RPO:Reinforcement Fine-Tuning with Partial Reasoning Optimization
作者: Hongzhu Yi, Xinming Wang, Zhenghao zhang, Tianyu Zong, Yuanxiang Wang, Jun Xie, Tao Yu, Haopeng Jin, Zhepeng Wang, Kaixin Xu, Feng Chen, Jiahuan Chen, Yujia Yang, Zhenyu Guan, Bingkang Shi, Jungang Xu
分类: cs.AI, cs.LG
发布日期: 2026-01-27
🔗 代码/项目: GITHUB
💡 一句话要点
RPO:通过部分推理优化进行强化微调,显著降低计算开销。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 微调 推理优化 计算效率
📋 核心要点
- 现有强化微调算法需生成完整推理路径,导致训练 rollout 阶段计算开销巨大,效率低下。
- RPO 算法通过经验缓存生成推理路径后缀,仅需训练部分推理过程,大幅减少 token 生成量。
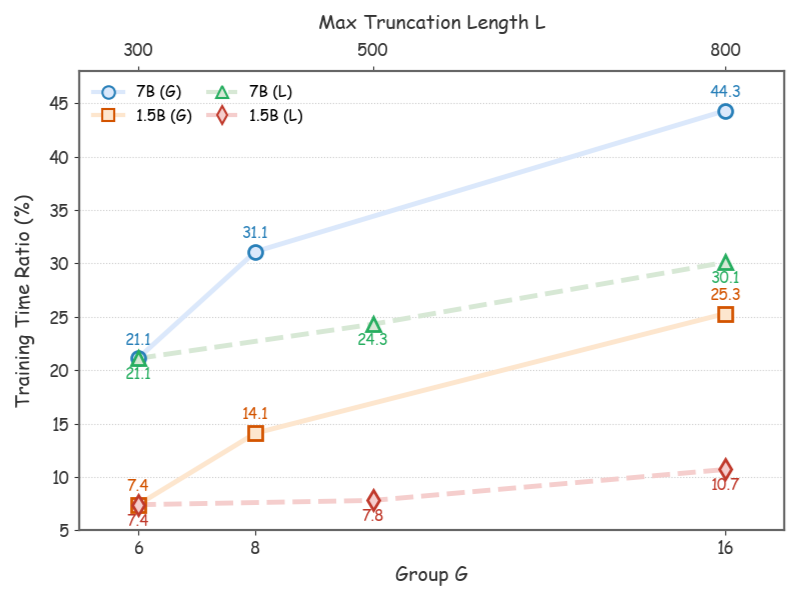
- 实验表明,RPO 显著降低了训练时间(1.5B 模型降低 90%,7B 模型降低 72%),且能与现有算法集成并加速。
📝 摘要(中文)
在大语言模型领域,强化微调算法需要生成从输入查询开始的完整推理轨迹,这在训练的 rollout 阶段会产生巨大的计算开销。为了解决这个问题,我们分析了推理路径的不同部分对最终结果正确性的影响,并在此基础上提出了 RPO(Reinforcement Fine-Tuning with Partial Reasoning Optimization),一种即插即用的强化微调算法。与生成完整推理路径的传统强化微调算法不同,RPO 通过使用经验缓存生成推理路径的后缀来训练模型。在训练的 rollout 阶段,RPO 将 token 生成量减少了约 95%,大大降低了理论时间开销。与全路径强化微调算法相比,RPO 将 1.5B 模型的训练时间减少了 90%,将 7B 模型的训练时间减少了 72%。同时,它可以与 GRPO 和 DAPO 等典型算法集成,使它们能够在保持与原始算法相当的性能的同时实现训练加速。我们的代码已在 https://github.com/yhz5613813/RPO 上开源。
🔬 方法详解
问题定义:现有的大语言模型强化微调方法,例如 GRPO 和 DAPO,在训练过程中需要生成完整的推理路径,从输入问题到最终答案。这个过程计算量巨大,尤其是在 rollout 阶段,生成大量的 tokens 消耗了大量的计算资源和时间。因此,如何降低强化微调的计算成本,提高训练效率,是一个重要的研究问题。
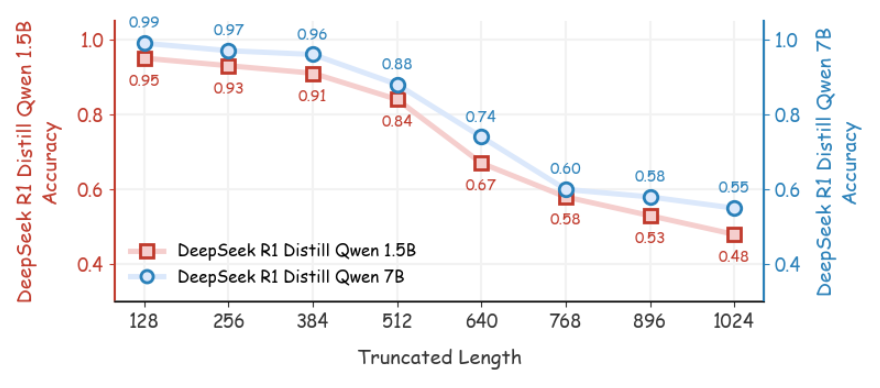
核心思路:RPO 的核心思路是,并非推理路径的每个部分都对最终结果的正确性有同等重要的影响。通过分析推理路径的不同部分,RPO 发现可以只关注推理路径的后缀,即接近最终答案的部分,来进行强化微调。通过经验缓存,RPO 可以有效地生成推理路径的后缀,从而避免了生成完整的推理路径,显著降低了计算开销。
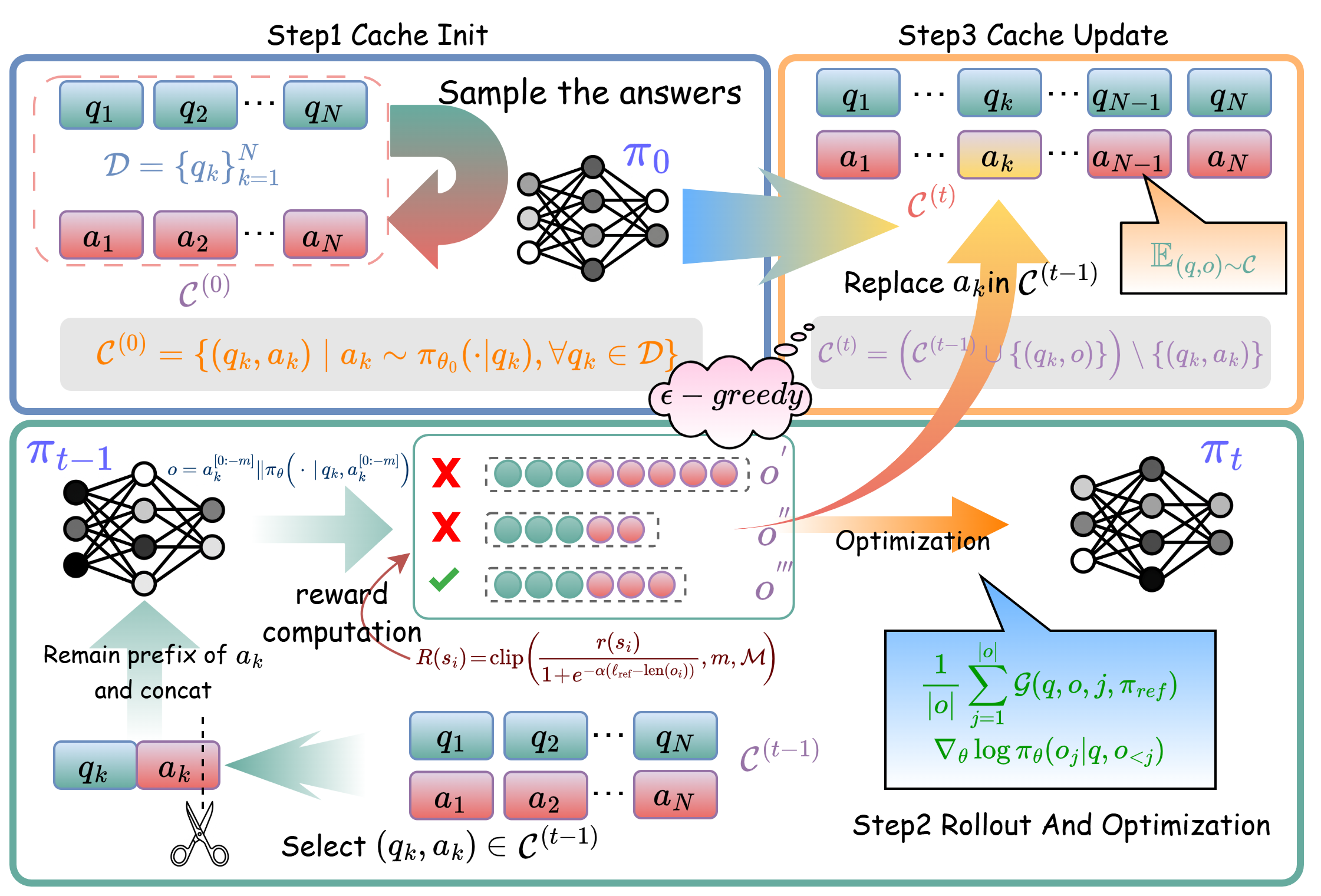
技术框架:RPO 算法的整体框架可以概括为以下几个步骤:1) 收集经验数据:使用模型生成一些推理路径,并将其存储在经验缓存中。2) 选择推理后缀:从经验缓存中选择一些推理路径的后缀,作为训练数据。3) 强化微调:使用强化学习算法,例如 PPO,对模型进行微调,目标是使模型能够更好地生成正确的推理路径后缀。4) 迭代训练:重复以上步骤,直到模型收敛。
关键创新:RPO 最重要的技术创新点在于,它打破了传统强化微调算法必须生成完整推理路径的限制,通过只关注推理路径的后缀,大大降低了计算开销。这种部分推理优化的思想,可以应用于各种强化微调算法,实现训练加速。
关键设计:RPO 的关键设计包括:1) 经验缓存的设计:如何有效地存储和检索经验数据,以保证训练数据的质量和多样性。2) 推理后缀的选择策略:如何选择合适的推理后缀,以保证训练的有效性。3) 强化学习算法的选择:选择合适的强化学习算法,例如 PPO,来对模型进行微调。具体的参数设置和损失函数需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
RPO 算法在实验中表现出色,与全路径强化微调算法相比,RPO 将 1.5B 模型的训练时间减少了 90%,将 7B 模型的训练时间减少了 72%。同时,RPO 可以与 GRPO 和 DAPO 等典型算法集成,使它们能够在保持与原始算法相当的性能的同时实现训练加速。这些结果表明,RPO 是一种有效的强化微调加速算法。
🎯 应用场景
RPO 算法可广泛应用于需要进行强化微调的大语言模型,尤其是在计算资源有限的情况下。例如,可以用于指令跟随、对话生成、代码生成等任务。通过降低训练成本,RPO 使得在更多场景下应用强化微调成为可能,并加速大语言模型的发展。
📄 摘要(原文)
Within the domain of large language models, reinforcement fine-tuning algorithms necessitate the generation of a complete reasoning trajectory beginning from the input query, which incurs significant computational overhead during the rollout phase of training. To address this issue, we analyze the impact of different segments of the reasoning path on the correctness of the final result and, based on these insights, propose Reinforcement Fine-Tuning with Partial Reasoning Optimization (RPO), a plug-and-play reinforcement fine-tuning algorithm. Unlike traditional reinforcement fine-tuning algorithms that generate full reasoning paths, RPO trains the model by generating suffixes of the reasoning path using experience cache. During the rollout phase of training, RPO reduces token generation in this phase by approximately 95%, greatly lowering the theoretical time overhead. Compared with full-path reinforcement fine-tuning algorithms, RPO reduces the training time of the 1.5B model by 90% and the 7B model by 72%. At the same time, it can be integrated with typical algorithms such as GRPO and DAPO, enabling them to achieve training acceleration while maintaining performance comparable to the original algorithms. Our code is open-sourced at https://github.com/yhz5613813/RPO.