SokoBench: Evaluating Long-Horizon Planning and Reasoning in Large Language Models
作者: Sebastiano Monti, Carlo Nicolini, Gianni Pellegrini, Jacopo Staiano, Bruno Lepri
分类: cs.AI
发布日期: 2026-01-28
💡 一句话要点
SokoBench:评估大语言模型在长程规划和推理中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长程规划 大语言模型 推理能力 基准测试 推箱子游戏
📋 核心要点
- 现有方法在复杂推理任务上测试了大语言模型的能力,但对它们的长程规划能力的研究不足。
- 论文提出了SokoBench基准,通过简化推箱子游戏来隔离长程规划能力,从而进行更精确的评估。
- 实验表明,当规划步数超过25步时,模型性能显著下降,且即使引入PDDL工具也只能带来有限的提升。
📝 摘要(中文)
本文旨在系统性地评估当前先进的大型推理模型(LRM)在规划和长程推理方面的能力。为此,作者提出了一个基于推箱子游戏的全新基准测试SokoBench,该基准有意简化了游戏规则,以将长程规划与状态持久性隔离开来。实验结果表明,当达到解决方案所需的步数超过25步时,规划性能会持续下降,这表明了前向规划能力存在根本性的约束。研究还发现,为LRM配备规划领域定义语言(PDDL)解析、验证和求解工具可以带来适度的改进,这暗示了模型存在固有的架构限制,可能无法仅通过测试时扩展方法来克服。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在长程规划和推理方面的能力。现有方法难以有效评估LLM的长程规划能力,因为它们通常受到状态持久性等其他因素的干扰,使得评估结果不够纯粹。推箱子游戏需要进行多步规划才能解决,但其状态空间相对简单,适合作为评估长程规划能力的基准。
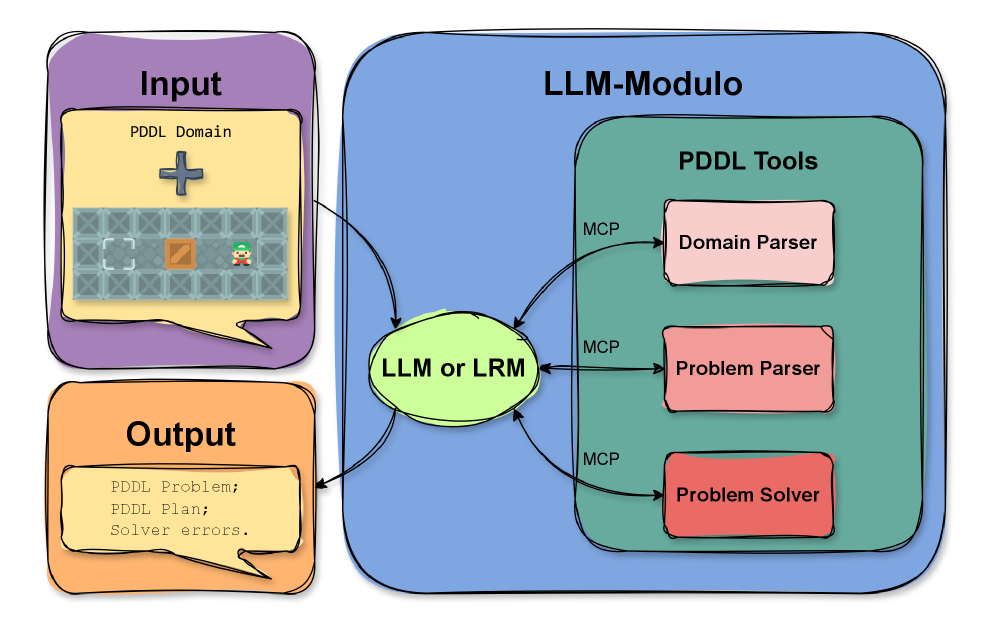
核心思路:论文的核心思路是设计一个简化的推箱子游戏基准测试(SokoBench),以隔离和评估LLM的长程规划能力。通过简化游戏规则,可以减少状态持久性等因素的干扰,从而更准确地评估LLM在长程规划方面的表现。此外,论文还尝试将规划领域定义语言(PDDL)工具集成到LLM中,以提高其规划能力。
技术框架:整体框架包括以下几个主要步骤:1) 构建SokoBench基准测试,包括一系列不同难度的推箱子游戏关卡;2) 使用LLM生成推箱子游戏的解决方案;3) 评估LLM生成的解决方案的质量,例如,解决方案是否有效、解决方案的步数等;4) 将PDDL解析、验证和求解工具集成到LLM中,并重新评估其规划能力。
关键创新:论文的关键创新在于提出了SokoBench基准测试,该基准测试专门用于评估LLM的长程规划能力。与现有基准测试相比,SokoBench更加关注长程规划,并减少了其他因素的干扰。此外,论文还探索了将PDDL工具集成到LLM中以提高其规划能力的方法。
关键设计:SokoBench基准测试中的推箱子游戏关卡经过精心设计,以确保其难度适中,并且能够有效地评估LLM的长程规划能力。论文还详细描述了如何将PDDL工具集成到LLM中,包括如何将推箱子游戏的状态表示为PDDL问题,以及如何使用PDDL求解器生成解决方案。具体的参数设置、损失函数、网络结构等技术细节在论文中没有详细说明,可能使用了标准的LLM架构和训练方法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,当解决推箱子游戏所需的步数超过25步时,LLM的规划性能会显著下降。即使为LLM配备PDDL工具,也只能带来有限的性能提升,这表明LLM在长程规划方面存在固有的架构限制。例如,在某些实验设置下,使用PDDL工具后,解决问题的成功率仅提升了5%-10%。
🎯 应用场景
该研究成果可应用于评估和改进大语言模型在需要长程规划的实际任务中的表现,例如机器人导航、任务调度、游戏AI等领域。通过SokoBench基准测试,可以更好地了解LLM的规划能力瓶颈,并为开发更强大的规划算法提供指导。未来的研究可以探索如何进一步提高LLM的长程规划能力,例如通过引入更有效的记忆机制或规划算法。
📄 摘要(原文)
Although the capabilities of large language models have been increasingly tested on complex reasoning tasks, their long-horizon planning abilities have not yet been extensively investigated. In this work, we provide a systematic assessment of the planning and long-horizon reasoning capabilities of state-of-the-art Large Reasoning Models (LRMs). We propose a novel benchmark based on Sokoban puzzles, intentionally simplified to isolate long-horizon planning from state persistence. Our findings reveal a consistent degradation in planning performance when more than 25 moves are required to reach the solution, suggesting a fundamental constraint on forward planning capacity. We show that equipping LRMs with Planning Domain Definition Language (PDDL) parsing, validation, and solving tools allows for modest improvements, suggesting inherent architectural limitations which might not be overcome by test-time scaling approaches alone.