emotions towards AI-generated contributions than human ones. This disconnect suggests that the surface-level plausibility of AI code masks redundancy, leading to the silent accumulation of technical debt in real-world development environments. Our research provides insights for improving human-AI collaboration.