A Benchmark for Audio Reasoning Capabilities of Multimodal Large Language Models
作者: Iwona Christop, Mateusz Czyżnikiewicz, Paweł Skórzewski, Łukasz Bondaruk, Jakub Kubiak, Marcin Lewandowski, Marek Kubis
分类: cs.SD, cs.AI
发布日期: 2026-01-27
备注: 31 pages, 2 figures, accepted to EACL 2026
💡 一句话要点
提出音频推理任务基准(ART),用于评估多模态大语言模型的音频推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 音频推理 基准测试 音频理解
📋 核心要点
- 现有音频模态基准侧重孤立任务,无法评估模型跨任务的音频推理能力。
- 提出音频推理任务(ART)基准,旨在评估模型解决需要音频推理问题的能力。
- 该基准的有效性需要通过实验验证,以证明其能有效评估模型的音频推理能力(具体实验结果未知)。
📝 摘要(中文)
目前用于测试多模态大语言模型音频模态的基准测试,主要集中于孤立地测试各种音频任务,例如说话人分割或性别识别。然而,这些基准无法验证多模态模型是否能够回答需要推理能力来组合不同类别音频任务的问题。为了解决这个问题,我们提出了音频推理任务(ART),这是一个新的基准,用于评估多模态模型解决需要对音频信号进行推理的问题的能力。
🔬 方法详解
问题定义:现有用于评估多模态大语言模型音频能力的基准测试,通常将各种音频任务(如说话人分割、性别识别等)孤立地进行评估。这种方式的痛点在于,无法有效衡量模型是否具备将不同类别的音频任务结合起来进行推理的能力,即无法测试模型是否能基于多个音频线索进行综合判断和决策。
核心思路:论文的核心思路是构建一个专门用于评估多模态模型音频推理能力的基准测试集,即Audio Reasoning Tasks (ART)。该基准测试集包含一系列需要模型对音频信号进行推理才能解决的问题。通过在ART上测试模型,可以更全面地评估其音频理解和推理能力。
技术框架:由于摘要中没有详细描述技术框架,因此这部分信息未知。但可以推测,ART基准测试集可能包含多种类型的音频推理任务,并为每种任务设计了相应的评估指标。测试流程可能是:输入包含音频信息的提示,模型生成答案,然后根据预定义的评估指标评估答案的质量。
关键创新:该论文的关键创新在于提出了一个专门用于评估多模态模型音频推理能力的基准测试集ART。与以往侧重于孤立音频任务的基准测试不同,ART更关注模型对多个音频线索进行综合分析和推理的能力。
关键设计:由于摘要中没有详细描述关键设计,因此这部分信息未知。但可以推测,ART基准测试集在任务设计上需要考虑以下几个方面:任务的多样性(涵盖不同类型的音频推理任务)、任务的难度(需要一定的推理能力才能解决)、任务的可评估性(能够客观地评估模型的答案质量)。此外,还需要设计合适的评估指标来衡量模型的音频推理能力。
🖼️ 关键图片
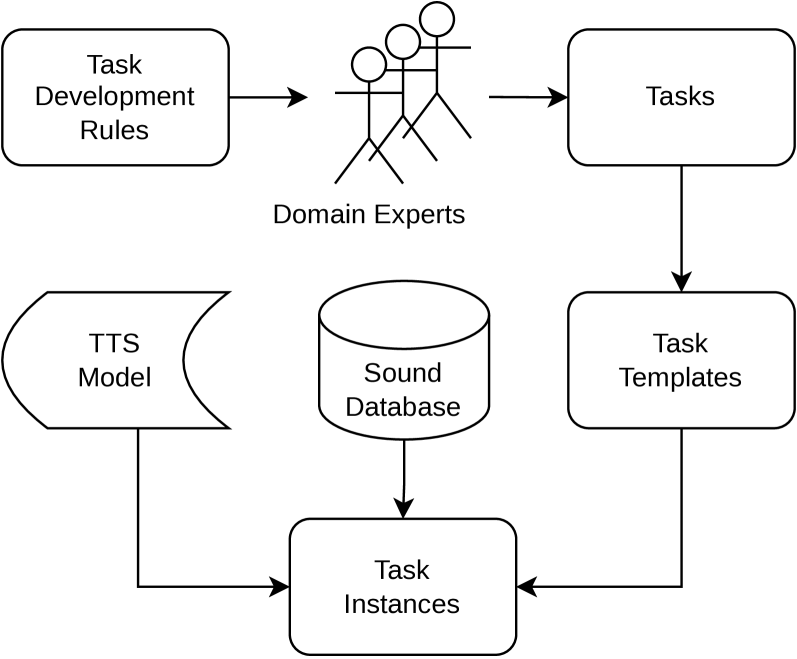

📊 实验亮点
摘要中没有提供具体的实验结果。亮点在于提出了一个新的基准测试集ART,用于评估多模态模型在音频推理方面的能力。未来的工作需要通过实验来验证ART的有效性,并与其他基线方法进行比较,以展示其优越性。
🎯 应用场景
该研究成果可应用于开发更智能的语音助手、自动驾驶系统、智能安防系统等领域。通过提高模型对音频信息的理解和推理能力,可以使这些系统更好地理解周围环境,并做出更合理的决策。例如,在智能安防领域,模型可以根据声音判断是否发生异常事件,并及时发出警报。
📄 摘要(原文)
The present benchmarks for testing the audio modality of multimodal large language models concentrate on testing various audio tasks such as speaker diarization or gender identification in isolation. Whether a multimodal model can answer the questions that require reasoning skills to combine audio tasks of different categories, cannot be verified with their use. To address this issue, we propose Audio Reasoning Tasks (ART), a new benchmark for assessing the ability of multimodal models to solve problems that require reasoning over audio signal.