Beyond GEMM-Centric NPUs: Enabling Efficient Diffusion LLM Sampling
作者: Binglei Lou, Haoran Wu, Yao Lai, Jiayi Nie, Can Xiao, Xuan Guo, Rika Antonova, Robert Mullins, Aaron Zhao
分类: cs.AR, cs.AI, cs.DC
发布日期: 2026-01-28
💡 一句话要点
针对Diffusion LLM采样,提出超越GEMM中心NPU的加速方案。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Diffusion LLM NPU架构 采样加速 非GEMM计算 内存优化
📋 核心要点
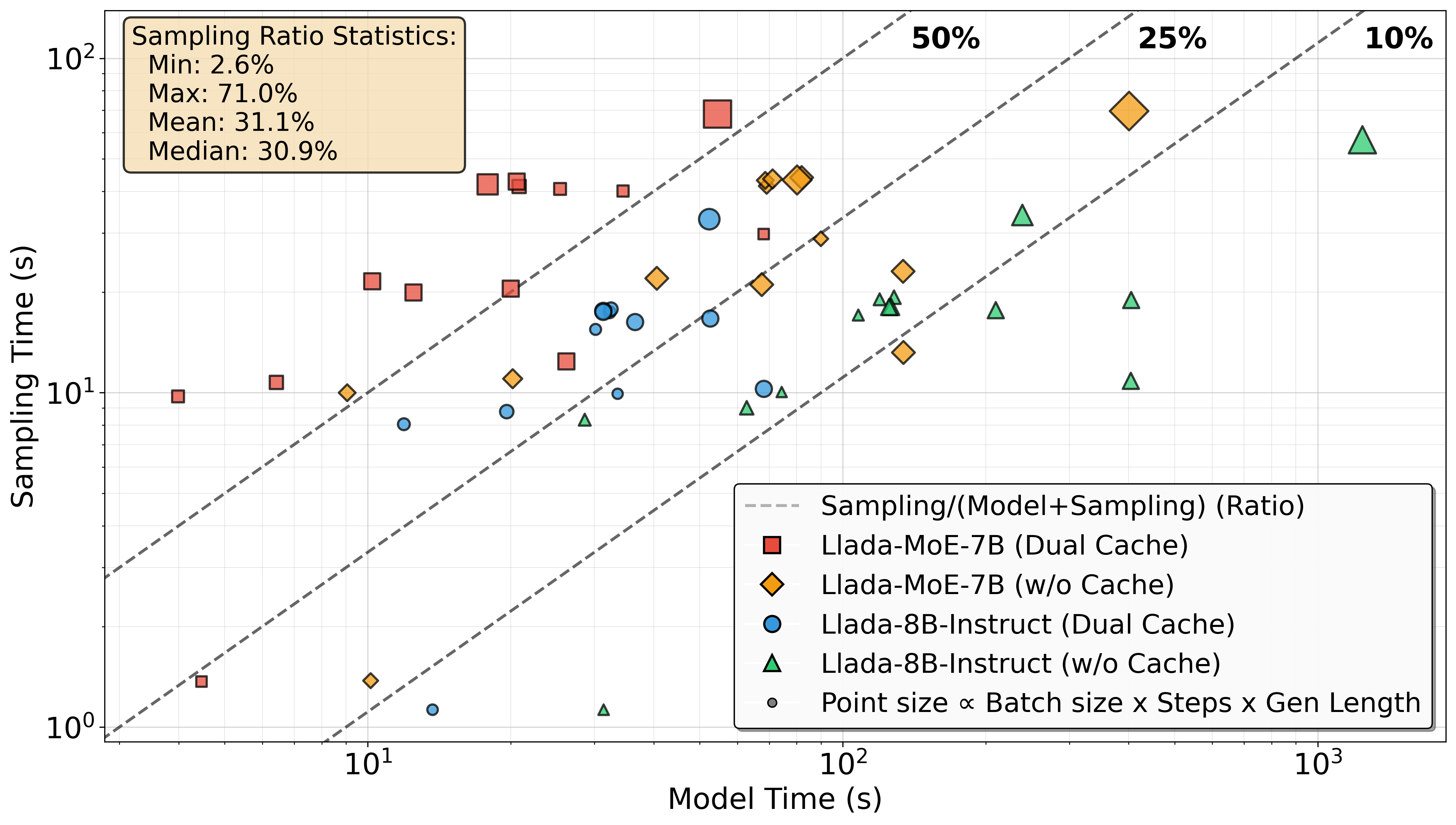
- Diffusion LLM采样阶段因大量内存读写和不规则访问,导致传统NPU效率低下,成为推理瓶颈。
- 设计针对dLLM采样优化的NPU架构,采用非GEMM向量原语、内存重用和混合精度内存层次结构。
- 实验表明,该设计在同等工艺节点下,相比NVIDIA RTX A6000 GPU实现了高达2.53倍的加速。
📝 摘要(中文)
扩散大语言模型(dLLMs)引入迭代去噪以实现并行token生成,但其采样阶段与以GEMM为中心的Transformer层相比,展现出根本不同的特性。在现代GPU上的分析表明,采样可能占总模型推理延迟的70%,这主要是由于词汇表范围logits的大量内存加载和写入、基于归约的token选择以及迭代的掩码更新。这些过程需要大的片上SRAM,并涉及传统NPU难以有效处理的不规则内存访问。为了解决这个问题,我们确定了一组NPU架构必须专门为dLLM采样优化的关键指令。我们的设计采用轻量级的非GEMM向量原语、原地内存重用策略和解耦的混合精度内存层次结构。总之,这些优化在等效nm技术节点下,比NVIDIA RTX A6000 GPU提供了高达2.53倍的加速。我们还开源了我们的周期精确模拟和后综合RTL验证代码,确认了与当前dLLM PyTorch实现的功能等效性。
🔬 方法详解
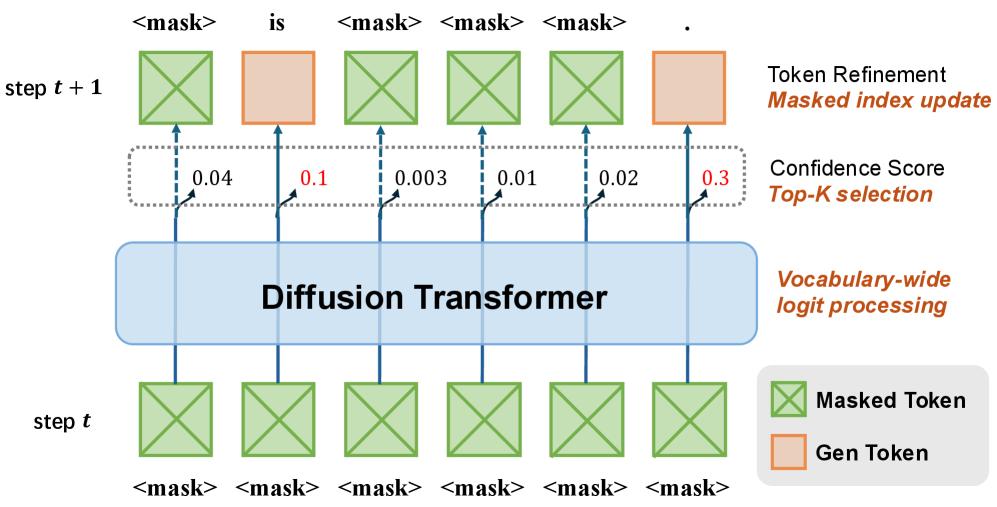
问题定义:Diffusion LLM的采样阶段,例如在生成文本时,需要进行大量的词汇表范围logits计算、token选择以及迭代的掩码更新。这些操作导致了频繁且不规则的内存访问,以及对大容量片上SRAM的需求。传统的NPU架构通常以GEMM(通用矩阵乘法)运算为中心进行优化,难以高效处理这些非GEMM操作,从而导致采样阶段成为推理的瓶颈。现有方法没有充分考虑dLLM采样阶段的特殊性,导致效率低下。
核心思路:论文的核心思路是针对Diffusion LLM采样阶段的特点,设计一种专门优化的NPU架构。该架构避免了以GEMM为中心的传统设计,而是采用轻量级的非GEMM向量原语来加速采样过程中的关键操作。此外,通过原地内存重用策略和解耦的混合精度内存层次结构,进一步减少了内存访问的开销,提高了数据利用率。这样设计的目的是为了更有效地利用硬件资源,从而加速dLLM的采样过程。
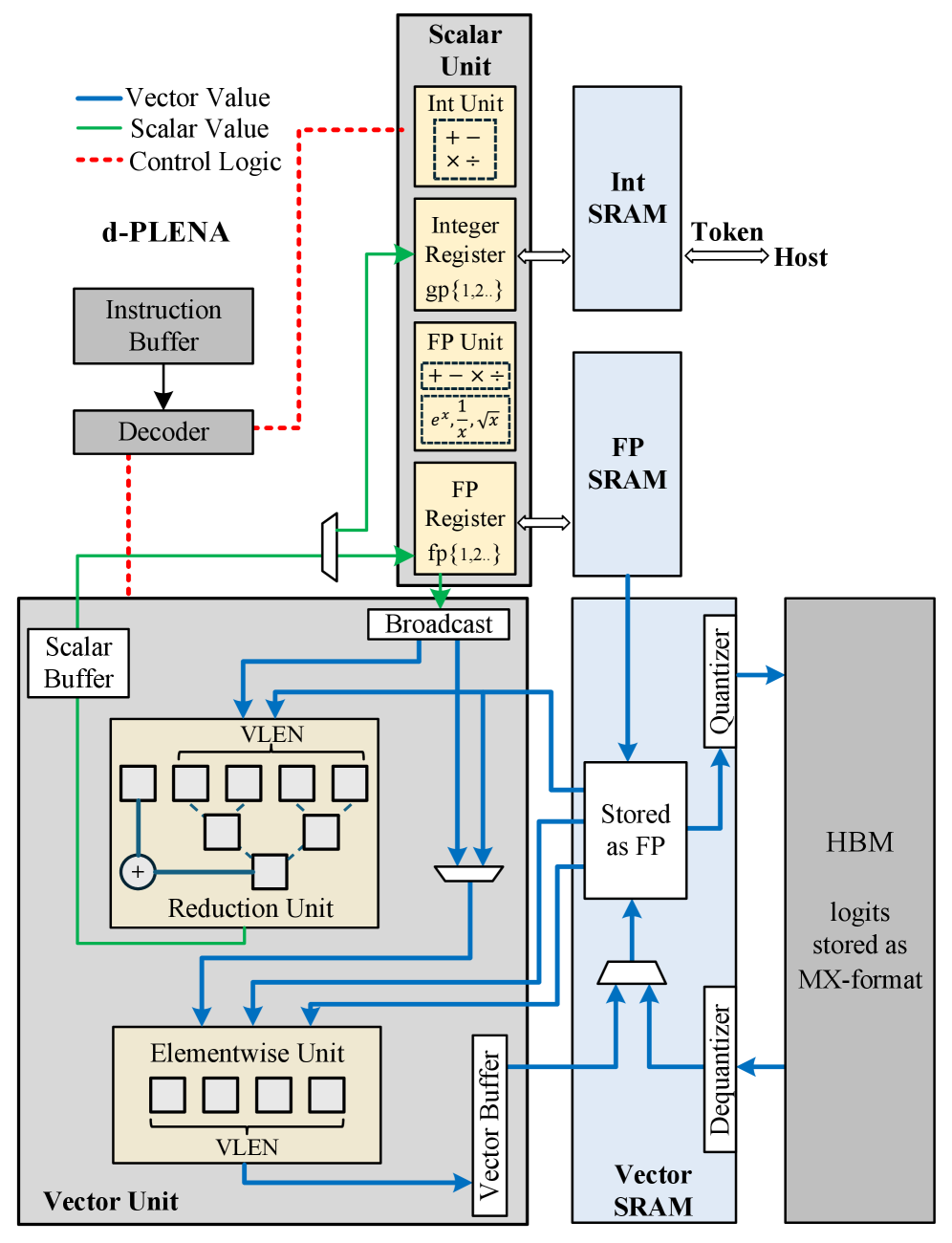
技术框架:该NPU架构包含以下主要模块:1) 指令集架构(ISA):定义了一组专门为dLLM采样优化的指令,包括非GEMM向量原语,例如向量加法、乘法、比较等。2) 计算单元:包含多个计算核心,每个核心能够执行这些向量指令。3) 内存层次结构:采用解耦的混合精度内存层次结构,包括片上SRAM和片外DRAM,并支持不同的数据精度。4) 内存管理单元(MMU):负责管理内存访问,并实现原地内存重用策略。整个流程是,首先将模型参数和输入数据加载到内存中,然后计算单元执行向量指令进行采样,最后将生成的token输出。
关键创新:该论文最重要的技术创新点在于针对Diffusion LLM采样阶段的特性,设计了一种非GEMM中心化的NPU架构。与传统的以GEMM为中心的NPU相比,该架构更适合处理采样阶段的大量向量操作和不规则内存访问。通过轻量级的向量原语、原地内存重用和混合精度内存层次结构,显著提高了采样效率。这种针对特定任务的架构设计思想,为未来的NPU设计提供了新的思路。
关键设计:1) 非GEMM向量原语:设计了一组轻量级的向量指令,例如向量加法、乘法、比较等,用于加速采样过程中的关键操作。2) 原地内存重用:通过在同一块内存区域上进行多次读写操作,减少了内存访问的开销。3) 混合精度内存层次结构:采用不同的数据精度来存储模型参数和中间结果,从而在精度和性能之间取得平衡。4) 解耦的内存访问:将内存访问和计算解耦,从而提高了硬件的利用率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该NPU架构在等效nm技术节点下,相比NVIDIA RTX A6000 GPU实现了高达2.53倍的加速。这一显著的性能提升主要归功于针对Diffusion LLM采样阶段的优化设计,包括非GEMM向量原语、原地内存重用和混合精度内存层次结构。此外,论文还开源了周期精确模拟和后综合RTL验证代码,验证了设计的正确性和有效性。
🎯 应用场景
该研究成果可应用于各种需要高效Diffusion LLM采样的场景,例如AI绘画、文本生成、语音合成等。通过定制化的NPU加速,可以显著降低推理延迟,提高用户体验,并为移动设备和边缘计算平台部署大型Diffusion模型提供可能。未来,该技术有望推动生成式AI在更多领域的应用。
📄 摘要(原文)
Diffusion Large Language Models (dLLMs) introduce iterative denoising to enable parallel token generation, but their sampling phase displays fundamentally different characteristics compared to GEMM-centric transformer layers. Profiling on modern GPUs reveals that sampling can account for up to 70% of total model inference latency-primarily due to substantial memory loads and writes from vocabulary-wide logits, reduction-based token selection, and iterative masked updates. These processes demand large on-chip SRAM and involve irregular memory accesses that conventional NPUs struggle to handle efficiently. To address this, we identify a set of critical instructions that an NPU architecture must specifically optimize for dLLM sampling. Our design employs lightweight non-GEMM vector primitives, in-place memory reuse strategies, and a decoupled mixed-precision memory hierarchy. Together, these optimizations deliver up to a 2.53x speedup over the NVIDIA RTX A6000 GPU under an equivalent nm technology node. We also open-source our cycle-accurate simulation and post-synthesis RTL verification code, confirming functional equivalence with current dLLM PyTorch implementations.