Residual Tokens Enhance Masked Autoencoders for Speech Modeling
作者: Samir Sadok, Stéphane Lathuilière, Xavier Alameda-Pineda
分类: cs.SD, cs.AI
发布日期: 2026-01-27
备注: Submitted to ICASSP 2026 (accepted)
💡 一句话要点
RT-MAE:利用残差令牌增强语音建模的掩码自编码器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音建模 掩码自编码器 残差令牌 语音增强 无监督学习 语音重建 深度学习
📋 核心要点
- 现有语音建模依赖显式属性,但无法捕捉自然语音的全部丰富性,例如音色、情感等。
- RT-MAE通过引入可训练的残差令牌,学习显式属性之外的隐含信息,提升语音建模能力。
- 实验表明,RT-MAE在语音重建、语音增强等方面均有提升,并能保持语音的自然度。
📝 摘要(中文)
本文提出了一种新的掩码自编码器框架RT-MAE,用于语音建模。该框架在基于监督属性(如音高、内容和说话人身份)的建模基础上,增加了无监督的可训练残差令牌,旨在编码那些无法用显式标签因素解释的信息(例如,音色变化、噪声、情感等)。实验结果表明,RT-MAE提高了重建质量,在保留内容和说话人相似性的同时,增强了表达能力。此外,本文还展示了其在语音增强方面的应用,可以在推理时去除噪声,同时保持可控性和自然度。
🔬 方法详解
问题定义:现有语音建模方法主要依赖于音高、内容、说话人身份等显式属性,忽略了语音中包含的丰富信息,例如音色变化、噪声、情感等。这些信息对于提升语音建模的表达能力至关重要。现有方法难以有效捕捉和利用这些隐含信息,导致语音重建质量和表达能力受限。
核心思路:RT-MAE的核心思路是在传统的基于显式属性的语音建模基础上,引入一组可训练的残差令牌。这些残差令牌旨在编码那些无法用显式标签因素解释的信息。通过这种方式,RT-MAE能够学习到语音中更全面的信息,从而提升语音建模的性能。
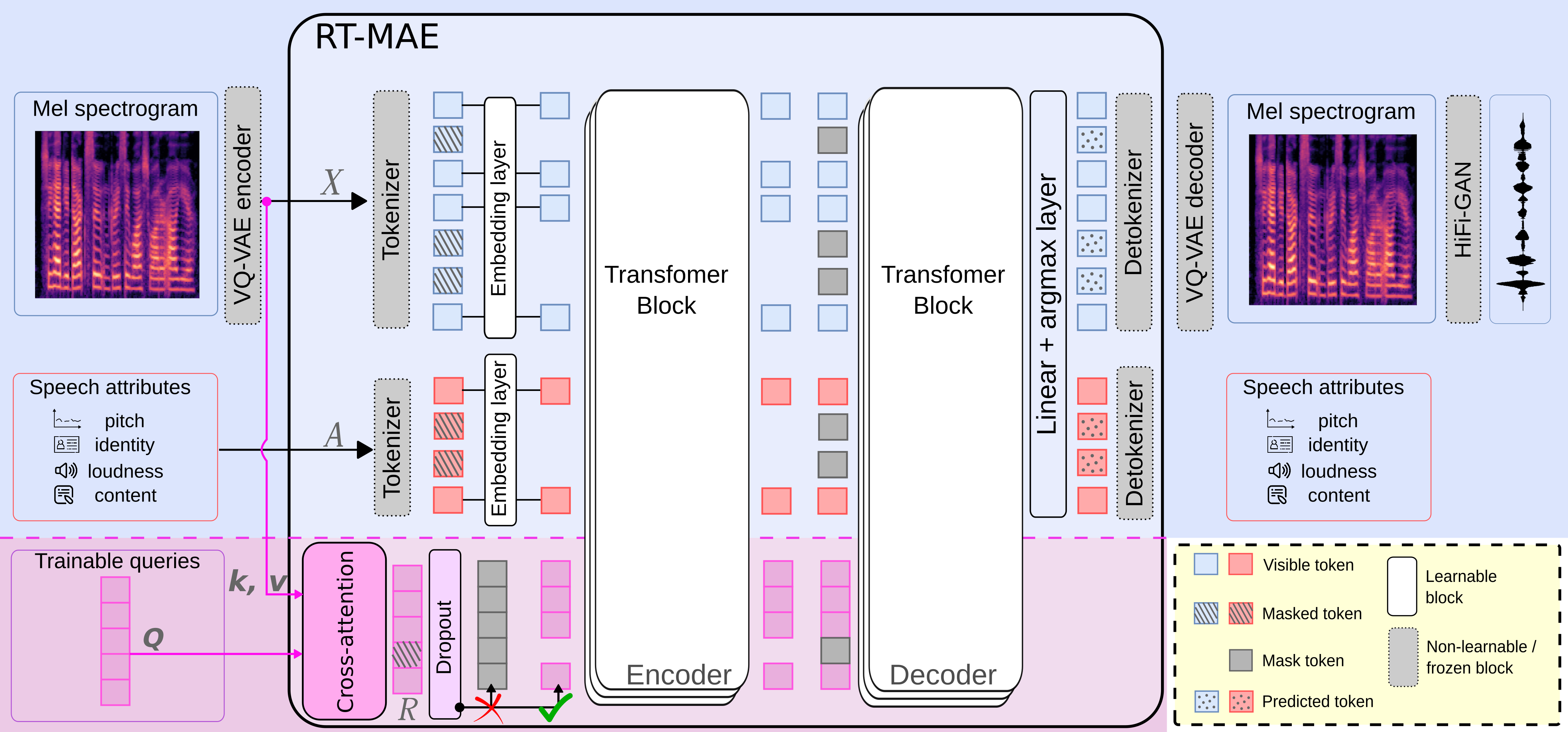
技术框架:RT-MAE的整体框架是一个掩码自编码器。它首先将输入的语音信号进行掩码,然后通过编码器提取特征。编码器输出的特征与显式属性(如音高、内容、说话人身份)以及可训练的残差令牌进行融合。融合后的特征被送入解码器,用于重建原始的语音信号。整个框架通过最小化重建误差进行训练。
关键创新:RT-MAE的关键创新在于引入了可训练的残差令牌。这些令牌能够学习到语音中那些无法用显式属性解释的隐含信息。与直接使用原始语音信号进行训练相比,RT-MAE能够更加有效地利用这些隐含信息,从而提升语音建模的性能。
关键设计:RT-MAE的关键设计包括残差令牌的数量、残差令牌的初始化方式、以及残差令牌与显式属性融合的方式。论文中具体使用了多少个残差令牌,以及如何初始化这些令牌,文中没有明确说明,属于未知信息。损失函数主要为重建误差,具体形式未知。
🖼️ 关键图片
📊 实验亮点
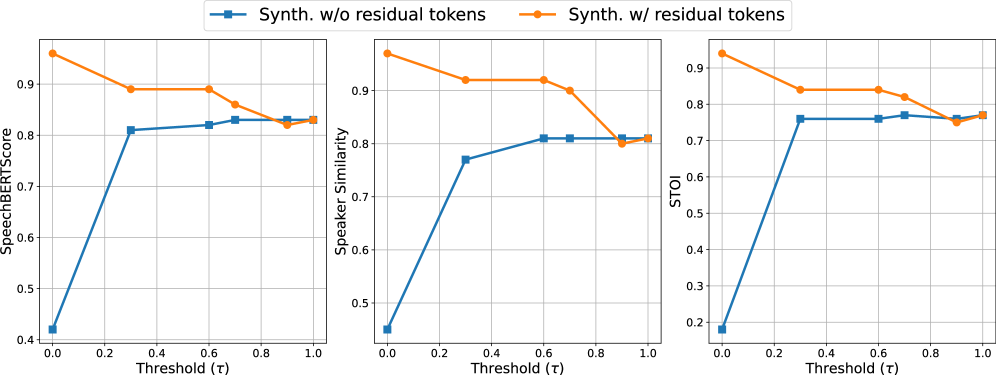
实验结果表明,RT-MAE在语音重建质量方面优于传统的掩码自编码器。RT-MAE能够更好地保留内容和说话人相似性,同时增强语音的表达能力。此外,RT-MAE在语音增强方面也取得了显著的成果,能够在去除噪声的同时,保持语音的自然度和可控性。具体的性能提升数据在摘要中未给出。
🎯 应用场景
RT-MAE具有广泛的应用前景,例如语音合成、语音转换、语音增强等。通过学习语音中的隐含信息,RT-MAE可以生成更加自然、富有表现力的语音。在语音增强方面,RT-MAE可以在去除噪声的同时,保持语音的自然度和可控性。该研究对于提升人机交互体验具有重要意义。
📄 摘要(原文)
Recent speech modeling relies on explicit attributes such as pitch, content, and speaker identity, but these alone cannot capture the full richness of natural speech. We introduce RT-MAE, a novel masked autoencoder framework that augments the supervised attributes-based modeling with unsupervised residual trainable tokens, designed to encode the information not explained by explicit labeled factors (e.g., timbre variations, noise, emotion etc). Experiments show that RT-MAE improves reconstruction quality, preserving content and speaker similarity while enhancing expressivity. We further demonstrate its applicability to speech enhancement, removing noise at inference while maintaining controllability and naturalness.