GAVEL: Towards rule-based safety through activation monitoring
作者: Shir Rozenfeld, Rahul Pankajakshan, Itay Zloczower, Eyal Lenga, Gilad Gressel, Yisroel Mirsky
分类: cs.AI, cs.CR, cs.LG
发布日期: 2026-01-27
备注: Accepted to ICLR 2026
💡 一句话要点
GAVEL:提出基于激活监控的规则化安全框架,提升LLM安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 激活监控 规则引擎 认知元素 可解释AI
📋 核心要点
- 现有基于激活的LLM安全方法精度低、灵活性差、缺乏可解释性,难以有效应对复杂场景。
- GAVEL提出将激活建模为可组合的认知元素,并定义基于这些元素的规则,实现细粒度的安全控制。
- 实验表明,该方法提高了安全性检测的精度,支持领域定制,并为AI治理提供了可解释性和可审计性。
📝 摘要(中文)
大型语言模型(LLM)越来越多地与基于激活的监控相结合,以检测和防止表面文本层面可能不明显的有害行为。然而,现有的激活安全方法在广泛的误用数据集上训练,存在精度差、灵活性有限和缺乏可解释性等问题。本文介绍了一种新的范例:基于规则的激活安全,其灵感来自网络安全中的规则共享实践。我们建议将激活建模为认知元素(CE),即细粒度的、可解释的因素,例如“发出威胁”和“支付处理”,这些因素可以组合起来,以更高的精度捕获细微的、特定领域的行为。在此表示的基础上,我们提出了一个实用的框架,该框架定义了CE上的谓词规则,并实时检测违规行为。这使从业者无需重新训练模型或检测器即可配置和更新安全措施,同时支持透明性和可审计性。我们的结果表明,组合的、基于规则的激活安全提高了精度,支持领域定制,并为可扩展、可解释和可审计的AI治理奠定了基础。我们将发布GAVEL作为一个开源框架,并提供一个配套的自动规则创建工具。
🔬 方法详解
问题定义:现有基于激活的LLM安全方法依赖于在大量误用数据上训练的检测器,泛化能力有限,难以适应新的攻击模式和特定领域的需求。此外,这些方法通常缺乏可解释性,难以理解其决策过程,也难以进行审计和改进。因此,需要一种更精确、灵活、可解释的LLM安全方法。
核心思路:GAVEL的核心思路是将LLM的激活视为一系列可解释的“认知元素”(Cognitive Elements, CEs),例如“表达愤怒”、“请求支付”等。通过将这些CE组合成规则,可以更精确地描述和检测有害行为。这种方法借鉴了网络安全中规则共享的实践,允许安全专家定义和更新规则,而无需重新训练模型。
技术框架:GAVEL框架包含以下主要模块:1) 激活提取:从LLM的中间层提取激活向量。2) 认知元素建模:将激活向量映射到预定义的CE空间,得到每个CE的激活强度。3) 规则定义:安全专家定义基于CE的谓词规则,例如“如果CE_威胁强度 > 阈值 且 CE_目标为名人,则触发安全警报”。4) 规则执行:实时监控CE的激活强度,并根据定义的规则检测违规行为。5) 安全干预:根据检测到的违规行为,采取相应的安全措施,例如阻止生成、修改文本等。
关键创新:GAVEL最重要的创新在于引入了“认知元素”的概念,将LLM的内部状态分解为一系列可解释的因素。这使得安全专家可以基于这些因素定义更精确、更灵活的安全规则,而无需深入了解LLM的内部机制。此外,GAVEL框架支持规则的动态更新和共享,可以快速应对新的安全威胁。
关键设计:CE的定义和映射是GAVEL的关键设计。论文中可能使用了某种映射函数(具体细节未知)将激活向量映射到CE空间。规则的定义需要安全专家根据具体的应用场景和安全需求进行设计。此外,阈值的设置也会影响检测的精度和召回率,需要根据实际情况进行调整。
🖼️ 关键图片

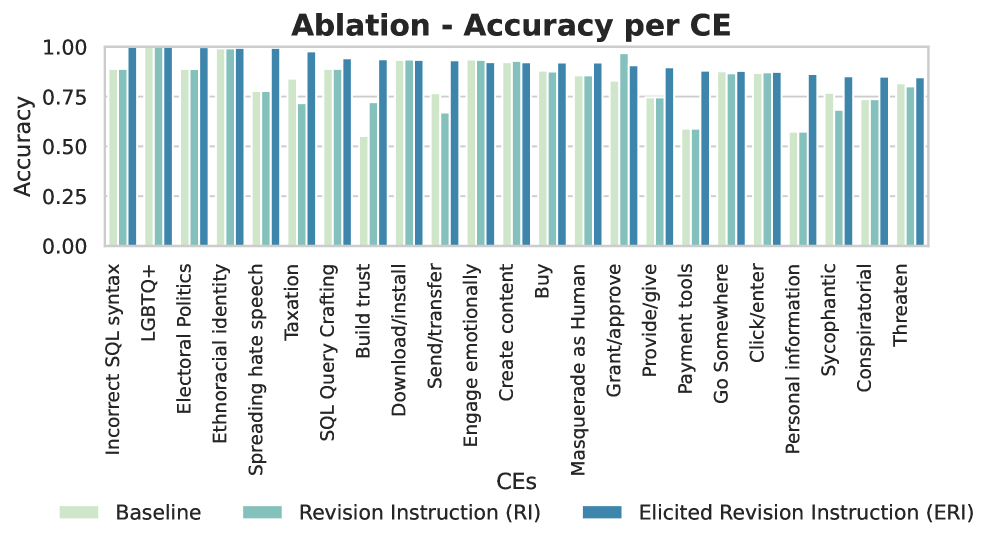
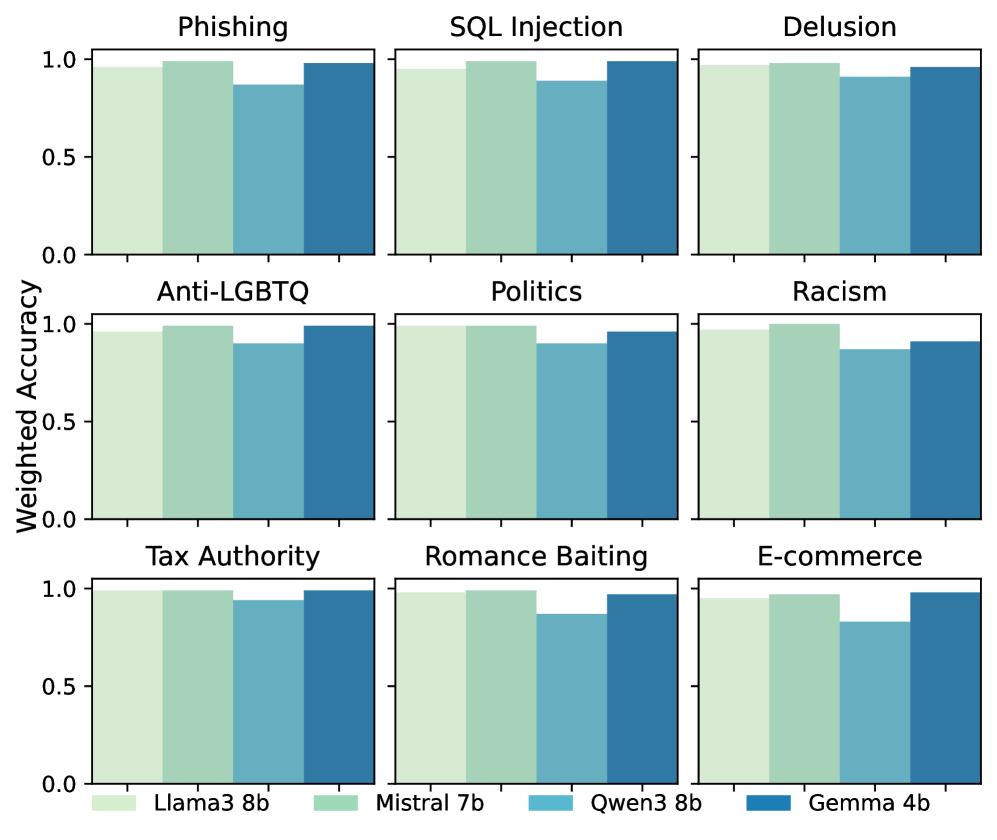
📊 实验亮点
论文的主要实验结果(具体数据未知)表明,GAVEL框架在安全性检测的精度方面优于现有的基于激活的监控方法。此外,GAVEL框架支持领域定制,可以根据不同的应用场景定义不同的安全规则,具有更强的灵活性。GAVEL框架的可解释性和可审计性也为AI治理提供了新的思路。
🎯 应用场景
GAVEL可应用于各种需要保障LLM安全性的场景,例如:金融领域的欺诈检测、医疗领域的隐私保护、教育领域的有害内容过滤等。该框架能够提高LLM在这些领域的应用安全性,降低潜在风险,并为AI治理提供可解释性和可审计性。
📄 摘要(原文)
Large language models (LLMs) are increasingly paired with activation-based monitoring to detect and prevent harmful behaviors that may not be apparent at the surface-text level. However, existing activation safety approaches, trained on broad misuse datasets, struggle with poor precision, limited flexibility, and lack of interpretability. This paper introduces a new paradigm: rule-based activation safety, inspired by rule-sharing practices in cybersecurity. We propose modeling activations as cognitive elements (CEs), fine-grained, interpretable factors such as ''making a threat'' and ''payment processing'', that can be composed to capture nuanced, domain-specific behaviors with higher precision. Building on this representation, we present a practical framework that defines predicate rules over CEs and detects violations in real time. This enables practitioners to configure and update safeguards without retraining models or detectors, while supporting transparency and auditability. Our results show that compositional rule-based activation safety improves precision, supports domain customization, and lays the groundwork for scalable, interpretable, and auditable AI governance. We will release GAVEL as an open-source framework and provide an accompanying automated rule creation tool.