Eliciting Least-to-Most Reasoning for Phishing URL Detection
作者: Holly Trikilis, Pasindu Marasinghe, Fariza Rashid, Suranga Seneviratne
分类: cs.CR, cs.AI
发布日期: 2026-01-28
💡 一句话要点
提出基于Least-to-Most推理的钓鱼URL检测框架,提升LLM检测准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 钓鱼URL检测 大型语言模型 Least-to-Most推理 提示学习 答案敏感性
📋 核心要点
- 现有钓鱼URL检测方法依赖大量训练数据,且对LLM推理能力的利用不足。
- 提出Least-to-Most提示框架,通过迭代推理和答案敏感性机制提升LLM检测能力。
- 实验表明,该框架在少量数据下性能优于one-shot方法,并可媲美监督模型。
📝 摘要(中文)
钓鱼攻击是最常见的攻击手段之一,因此准确识别钓鱼URL至关重要。最近,大型语言模型(LLM)在钓鱼URL检测方面表现出良好的效果。然而,支撑这些性能的推理能力仍未得到充分探索。为此,本文提出了一种用于钓鱼URL检测的Least-to-Most提示框架。特别地,我们引入了一种“答案敏感性”机制,引导Least-to-Most的迭代方法,以增强推理能力并提高预测准确性。我们使用三个URL数据集和四个最先进的LLM评估了我们的框架,并与一次性方法和监督模型进行了比较。结果表明,我们的框架优于一次性基线,同时实现了与监督模型相当的性能,尽管需要的训练数据明显更少。此外,我们的深入分析突出了由Least-to-Most实现的迭代推理,以及由我们的答案敏感性机制加强的迭代推理如何推动这些性能提升。总的来说,我们表明,这种简单而强大的提示策略始终优于一次性方法和监督方法,尽管只需要最少的训练或少量样本指导。我们的实验设置可以在我们的Github存储库中找到。
🔬 方法详解
问题定义:论文旨在解决钓鱼URL检测问题,现有方法,特别是基于监督学习的方法,需要大量的标注数据进行训练,成本高昂。同时,直接使用大型语言模型(LLM)进行一次性(one-shot)预测,虽然不需要训练数据,但由于缺乏有效的推理引导,性能往往不如监督模型。因此,如何利用LLM的推理能力,在少量数据甚至零数据的情况下,实现高性能的钓鱼URL检测是本研究要解决的核心问题。
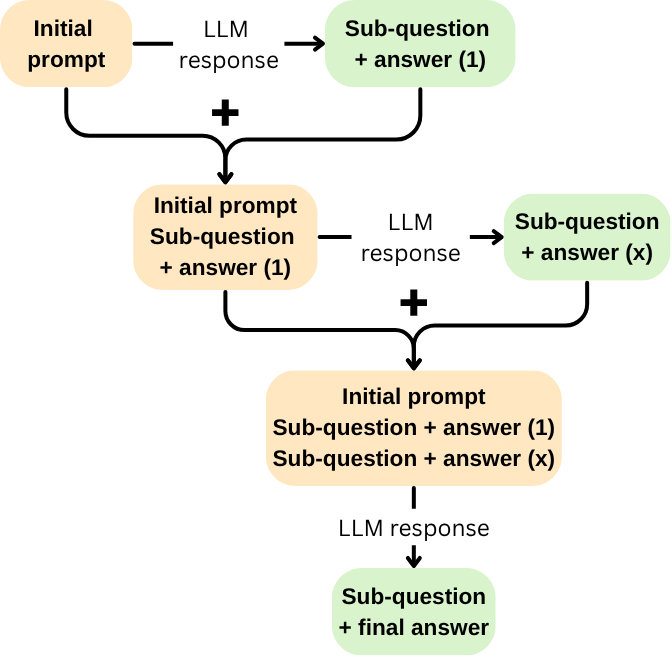
核心思路:论文的核心思路是利用Least-to-Most(LTM)提示策略,将复杂的钓鱼URL检测任务分解为一系列更简单的子任务,并逐步引导LLM进行推理。LTM的核心思想是从最简单的问题开始,逐步增加问题的复杂性,从而引导模型逐步学习和推理。此外,论文还引入了“答案敏感性”机制,用于评估每个推理步骤的置信度,并根据置信度调整后续的推理过程,从而进一步提高推理的准确性和效率。
技术框架:整体框架包含以下几个主要阶段:1) 问题分解:将钓鱼URL检测任务分解为一系列由简到繁的子问题。例如,首先判断URL是否包含可疑字符,然后判断是否使用了短链接服务,最后综合所有信息判断是否为钓鱼URL。2) 迭代推理:使用LTM提示策略,依次解决每个子问题,并将前一个子问题的答案作为下一个子问题的输入。3) 答案敏感性评估:在每个推理步骤后,评估LLM给出的答案的置信度。如果置信度较低,则调整提示策略或重新进行推理。4) 最终预测:综合所有子问题的答案,给出最终的钓鱼URL检测结果。
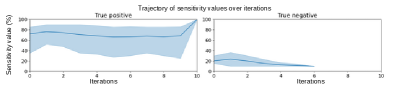
关键创新:论文的关键创新在于将Least-to-Most提示策略应用于钓鱼URL检测,并引入了“答案敏感性”机制。LTM提示策略能够有效地引导LLM进行推理,而答案敏感性机制能够提高推理的准确性和效率。与现有方法相比,该方法不需要大量的训练数据,并且能够充分利用LLM的推理能力。
关键设计:答案敏感性机制是关键设计之一。具体实现方式未知,但推测可能通过分析LLM输出的概率分布或使用外部知识库进行验证来实现。此外,如何将钓鱼URL检测任务分解为一系列由简到繁的子问题,也是一个重要的设计考虑。论文中具体的提示词设计和子问题分解策略未知,但这些细节对于最终的性能至关重要。
🖼️ 关键图片
📊 实验亮点
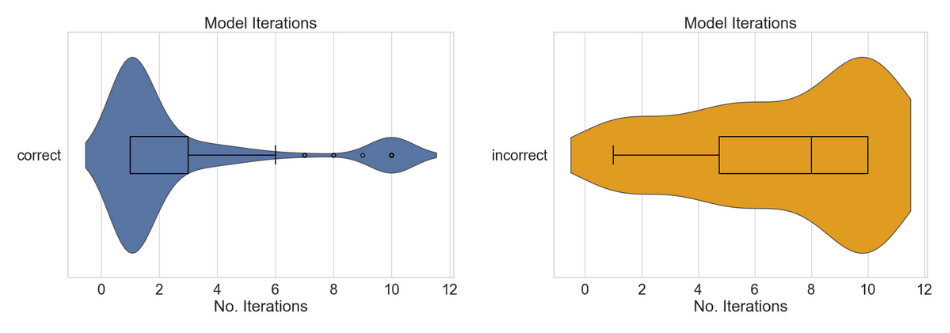
实验结果表明,提出的Least-to-Most提示框架在三个URL数据集上均优于one-shot基线方法,并且在性能上可与监督模型相媲美,同时显著减少了对训练数据的需求。具体性能提升数据未知,但论文强调了该框架在少量数据下的有效性。
🎯 应用场景
该研究成果可应用于网络安全领域,用于提升钓鱼URL检测的准确性和效率。该方法能够减少对大量标注数据的依赖,降低部署成本,并能有效应对新型钓鱼攻击。未来可集成到浏览器插件、邮件客户端、安全网关等产品中,保护用户免受钓鱼攻击侵害。
📄 摘要(原文)
Phishing continues to be one of the most prevalent attack vectors, making accurate classification of phishing URLs essential. Recently, large language models (LLMs) have demonstrated promising results in phishing URL detection. However, their reasoning capabilities that enabled such performance remain underexplored. To this end, in this paper, we propose a Least-to-Most prompting framework for phishing URL detection. In particular, we introduce an "answer sensitivity" mechanism that guides Least-to-Most's iterative approach to enhance reasoning and yield higher prediction accuracy. We evaluate our framework using three URL datasets and four state-of-the-art LLMs, comparing against a one-shot approach and a supervised model. We demonstrate that our framework outperforms the one-shot baseline while achieving performance comparable to that of the supervised model, despite requiring significantly less training data. Furthermore, our in-depth analysis highlights how the iterative reasoning enabled by Least-to-Most, and reinforced by our answer sensitivity mechanism, drives these performance gains. Overall, we show that this simple yet powerful prompting strategy consistently outperforms both one-shot and supervised approaches, despite requiring minimal training or few-shot guidance. Our experimental setup can be found in our Github repository github.sydney.edu.au/htri0928/least-to-most-phishing-detection.