CtrlCoT: Dual-Granularity Chain-of-Thought Compression for Controllable Reasoning
作者: Zhenxuan Fan, Jie Cao, Yang Dai, Zheqi Lv, Wenqiao Zhang, Zhongle Xie, Peng LU, Beng Chin Ooi
分类: cs.AI, cs.CL
发布日期: 2026-01-28
备注: 16 pages, 9 figures, 11 tables
🔗 代码/项目: GITHUB
💡 一句话要点
CtrlCoT:一种双粒度思维链压缩框架,用于可控推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链压缩 双粒度压缩 逻辑保持蒸馏 分层推理抽象 分布对齐生成
📋 核心要点
- 现有CoT压缩方法在语义层面过于保守,或在token层面过于激进,难以兼顾效率和准确性。
- CtrlCoT通过分层推理抽象、逻辑保持蒸馏和分布对齐生成,实现双粒度CoT压缩。
- 实验表明,CtrlCoT在减少token使用量的同时,显著提升了推理准确性,实现了更高效可靠的推理。
📝 摘要(中文)
思维链(CoT)提示可以提升大型语言模型(LLM)的推理能力,但由于其冗长的推理过程,导致高延迟和高内存成本。因此,在保证正确性的前提下压缩CoT成为一个研究热点。现有的方法要么在语义层面缩短CoT,但通常过于保守;要么激进地修剪token,这可能会遗漏关键的任务线索并降低准确性。此外,由于顺序依赖性、任务无关的修剪和分布不匹配,将两者结合起来并非易事。我们提出了CtrlCoT,一个双粒度CoT压缩框架,通过三个组件协调语义抽象和token级修剪:分层推理抽象生成多个语义粒度的CoT;逻辑保持蒸馏训练一个逻辑感知的修剪器,以在不同的修剪比例下保留不可或缺的推理线索(例如,数字和运算符);分布对齐生成使压缩后的推理过程与流畅的推理风格对齐,以避免碎片化。在Qwen2.5-7B-Instruct上对MATH-500数据集的实验表明,CtrlCoT使用减少30.7%的token,同时比最强的基线高出7.6个百分点,证明了更高效和可靠的推理。
🔬 方法详解
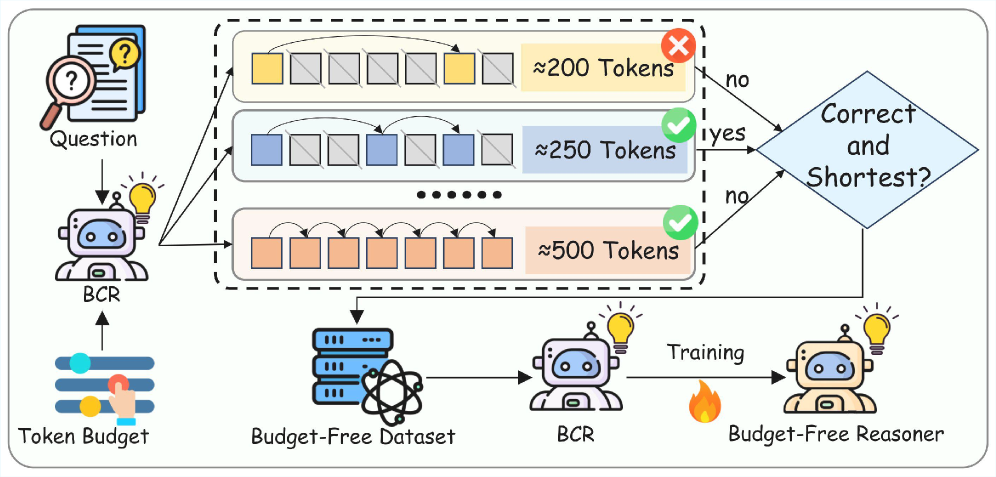
问题定义:论文旨在解决思维链(CoT)推理中,由于CoT过程冗长而导致的高延迟和高内存成本问题。现有CoT压缩方法的痛点在于,语义层面的压缩过于保守,token层面的压缩容易丢失关键信息,并且难以将两者有效结合。
核心思路:论文的核心思路是提出一种双粒度CoT压缩框架,该框架同时考虑语义抽象和token级别的剪枝,通过分层推理抽象提取不同粒度的语义信息,并利用逻辑保持蒸馏训练一个能够识别和保留关键推理线索的剪枝器,最后通过分布对齐生成保证压缩后的CoT推理过程的流畅性。
技术框架:CtrlCoT框架包含三个主要模块: 1. 分层推理抽象 (Hierarchical Reasoning Abstraction):生成多个语义粒度的CoT,提供不同抽象程度的推理过程。 2. 逻辑保持蒸馏 (Logic-Preserving Distillation):训练一个逻辑感知的剪枝器,保留推理过程中重要的数字、运算符等逻辑线索。 3. 分布对齐生成 (Distribution-Alignment Generation):使压缩后的CoT推理过程与流畅的推理风格对齐,避免推理过程碎片化。
关键创新:该论文的关键创新在于提出了一个双粒度CoT压缩框架,它将语义抽象和token级别的剪枝相结合,并引入了逻辑保持蒸馏,从而能够在保证推理准确性的前提下,更有效地压缩CoT。与现有方法相比,CtrlCoT能够更好地平衡压缩率和准确性。
关键设计: * 分层推理抽象:具体实现方法未知,但目标是生成不同抽象程度的CoT。 * 逻辑保持蒸馏:设计了一个逻辑感知的损失函数,用于训练剪枝器,确保关键的数字和运算符等逻辑线索被保留。损失函数的具体形式未知。 * 分布对齐生成:使用某种生成模型(具体模型未知)来对压缩后的CoT进行微调,使其与流畅的推理风格对齐。训练数据的构建方式和生成模型的训练目标未知。
🖼️ 关键图片


📊 实验亮点
在MATH-500数据集上,使用Qwen2.5-7B-Instruct模型进行实验,CtrlCoT在减少30.7% token使用量的情况下,比最强的基线方法提高了7.6个百分点的准确率。这表明CtrlCoT在提升推理效率的同时,也保证了推理的可靠性。
🎯 应用场景
CtrlCoT可应用于各种需要高效推理的场景,例如资源受限的设备上的LLM部署、需要快速响应的实时推理系统等。通过降低CoT推理的计算和存储成本,CtrlCoT可以促进LLM在更广泛的应用场景中的部署和应用,并提升用户体验。
📄 摘要(原文)
Chain-of-thought (CoT) prompting improves LLM reasoning but incurs high latency and memory cost due to verbose traces, motivating CoT compression with preserved correctness. Existing methods either shorten CoTs at the semantic level, which is often conservative, or prune tokens aggressively, which can miss task-critical cues and degrade accuracy. Moreover, combining the two is non-trivial due to sequential dependency, task-agnostic pruning, and distribution mismatch. We propose \textbf{CtrlCoT}, a dual-granularity CoT compression framework that harmonizes semantic abstraction and token-level pruning through three components: Hierarchical Reasoning Abstraction produces CoTs at multiple semantic granularities; Logic-Preserving Distillation trains a logic-aware pruner to retain indispensable reasoning cues (e.g., numbers and operators) across pruning ratios; and Distribution-Alignment Generation aligns compressed traces with fluent inference-time reasoning styles to avoid fragmentation. On MATH-500 with Qwen2.5-7B-Instruct, CtrlCoT uses 30.7\% fewer tokens while achieving 7.6 percentage points higher than the strongest baseline, demonstrating more efficient and reliable reasoning. Our code will be publicly available at https://github.com/fanzhenxuan/Ctrl-CoT.