SuperInfer: SLO-Aware Rotary Scheduling and Memory Management for LLM Inference on Superchips
作者: Jiahuan Yu, Mingtao Hu, Zichao Lin, Minjia Zhang
分类: cs.DC, cs.AI, cs.LG
发布日期: 2026-01-28
备注: Accepted by MLSys '26
💡 一句话要点
SuperInfer:面向Superchip的SLO感知LLM推理旋转调度与内存管理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推理 Superchip NVLink-C2C SLO感知调度 KV缓存管理
📋 核心要点
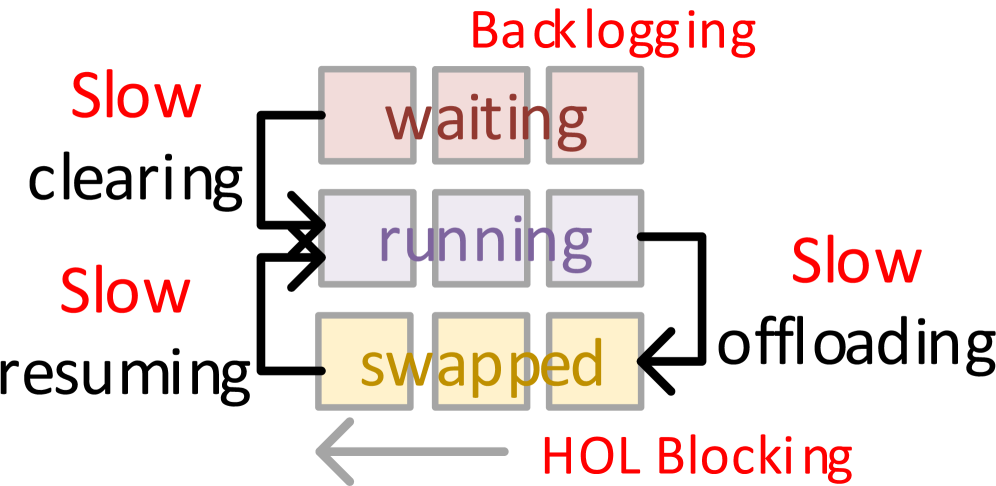
- 现有LLM推理系统在高并发请求下,KV缓存易耗尽,导致队头阻塞,难以满足严格的延迟SLO。
- SuperInfer提出RotaSched旋转调度器和DuplexKV旋转引擎,利用Superchip的NVLink-C2C实现高效全双工传输。
- 实验表明,SuperInfer在GH200上显著提升TTFT SLO达成率高达74.7%,同时保持了相当的TBT和吞吐量。
📝 摘要(中文)
大规模语言模型(LLM)服务面临着严格的延迟服务等级目标(SLO)和有限的GPU内存容量之间的根本矛盾。当高请求速率耗尽KV缓存预算时,现有的LLM推理系统通常会遭受严重的队头(HOL)阻塞。虽然之前的工作探索了基于PCIe的卸载,但这些方法无法在高请求速率下维持响应性,常常无法满足严格的首个token时间(TTFT)和token间时间(TBT)SLO。我们提出了SuperInfer,一个高性能LLM推理系统,专为新兴的Superchip(例如,NVIDIA GH200)设计,它通过NVLink-C2C紧密耦合GPU-CPU架构。SuperInfer引入了RotaSched,这是第一个主动的、SLO感知的旋转调度器,它旋转请求以在Superchip上保持响应性,以及DuplexKV,一个优化的旋转引擎,可以在NVLink-C2C上实现全双工传输。在GH200上使用各种模型和数据集的评估表明,与最先进的系统相比,SuperInfer将TTFT SLO达成率提高了高达74.7%,同时保持了相当的TBT和吞吐量,这表明SLO感知的调度和内存协同设计释放了Superchip在响应式LLM服务方面的全部潜力。
🔬 方法详解
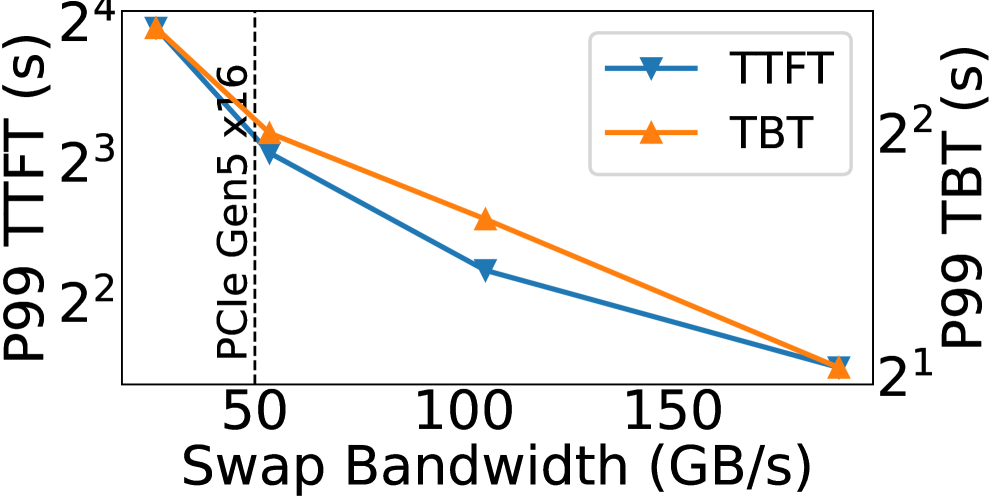
问题定义:现有LLM推理系统在高并发请求下,KV缓存容量受限,导致请求排队,队头阻塞问题严重,难以满足严格的Time-To-First-Token (TTFT) 和 Time-Between-Tokens (TBT) SLO要求。基于PCIe的卸载方案无法在高负载下维持响应性。
核心思路:SuperInfer的核心思路是利用Superchip(如NVIDIA GH200)上GPU和CPU之间通过NVLink-C2C的高速互连,设计SLO感知的旋转调度器和优化的旋转引擎,实现请求的快速轮转和KV缓存的高效管理,从而保证整体的响应性和吞吐量。
技术框架:SuperInfer包含两个主要模块:RotaSched和DuplexKV。RotaSched是SLO感知的旋转调度器,负责根据请求的SLO优先级和系统负载情况,动态地调整请求的执行顺序,避免队头阻塞。DuplexKV是优化的旋转引擎,负责在GPU和CPU之间高效地传输KV缓存,利用NVLink-C2C的全双工特性,实现数据的并行传输和计算。
关键创新:SuperInfer的关键创新在于RotaSched的主动式SLO感知旋转调度和DuplexKV的全双工KV缓存传输机制。RotaSched能够根据SLO动态调整请求优先级,避免高优先级请求因低优先级请求阻塞,保证整体的SLO达成率。DuplexKV充分利用NVLink-C2C的全双工特性,实现了KV缓存的并行传输和计算,显著提高了数据传输效率。
关键设计:RotaSched采用基于优先级的轮询调度算法,并引入了SLO感知的优先级调整机制。DuplexKV设计了双缓冲机制,允许在GPU计算的同时,CPU进行数据传输,从而实现全双工操作。具体参数设置和损失函数未知。
🖼️ 关键图片

📊 实验亮点
在NVIDIA GH200上,SuperInfer相比于现有技术,在保证相当的TBT和吞吐量的前提下,TTFT SLO达成率提升高达74.7%。实验结果表明,SuperInfer能够有效缓解队头阻塞问题,显著提升LLM推理的响应速度和用户体验。
🎯 应用场景
SuperInfer适用于对延迟有严格要求的LLM在线服务场景,例如智能客服、实时翻译、对话式AI等。通过提升TTFT和TBT SLO达成率,可以显著改善用户体验,提高服务的可用性和竞争力。该研究成果有助于充分发挥Superchip的性能潜力,推动LLM在更多实际场景中的应用。
📄 摘要(原文)
Large Language Model (LLM) serving faces a fundamental tension between stringent latency Service Level Objectives (SLOs) and limited GPU memory capacity. When high request rates exhaust the KV cache budget, existing LLM inference systems often suffer severe head-of-line (HOL) blocking. While prior work explored PCIe-based offloading, these approaches cannot sustain responsiveness under high request rates, often failing to meet tight Time-To-First-Token (TTFT) and Time-Between-Tokens (TBT) SLOs. We present SuperInfer, a high-performance LLM inference system designed for emerging Superchips (e.g., NVIDIA GH200) with tightly coupled GPU-CPU architecture via NVLink-C2C. SuperInfer introduces RotaSched, the first proactive, SLO-aware rotary scheduler that rotates requests to maintain responsiveness on Superchips, and DuplexKV, an optimized rotation engine that enables full-duplex transfer over NVLink-C2C. Evaluations on GH200 using various models and datasets show that SuperInfer improves TTFT SLO attainment rates by up to 74.7% while maintaining comparable TBT and throughput compared to state-of-the-art systems, demonstrating that SLO-aware scheduling and memory co-design unlocks the full potential of Superchips for responsive LLM serving.