AlignCoder: Aligning Retrieval with Target Intent for Repository-Level Code Completion
作者: Tianyue Jiang, Yanli Wang, Yanlin Wang, Daya Guo, Ensheng Shi, Yuchi Ma, Jiachi Chen, Zibin Zheng
分类: cs.SE, cs.AI
发布日期: 2026-01-27
备注: To appear at ASE'25
💡 一句话要点
AlignCoder:通过对齐检索与目标意图实现仓库级代码补全
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码补全 检索增强生成 强化学习 代码大语言模型 仓库级代码 查询增强 代码检索
📋 核心要点
- 现有代码大语言模型在仓库级代码补全中,对特定上下文和领域知识理解不足,导致效果不佳。
- AlignCoder通过查询增强和强化学习训练检索器,弥合查询与目标代码的语义差距,提升检索准确性。
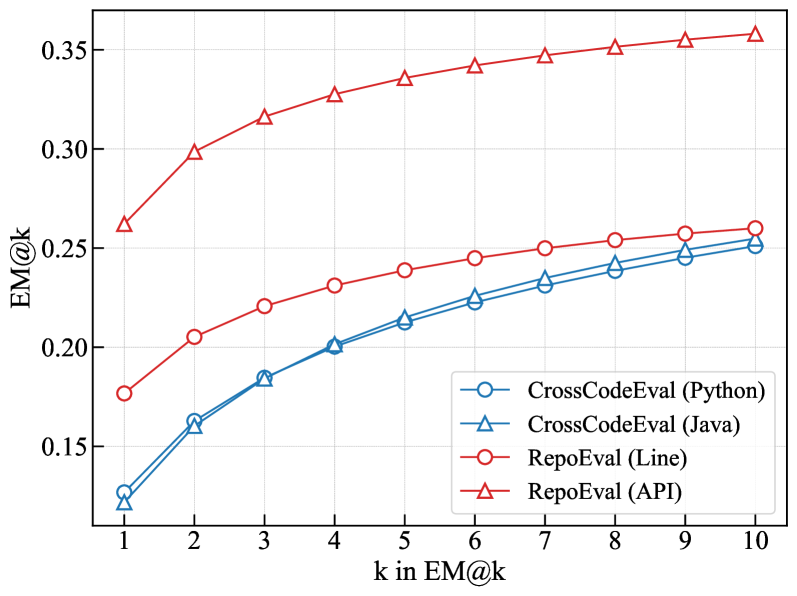
- 实验表明,AlignCoder在CrossCodeEval上相比基线模型EM得分提升18.1%,具有良好的泛化能力。
📝 摘要(中文)
由于现有代码大语言模型(code LLMs)对仓库特定上下文和领域知识的理解有限,仓库级代码补全仍然是一项具有挑战性的任务。检索增强生成(RAG)方法通过检索相关代码片段作为跨文件上下文展现出潜力,但它们存在两个根本问题:检索过程中查询与目标代码之间的不一致,以及现有检索方法无法有效利用推理信息。为了解决这些挑战,我们提出了AlignCoder,一个仓库级代码补全框架,它引入了一种查询增强机制和一种基于强化学习的检索器训练方法。我们的方法生成多个候选补全来构建一个增强的查询,从而弥合初始查询和目标代码之间的语义差距。此外,我们采用强化学习来训练AlignRetriever,它学习利用增强查询中的推理信息以进行更准确的检索。我们在两个广泛使用的基准(CrossCodeEval和RepoEval)上,针对五个骨干代码LLM评估了AlignCoder,结果表明,与CrossCodeEval基准上的基线相比,EM得分提高了18.1%。结果表明,我们的框架实现了卓越的性能,并在各种代码LLM和编程语言中表现出高度的泛化能力。
🔬 方法详解
问题定义:仓库级代码补全任务面临挑战,现有代码大语言模型难以充分理解仓库级别的上下文信息和领域知识。检索增强生成方法虽然有所帮助,但存在查询与目标代码不匹配,以及无法有效利用推理信息的痛点。
核心思路:AlignCoder的核心思路是通过增强查询来弥合初始查询和目标代码之间的语义鸿沟,并利用强化学习训练检索器,使其能够更好地利用推理信息进行检索。这样可以更准确地检索到与目标代码相关的代码片段。
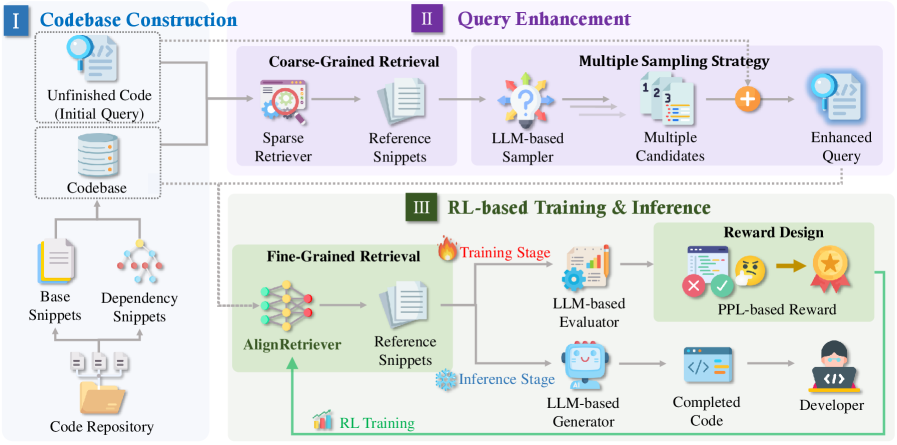
技术框架:AlignCoder框架包含两个主要模块:查询增强模块和强化学习训练的检索器(AlignRetriever)。查询增强模块生成多个候选补全,并利用这些补全构建增强的查询。AlignRetriever则利用强化学习,学习如何利用增强查询中的信息进行更准确的检索。整体流程是:接收初始查询,生成增强查询,使用AlignRetriever检索相关代码片段,最后利用检索到的代码片段进行代码补全。
关键创新:AlignCoder的关键创新在于:1) 提出了查询增强机制,通过生成多个候选补全来丰富查询信息,从而更好地匹配目标代码;2) 使用强化学习训练检索器,使其能够利用推理信息进行更准确的检索。这与传统的检索方法不同,传统方法通常只依赖于静态的查询信息。
关键设计:查询增强模块的具体实现细节未知,但可以推测其可能使用beam search等方法生成多个候选补全。强化学习训练检索器的具体奖励函数和状态空间设计未知,但奖励函数可能与补全的准确性相关。AlignRetriever的网络结构也未知,但可能采用Transformer等结构。
🖼️ 关键图片

📊 实验亮点
AlignCoder在CrossCodeEval和RepoEval两个基准测试中进行了评估,并在CrossCodeEval上取得了显著的性能提升,相比基线模型EM得分提高了18.1%。实验结果表明,AlignCoder在不同的代码大语言模型和编程语言中都具有良好的泛化能力,证明了其有效性和实用性。
🎯 应用场景
AlignCoder可应用于各种软件开发场景,提高代码补全的准确性和效率,降低开发成本。它可以集成到IDE或代码编辑器中,为开发者提供更智能的代码提示和建议。此外,该方法还可以应用于代码搜索、代码推荐等领域,提升软件开发的智能化水平。
📄 摘要(原文)
Repository-level code completion remains a challenging task for existing code large language models (code LLMs) due to their limited understanding of repository-specific context and domain knowledge. While retrieval-augmented generation (RAG) approaches have shown promise by retrieving relevant code snippets as cross-file context, they suffer from two fundamental problems: misalignment between the query and the target code in the retrieval process, and the inability of existing retrieval methods to effectively utilize the inference information. To address these challenges, we propose AlignCoder, a repository-level code completion framework that introduces a query enhancement mechanism and a reinforcement learning based retriever training method. Our approach generates multiple candidate completions to construct an enhanced query that bridges the semantic gap between the initial query and the target code. Additionally, we employ reinforcement learning to train an AlignRetriever that learns to leverage inference information in the enhanced query for more accurate retrieval. We evaluate AlignCoder on two widely-used benchmarks (CrossCodeEval and RepoEval) across five backbone code LLMs, demonstrating an 18.1% improvement in EM score compared to baselines on the CrossCodeEval benchmark. The results show that our framework achieves superior performance and exhibits high generalizability across various code LLMs and programming languages.