Do Reasoning Models Enhance Embedding Models?
作者: Wun Yu Chan, Shaojin Chen, Huihao Jing, Kwun Hang Lau, Elton Chun-Chai Li, Zihao Wang, Haoran Li, Yangqiu Song
分类: cs.AI, cs.CL
发布日期: 2026-01-29
备注: 10 main pages, 18 appendix pages, 13 figures, 11 tables, 4 prompts
💡 一句话要点
研究表明,基于RLVR训练的推理模型并不能显著提升Embedding模型的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Embedding模型 强化学习 推理模型 对比学习 语义表示 流形重对齐 HRSA分析 大型语言模型
📋 核心要点
- 现有Embedding模型依赖于对比学习调整的LLM,但RLVR训练的推理模型能否进一步提升Embedding性能是未知的。
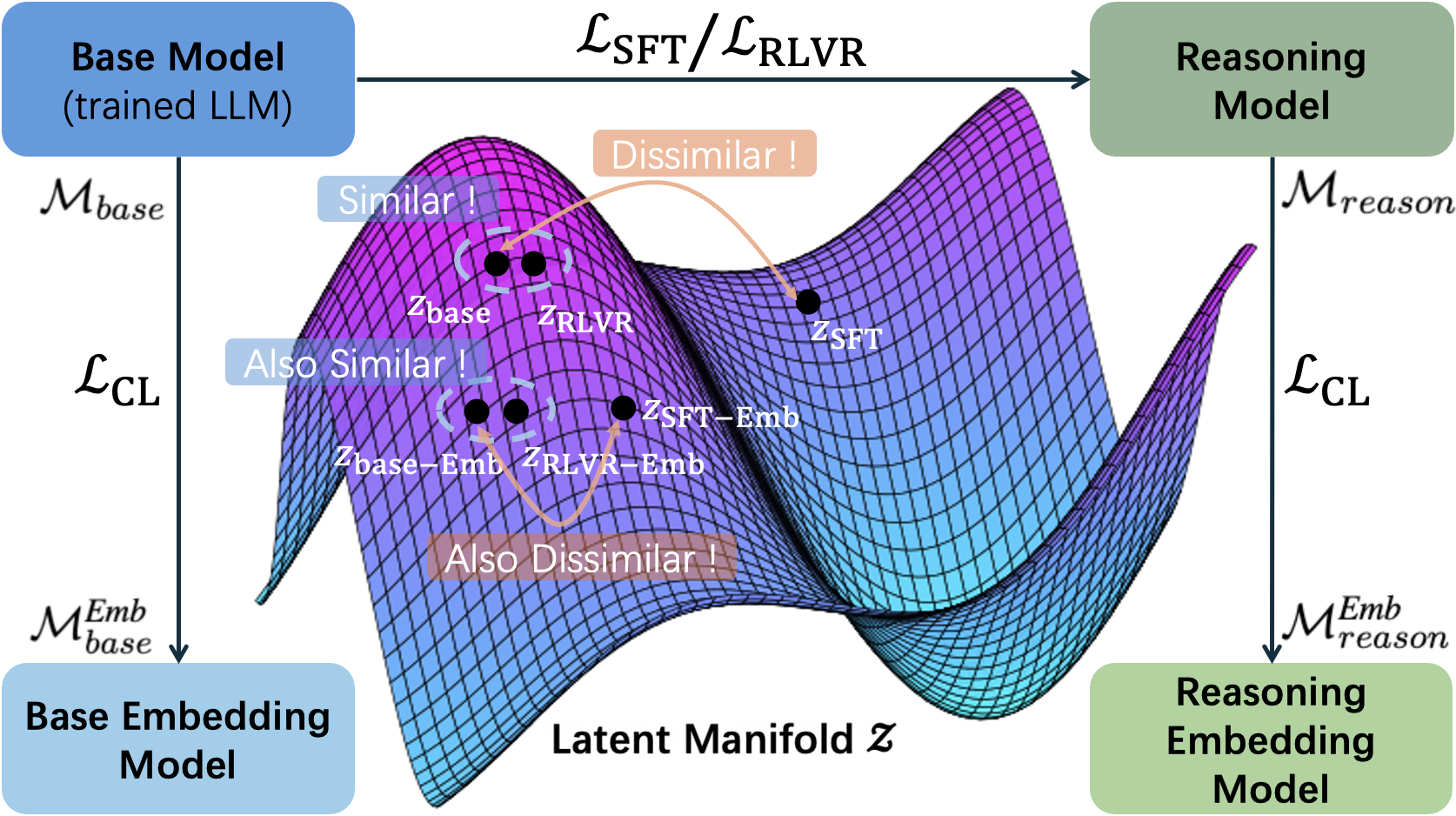
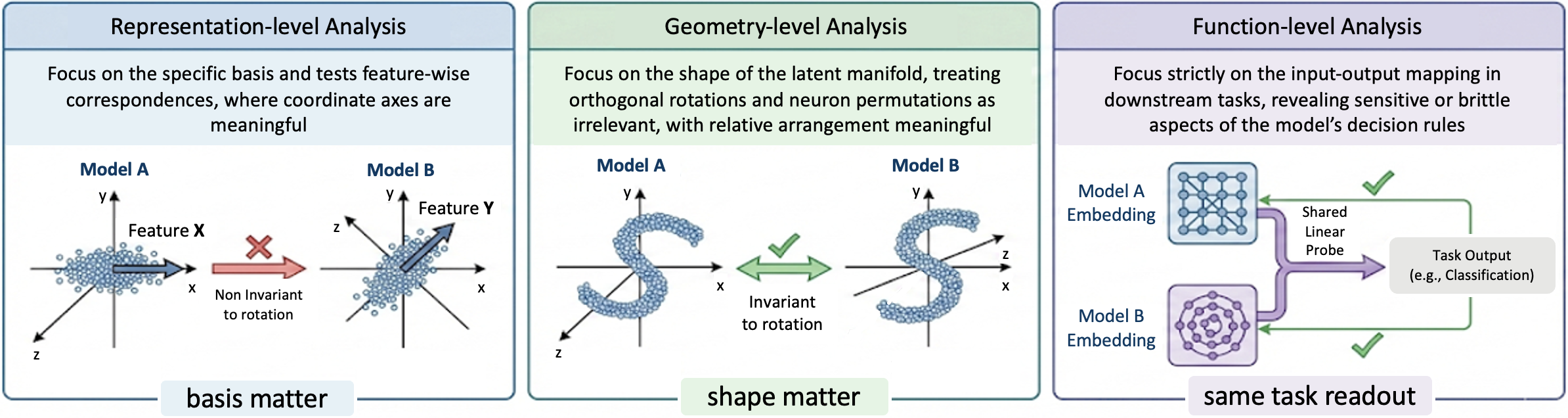
- 论文提出分层表示相似性分析(HRSA)框架,从表示、几何和功能层面分解相似性,以分析RLVR的影响。
- 实验表明,RLVR初始化并未带来显著性能提升,HRSA分析揭示了流形重对齐现象,即对比学习使模型对齐。
📝 摘要(中文)
目前最先进的Embedding模型越来越多地源于decoder-only的大型语言模型(LLM),这些模型通过对比学习进行调整。随着通过可验证奖励的强化学习(RLVR)训练的推理模型的出现,一个自然而然的问题是:当这些模型作为Embedding初始化时,增强的推理能力是否能转化为更优越的语义表示?与预期相反,我们在MTEB和BRIGHT上的评估显示了一个无效结果:当使用相同的训练方法时,从RLVR调整后的backbone初始化的Embedding模型并没有比其基础模型产生一致的性能优势。为了解释这个悖论,我们引入了Hierarchical Representation Similarity Analysis (HRSA),这是一个将相似性分解为表示、几何和功能级别的框架。HRSA表明,虽然RLVR会引起不可逆的潜在流形的局部几何重组和可逆的坐标基漂移,但它保留了全局流形几何和线性读出。因此,随后的对比学习驱动了基础模型和推理初始化模型之间的强对齐,我们称之为流形重对齐现象。从经验上看,我们的发现表明,与监督微调(SFT)不同,RLVR优化了现有语义环境中的轨迹,而不是从根本上重构环境本身。
🔬 方法详解
问题定义:论文旨在研究使用通过RLVR训练的推理模型作为Embedding模型的初始化,是否能够提升Embedding模型的性能。现有方法主要依赖于对比学习微调的LLM,但缺乏对RLVR训练的推理模型对Embedding空间影响的深入理解,以及其能否带来性能提升的有效评估。
核心思路:论文的核心思路是,通过实验发现RLVR初始化并未带来性能提升,并提出HRSA框架来分析其原因。HRSA将相似性分解为表示、几何和功能层面,从而揭示RLVR对Embedding空间的影响,以及对比学习如何使模型对齐。
技术框架:论文的技术框架主要包括以下几个阶段: 1. 使用RLVR训练推理模型。 2. 使用RLVR训练的推理模型作为Embedding模型的初始化。 3. 使用对比学习训练Embedding模型。 4. 使用MTEB和BRIGHT数据集评估Embedding模型的性能。 5. 使用HRSA框架分析RLVR对Embedding空间的影响。
关键创新:论文的关键创新在于: 1. 发现RLVR初始化并未带来显著的Embedding性能提升,这与直觉相反。 2. 提出HRSA框架,从表示、几何和功能层面分析RLVR对Embedding空间的影响,揭示了流形重对齐现象。 3. 证明RLVR优化了现有语义环境中的轨迹,而不是从根本上重构环境本身,这与SFT不同。
关键设计:HRSA框架的关键设计包括: 1. 表示相似性:计算不同模型输出的Embedding向量之间的相似度。 2. 几何相似性:分析潜在流形的局部和全局几何结构,例如使用PCA降维后计算距离。 3. 功能相似性:评估模型在特定任务上的表现,例如使用线性分类器进行分类。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用RLVR训练的推理模型初始化Embedding模型,在MTEB和BRIGHT数据集上并没有带来一致的性能提升。HRSA分析揭示,虽然RLVR会改变局部几何结构,但对比学习会使模型发生流形重对齐,最终性能与基础模型相似。
🎯 应用场景
该研究成果有助于理解RLVR训练对语义表示的影响,并指导未来Embedding模型的初始化策略。它可以应用于信息检索、文本分类、语义相似度计算等领域,帮助研究人员更有效地利用推理模型提升Embedding模型的性能。
📄 摘要(原文)
State-of-the-art embedding models are increasingly derived from decoder-only Large Language Model (LLM) backbones adapted via contrastive learning. Given the emergence of reasoning models trained via Reinforcement Learning with Verifiable Rewards (RLVR), a natural question arises: do enhanced reasoning translate to superior semantic representations when these models serve as embedding initializations? Contrary to expectation, our evaluation on MTEB and BRIGHT reveals a null effect: embedding models initialized from RLVR-tuned backbones yield no consistent performance advantage over their base counterparts when subjected to identical training recipes. To unpack this paradox, we introduce Hierarchical Representation Similarity Analysis (HRSA), a framework that decomposes similarity across representation, geometry, and function levels. HRSA reveals that while RLVR induces irreversible latent manifold's local geometry reorganization and reversible coordinate basis drift, it preserves the global manifold geometry and linear readout. Consequently, subsequent contrastive learning drives strong alignment between base- and reasoning-initialized models, a phenomenon we term Manifold Realignment. Empirically, our findings suggest that unlike Supervised Fine-Tuning (SFT), RLVR optimizes trajectories within an existing semantic landscape rather than fundamentally restructuring the landscape itself.