CoReTab: Improving Multimodal Table Understanding with Code-driven Reasoning
作者: Van-Quang Nguyen, Takayuki Okatani
分类: cs.AI
发布日期: 2026-01-27
备注: accepted to EACL'26 (main conference)
💡 一句话要点
提出CoReTab框架,通过代码驱动推理提升多模态表格理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态表格理解 代码驱动推理 多步骤推理 可解释性 大型语言模型
📋 核心要点
- 现有方法在多模态表格理解中缺乏明确的多步骤推理监督,导致模型生成答案准确性低且缺乏可解释性。
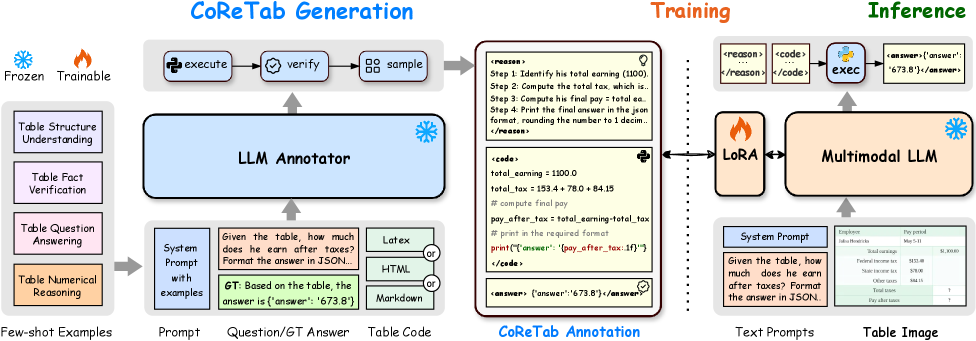
- CoReTab框架通过结合多步骤推理与可执行Python代码,生成可扩展、可解释且自动可验证的注释。
- 实验结果表明,在CoReTab上训练的模型在多个MMTab基准测试中显著优于现有基线,提升明显。
📝 摘要(中文)
现有的多模态表格理解数据集,如MMTab,主要提供简短的事实性答案,缺乏显式的多步骤推理监督。在这些数据集上训练的模型通常生成简短的响应,准确性不足,并且对模型如何得出最终答案的解释性有限。我们引入了CoReTab,这是一个代码驱动的推理框架,通过将多步骤推理与可执行的Python代码相结合,生成可扩展、可解释且自动可验证的注释。使用CoReTab框架,我们整理了一个包含11.5万个验证样本的数据集,平均每个响应529个tokens,并通过三阶段pipeline微调开源MLLM。我们在涵盖表格问答、事实验证和表格结构理解的17个MMTab基准上评估了在CoReTab上训练的模型。我们的模型相对于MMTab训练的基线分别实现了+6.2%、+5.7%和+25.6%的显著提升,同时产生了透明且可验证的推理轨迹。这些结果表明,CoReTab是一个鲁棒且通用的监督框架,用于改进多模态表格理解中的多步骤推理。
🔬 方法详解
问题定义:论文旨在解决多模态表格理解中,现有数据集缺乏多步骤推理监督,导致模型生成答案准确性低且缺乏可解释性的问题。现有方法生成的答案通常是简短的事实性回答,无法展示模型是如何进行推理并得出结论的。
核心思路:论文的核心思路是利用代码驱动的推理方式,将多步骤推理过程显式地表示为可执行的Python代码。通过执行这些代码,可以验证推理过程的正确性,并提供更透明和可解释的答案。
技术框架:CoReTab框架包含数据生成和模型训练两个主要阶段。数据生成阶段,首先设计一系列多步骤推理问题,然后编写相应的Python代码来解决这些问题,并生成包含问题、表格数据和代码的训练样本。模型训练阶段,使用生成的数据集对多模态大型语言模型(MLLM)进行微调,使其能够生成代码形式的推理过程。
关键创新:CoReTab的关键创新在于使用代码作为多步骤推理的显式表示。与传统的生成自然语言答案的方法相比,代码具有更高的精确性和可验证性。此外,代码还可以方便地进行调试和修改,从而提高模型的可解释性和鲁棒性。
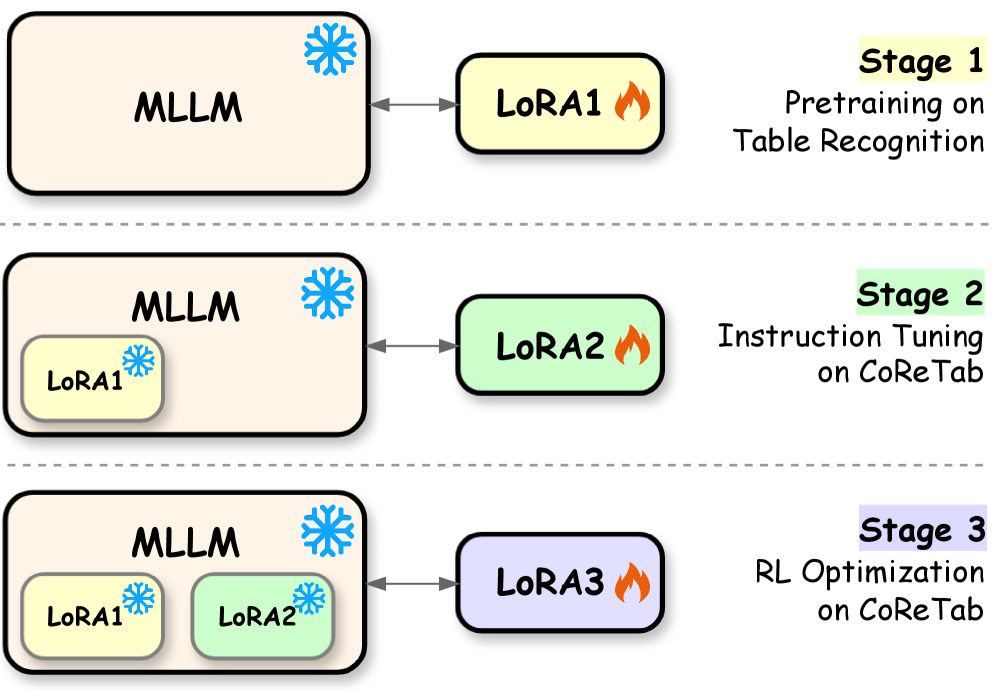
关键设计:CoReTab框架使用三阶段pipeline进行模型微调。具体的技术细节包括:选择合适的MLLM作为基础模型,设计有效的代码生成策略,以及优化损失函数以提高模型的代码生成能力。此外,还需考虑如何处理表格数据的表示和输入,以及如何将代码执行结果与最终答案进行对齐。
🖼️ 关键图片

📊 实验亮点
实验结果显示,在17个MMTab基准测试中,使用CoReTab训练的模型在表格问答、事实验证和表格结构理解任务上分别取得了+6.2%、+5.7%和+25.6%的显著提升。这些结果表明,CoReTab框架能够有效提高多模态表格理解模型的性能,并生成更透明和可验证的推理过程。
🎯 应用场景
CoReTab框架可应用于各种需要表格数据理解和推理的场景,例如金融分析、市场调研、科学研究等。通过提供可解释的代码推理过程,可以帮助用户更好地理解模型的决策过程,并提高对模型输出的信任度。未来,该框架可以扩展到更复杂的多模态推理任务中。
📄 摘要(原文)
Existing datasets for multimodal table understanding, such as MMTab, primarily provide short factual answers without explicit multi-step reasoning supervision. Models trained on these datasets often generate brief responses that offers insufficient accuracy and limited interpretability into how these models arrive at the final answer. We introduce CoReTab, a code-driven reasoning framework that produces scalable, interpretable, and automatically verifiable annotations by coupling multi-step reasoning with executable Python code. Using the CoReTab framework, we curate a dataset of 115K verified samples averaging 529 tokens per response and fine-tune open-source MLLMs through a three-stage pipeline. We evaluate the resulting model trained on CoReTab across 17 MMTab benchmarks spanning table question answering, fact verification, and table structure understanding. Our model achieves significant gains of +6.2%, +5.7%, and +25.6%, respectively, over MMTab-trained baselines, while producing transparent and verifiable reasoning traces. These results establish CoReTab as a robust and generalizable supervision framework for improving multi-step reasoning in multimodal table understanding.