Endogenous Reprompting: Self-Evolving Cognitive Alignment for Unified Multimodal Models
作者: Zhenchen Tang, Songlin Yang, Zichuan Wang, Bo Peng, Yang Li, Beibei Dong, Jing Dong
分类: cs.AI
发布日期: 2026-01-28
💡 一句话要点
提出内生重提示方法,弥合统一多模态模型中理解与生成间的认知鸿沟。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 统一模型 认知鸿沟 内生重提示 强化学习 自监督学习 生成模型
📋 核心要点
- 现有统一多模态模型在理解和生成之间存在认知鸿沟,无法有效指导生成。
- 提出内生重提示机制,将模型理解转化为显式生成推理,生成自对齐描述符。
- SEER框架通过强化学习,利用少量样本,提升模型评估能力和生成推理策略。
📝 摘要(中文)
统一多模态模型(UMMs)展现出强大的理解能力,但这种能力往往不能有效地指导生成。本文将此现象定义为认知鸿沟:模型缺乏对如何提升自身生成过程的理解。为了弥合这一鸿沟,我们提出内生重提示,这是一种将模型的理解从被动编码过程转化为显式生成推理步骤的机制,通过在生成过程中生成自对齐的描述符来实现。为此,我们引入了SEER(自进化评估器和重提示器),这是一个训练框架,它仅使用来自紧凑代理任务(视觉指令细化)的300个样本,建立了一个两阶段的内生循环。首先,具有可验证奖励的强化学习(RLVR)通过课程学习激活模型潜在的评估能力,产生高保真的内生奖励信号。其次,具有模型奖励思维的强化学习(RLMT)利用该信号来优化生成推理策略。实验表明,SEER在评估准确性、重提示效率和生成质量方面始终优于最先进的基线,且不牺牲通用多模态能力。
🔬 方法详解
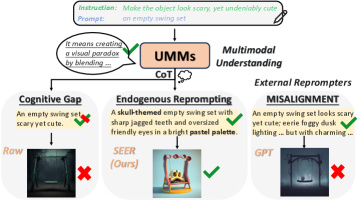
问题定义:统一多模态模型(UMMs)虽然具备强大的理解能力,但在生成任务中,这种理解能力并不能有效地指导生成过程。现有的方法缺乏模型对自身生成过程的理解,导致生成质量受限,即存在“认知鸿沟”。
核心思路:本文的核心思路是通过内生重提示机制,让模型在生成过程中主动生成自对齐的描述符,从而将模型的理解能力从被动编码转化为主动的生成推理。这样,模型就能更好地理解如何提升自身的生成过程。
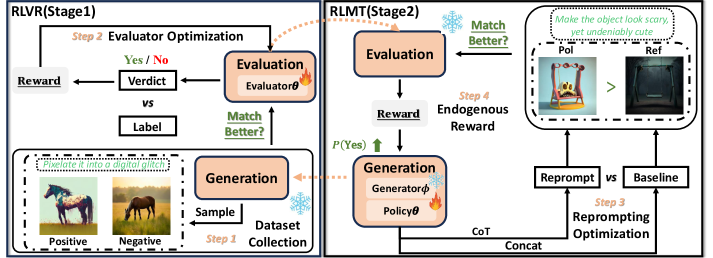
技术框架:SEER框架包含两个主要阶段:1) 使用具有可验证奖励的强化学习(RLVR)训练自进化评估器,激活模型潜在的评估能力,产生高保真的内生奖励信号。2) 使用具有模型奖励思维的强化学习(RLMT)利用该奖励信号来优化生成推理策略。整个过程构成一个两阶段的内生循环。
关键创新:关键创新在于内生重提示机制,它使得模型能够自我评估并改进生成过程。与传统的外部提示方法不同,内生重提示完全依赖于模型自身的理解和推理能力,无需人工干预。
关键设计:SEER框架的关键设计包括:1) 使用视觉指令细化任务作为代理任务,仅需少量样本(300个)即可训练。2) RLVR阶段采用课程学习,逐步提升模型的评估能力。3) RLMT阶段利用模型自身的奖励信号来优化生成策略,实现自监督学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SEER框架在评估准确性、重提示效率和生成质量方面均优于现有最先进的基线方法。具体而言,SEER在视觉指令细化任务上取得了显著的性能提升,并且在不牺牲通用多模态能力的前提下,实现了更高效的重提示过程。这些结果验证了内生重提示机制的有效性和优越性。
🎯 应用场景
该研究成果可应用于各种多模态生成任务,例如图像描述生成、视频摘要生成、视觉对话等。通过提升模型的自我理解和生成能力,可以显著提高生成内容的质量和相关性,具有广泛的应用前景和实际价值。未来,该方法有望进一步扩展到更复杂的多模态任务中,例如多模态创作和智能助手。
📄 摘要(原文)
Unified Multimodal Models (UMMs) exhibit strong understanding, yet this capability often fails to effectively guide generation. We identify this as a Cognitive Gap: the model lacks the understanding of how to enhance its own generation process. To bridge this gap, we propose Endogenous Reprompting, a mechanism that transforms the model's understanding from a passive encoding process into an explicit generative reasoning step by generating self-aligned descriptors during generation. To achieve this, we introduce SEER (Self-Evolving Evaluator and Reprompter), a training framework that establishes a two-stage endogenous loop using only 300 samples from a compact proxy task, Visual Instruction Elaboration. First, Reinforcement Learning with Verifiable Rewards (RLVR) activates the model's latent evaluation ability via curriculum learning, producing a high-fidelity endogenous reward signal. Second, Reinforcement Learning with Model-rewarded Thinking (RLMT) leverages this signal to optimize the generative reasoning policy. Experiments show that SEER consistently outperforms state-of-the-art baselines in evaluation accuracy, reprompting efficiency, and generation quality, without sacrificing general multimodal capabilities.