Policy of Thoughts: Scaling LLM Reasoning via Test-time Policy Evolution
作者: Zhengbo Jiao, Hongyu Xian, Qinglong Wang, Yunpu Ma, Zhebo Wang, Zifan Zhang, Dezhang Kong, Meng Han
分类: cs.AI
发布日期: 2026-01-28
备注: 19 pages, 5 figures
💡 一句话要点
提出Policy of Thoughts,通过测试时策略演化提升LLM复杂推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 策略演化 测试时优化 复杂推理 代码生成
📋 核心要点
- 现有LLM在复杂推理中表现不佳,主要原因是其固定的策略无法适应不同任务的需求。
- PoT通过在线策略演化,利用执行反馈动态调整模型推理策略,实现实例级别的优化。
- 实验表明,PoT能显著提升LLM在代码生成等任务上的性能,超越更大规模的模型。
📝 摘要(中文)
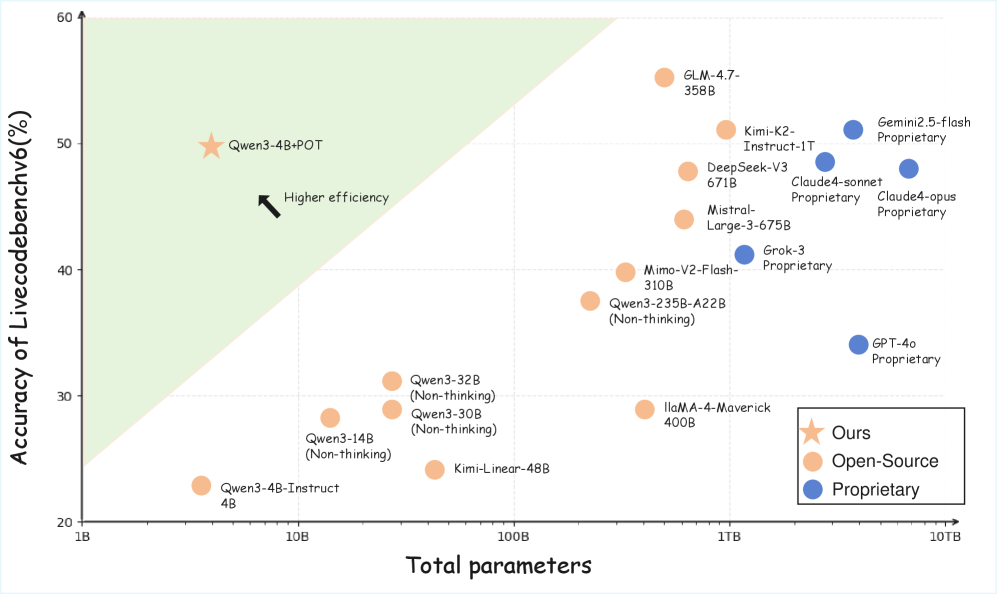
大型语言模型(LLMs)由于其固定的策略假设,在复杂的、长程推理中面临不稳定性。现有的测试时扩展方法仅将执行反馈视为过滤或重写轨迹的外部信号,而没有将其内化以改进底层推理策略。受波普尔“猜想与反驳”认识论的启发,我们认为智能需要通过从失败的尝试中学习来实时演化模型的策略。我们提出了Policy of Thoughts(PoT),该框架将推理重塑为实例内的在线优化过程。PoT首先通过高效的探索机制生成多样化的候选解决方案,然后使用Group Relative Policy Optimization(GRPO)基于执行反馈更新一个瞬态LoRA适配器。这种闭环设计能够动态地、针对特定实例地改进模型的推理先验。实验表明,PoT显著提高了性能:一个4B模型在LiveCodeBench上达到了49.71%的准确率,超过了GPT-4o和DeepSeek-V3,尽管模型规模小50倍以上。
🔬 方法详解
问题定义:大型语言模型在复杂、长程推理任务中表现不稳定,因为它们依赖于固定的策略。现有的测试时方法仅仅利用外部反馈来过滤或重写轨迹,而忽略了利用这些反馈来改进模型自身的推理策略。这导致模型无法从错误中学习,从而限制了其解决复杂问题的能力。
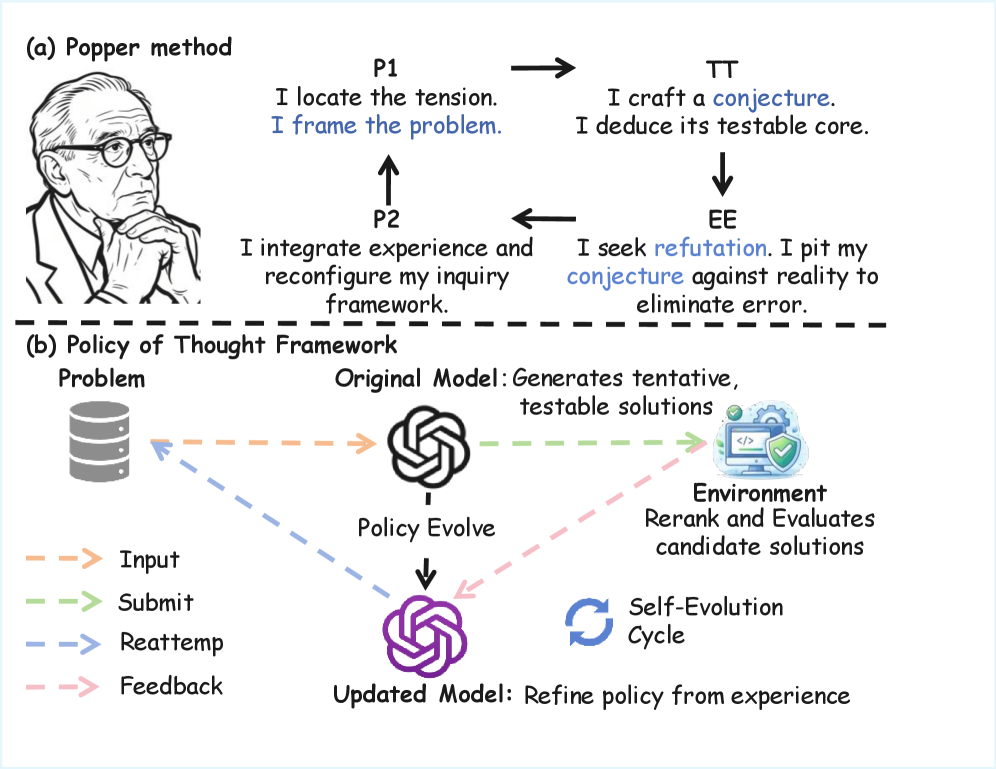
核心思路:论文的核心思想是借鉴波普尔的“猜想与反驳”理论,将推理过程视为一个在线策略优化过程。模型首先生成多个候选解决方案(猜想),然后根据执行反馈(反驳)来改进其推理策略。通过这种迭代式的优化,模型能够动态地适应不同的任务,从而提高推理的准确性。
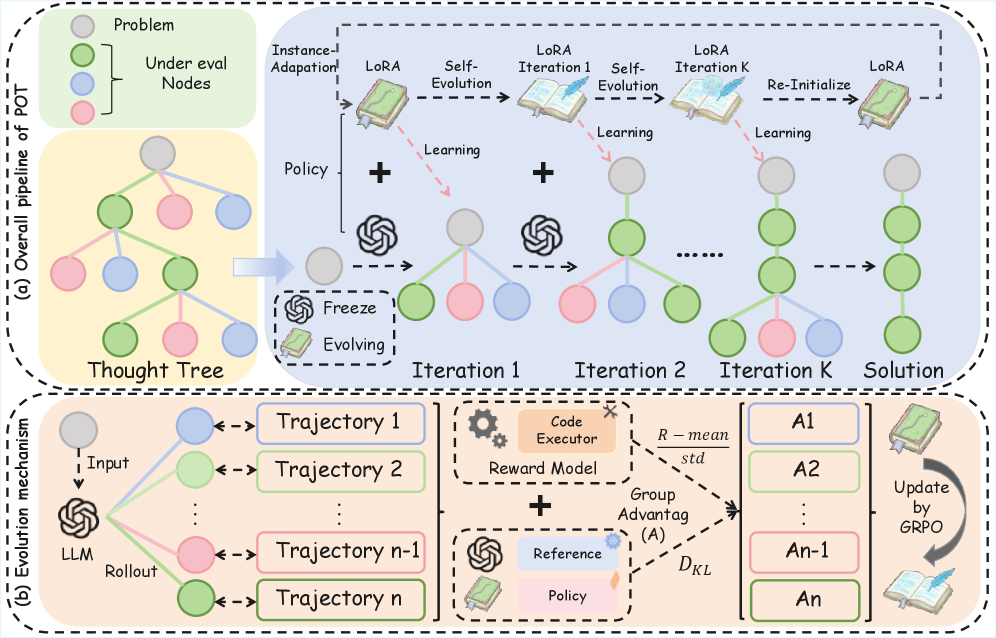
技术框架:PoT框架包含以下几个主要步骤:1) 探索:利用高效的探索机制生成多样化的候选解决方案。2) 执行:执行生成的候选解决方案,并收集执行反馈(例如,代码执行结果)。3) 策略更新:使用Group Relative Policy Optimization (GRPO) 算法,基于执行反馈更新一个瞬态LoRA适配器。这个LoRA适配器用于调整模型的推理策略。4) 迭代:重复上述步骤,直到找到一个满足要求的解决方案或达到最大迭代次数。
关键创新:PoT的关键创新在于将推理过程视为一个闭环的在线优化问题,并利用执行反馈来动态地调整模型的推理策略。与现有的测试时方法不同,PoT不仅仅是过滤或重写轨迹,而是真正地改进了模型的推理能力。此外,GRPO算法能够有效地利用多个候选解决方案的执行反馈来更新策略,从而提高学习效率。
关键设计:PoT使用LoRA (Low-Rank Adaptation) 来实现策略的动态调整。LoRA通过引入少量可训练的参数来调整预训练模型的权重,从而避免了对整个模型进行微调。GRPO算法通过比较不同候选解决方案的执行反馈,来确定哪些策略是有效的,哪些是无效的。然后,它使用这些信息来更新LoRA适配器的权重。具体的损失函数和网络结构细节在论文中有详细描述,但总体目标是最大化有效策略的概率,同时最小化无效策略的概率。
🖼️ 关键图片
📊 实验亮点
PoT在LiveCodeBench上取得了显著的性能提升。一个4B参数的模型达到了49.71%的准确率,超越了GPT-4o和DeepSeek-V3等更大规模的模型。这表明PoT能够有效地利用执行反馈来改进模型的推理能力,并且能够在资源有限的情况下实现高性能。
🎯 应用场景
Policy of Thoughts (PoT) 具有广泛的应用前景,尤其是在需要复杂推理和问题解决的领域,例如代码生成、数学问题求解、机器人控制等。通过动态调整模型的推理策略,PoT 可以提高模型在这些领域的性能和鲁棒性。此外,PoT 还可以用于个性化推荐、智能对话等应用,根据用户的反馈来优化模型的行为。
📄 摘要(原文)
Large language models (LLMs) struggle with complex, long-horizon reasoning due to instability caused by their frozen policy assumption. Current test-time scaling methods treat execution feedback merely as an external signal for filtering or rewriting trajectories, without internalizing it to improve the underlying reasoning strategy. Inspired by Popper's epistemology of "conjectures and refutations," we argue that intelligence requires real-time evolution of the model's policy through learning from failed attempts. We introduce Policy of Thoughts (PoT), a framework that recasts reasoning as a within-instance online optimization process. PoT first generates diverse candidate solutions via an efficient exploration mechanism, then uses Group Relative Policy Optimization (GRPO) to update a transient LoRA adapter based on execution feedback. This closed-loop design enables dynamic, instance-specific refinement of the model's reasoning priors. Experiments show that PoT dramatically boosts performance: a 4B model achieves 49.71% accuracy on LiveCodeBench, outperforming GPT-4o and DeepSeek-V3 despite being over 50 smaller.