Agent Benchmarks Fail Public Sector Requirements
作者: Jonathan Rystrøm, Chris Schmitz, Karolina Korgul, Jan Batzner, Chris Russell
分类: cs.CY, cs.AI
发布日期: 2026-01-28
备注: Forthcoming @ IASEAI 2026
💡 一句话要点
揭示现有Agent基准测试在公共部门应用中的不足,并提出改进方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 基准测试 公共部门 评估标准 流程合规性
📋 核心要点
- 现有LLM Agent基准测试未能充分考虑公共部门的特殊需求,导致评估结果与实际应用场景脱节。
- 论文提出一套评估标准,包括流程性、真实性、公共部门特定性以及相关指标,用于衡量基准测试的适用性。
- 通过对大量基准测试论文的分析,发现现有基准测试普遍缺乏对公共部门需求的有效覆盖。
📝 摘要(中文)
在大语言模型驱动的Agent(LLM Agent)部署于公共部门时,需要确保其满足公共部门机构严格的法律、程序和结构要求。从业者和研究人员通常依赖基准测试进行此类评估。然而,目前尚不清楚基准测试需要满足哪些标准才能充分反映公共部门的要求,或者现有基准测试中有多少能够满足这些要求。本文基于对公共管理文献的初步调查,定义了此类标准:基准测试必须是基于流程的、现实的、特定于公共部门的,并报告反映公共部门独特要求的指标。我们使用经过专家验证的LLM辅助流程分析了超过1300篇基准测试论文,以评估它们是否符合这些标准。结果表明,没有一个基准测试满足所有标准。我们的研究结果呼吁研究人员开发与公共部门相关的基准测试,并呼吁公共部门官员在评估其自身的Agent使用案例时应用这些标准。
🔬 方法详解
问题定义:现有的大语言模型Agent基准测试,在评估Agent于公共部门的应用潜力时,存在显著的不足。这些基准测试往往忽略了公共部门机构所特有的法律、程序和结构性要求,导致评估结果无法准确反映Agent在实际公共服务场景中的表现。现有方法的痛点在于缺乏针对公共部门特定需求的考量,例如流程合规性、数据隐私保护、以及决策透明度等。
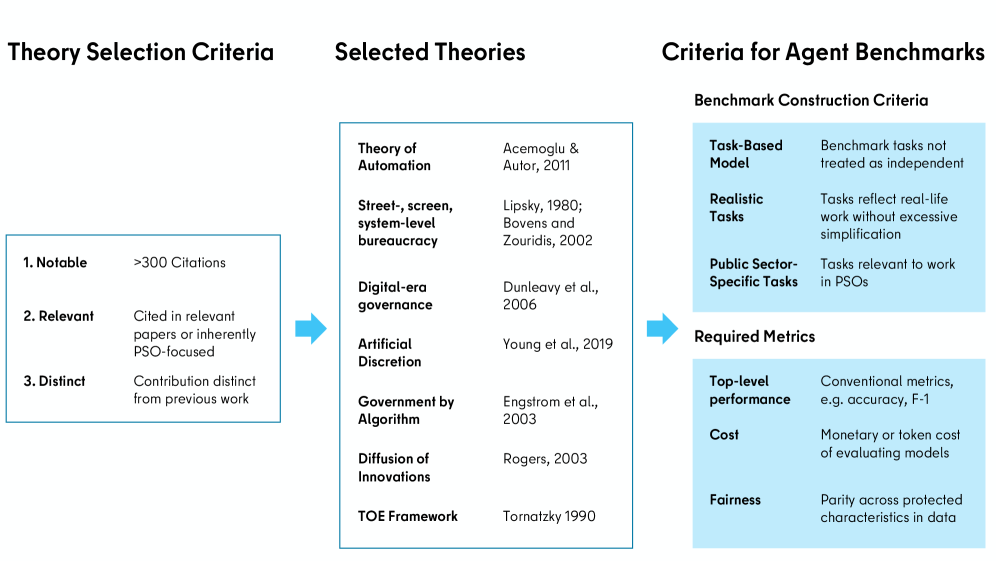
核心思路:论文的核心思路是,从公共管理的理论出发,提炼出一套针对公共部门Agent评估的基准测试标准。这些标准包括:基准测试必须是基于流程的,能够模拟公共部门的业务流程;必须是现实的,使用真实或接近真实的公共部门数据;必须是特定于公共部门的,关注公共部门特有的挑战和约束;并且必须报告反映公共部门独特要求的指标,例如公平性、可解释性、以及合规性。
技术框架:论文采用了一种混合方法,首先通过对公共管理文献的深入调研,确定了评估标准。然后,构建了一个LLM辅助的流程,用于分析大量的基准测试论文。该流程包括:数据收集(收集超过1300篇基准测试论文)、LLM辅助的文本分析(使用LLM提取论文中的关键信息,例如任务类型、数据集、评估指标等)、专家验证(由领域专家对LLM的分析结果进行验证和修正)、以及结果汇总和分析(统计有多少基准测试满足各个评估标准)。
关键创新:论文的关键创新在于,它首次系统性地提出了针对公共部门Agent评估的基准测试标准。与以往的基准测试研究不同,该研究不再仅仅关注Agent在通用任务上的性能,而是更加关注Agent在特定领域(即公共部门)的适用性和可靠性。此外,论文还构建了一个可复用的LLM辅助流程,用于大规模分析基准测试论文,这为后续的研究提供了便利。
关键设计:在LLM辅助的文本分析阶段,论文使用了预训练的大语言模型,并对其进行了微调,以提高其在基准测试论文分析任务上的准确性。此外,为了确保分析结果的可靠性,论文还引入了专家验证机制,由领域专家对LLM的分析结果进行审核和修正。在评估指标方面,论文重点关注那些能够反映公共部门独特要求的指标,例如公平性、可解释性、合规性、以及透明度。
🖼️ 关键图片

📊 实验亮点
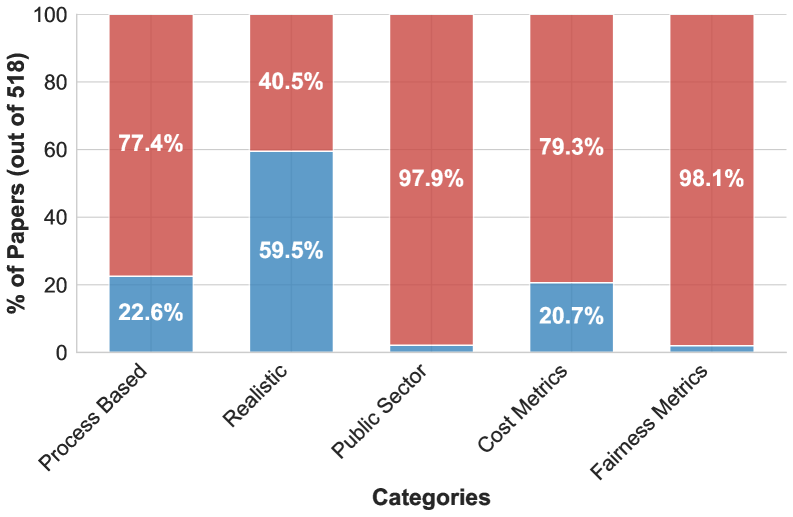
研究结果表明,在分析的1300多篇基准测试论文中,没有一个基准测试能够同时满足所有提出的公共部门评估标准。这突显了现有基准测试在公共部门应用方面的局限性,并强调了开发更具针对性的基准测试的必要性。该研究为公共部门评估LLM Agent提供了一个清晰的框架。
🎯 应用场景
该研究成果可应用于指导公共部门在引入和评估LLM Agent时,选择合适的基准测试,确保Agent能够满足公共部门的特定需求。同时,该研究也为研究人员开发更贴合公共部门实际需求的基准测试提供了参考,促进AI技术在公共服务领域的健康发展。未来,可以进一步研究如何将这些标准融入到Agent的设计和开发过程中。
📄 摘要(原文)
Deploying Large Language Model-based agents (LLM agents) in the public sector requires assuring that they meet the stringent legal, procedural, and structural requirements of public-sector institutions. Practitioners and researchers often turn to benchmarks for such assessments. However, it remains unclear what criteria benchmarks must meet to ensure they adequately reflect public-sector requirements, or how many existing benchmarks do so. In this paper, we first define such criteria based on a first-principles survey of public administration literature: benchmarks must be \emph{process-based}, \emph{realistic}, \emph{public-sector-specific} and report \emph{metrics} that reflect the unique requirements of the public sector. We analyse more than 1,300 benchmark papers for these criteria using an expert-validated LLM-assisted pipeline. Our results show that no single benchmark meets all of the criteria. Our findings provide a call to action for both researchers to develop public sector-relevant benchmarks and for public-sector officials to apply these criteria when evaluating their own agentic use cases.