TS-Debate: Multimodal Collaborative Debate for Zero-Shot Time Series Reasoning
作者: Patara Trirat, Jin Myung Kwak, Jay Heo, Heejun Lee, Sung Ju Hwang
分类: cs.AI, cs.MA
发布日期: 2026-01-27
备注: Code will be available at https://github.com/DeepAuto-AI/TS-Debate
💡 一句话要点
提出TS-Debate,用于零样本时间序列推理的多模态协同辩论框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列推理 多模态学习 大型语言模型 协同辩论 零样本学习
📋 核心要点
- 现有LLM在时间序列分析中面临数值保真度、模态干扰和跨模态集成等挑战。
- TS-Debate通过模态专家代理协同辩论,结合领域知识提取和程序化验证来解决上述问题。
- 实验表明,TS-Debate在多个时间序列任务上显著优于现有基线方法,提升了性能。
📝 摘要(中文)
大型语言模型(LLMs)与时间序列(TS)分析的交叉研究展现了潜力和局限性。虽然LLMs在精心设计的上下文条件下可以推理时间结构,但它们在数值保真度、模态干扰和有原则的跨模态集成方面存在困难。我们提出了TS-Debate,这是一个模态专业化的协同多智能体辩论框架,用于零样本时间序列推理。TS-Debate为文本上下文、视觉模式和数值信号分配了专门的专家代理,首先进行显式的领域知识提取,并通过结构化的辩论协议协调它们的交互。审查代理使用验证-冲突-校准机制评估代理的主张,该机制由轻量级代码执行和数值查找支持,以进行程序化验证。该架构保留了模态保真度,暴露了冲突证据,并减轻了数值幻觉,而无需特定于任务的微调。在跨越三个公共基准测试的20个任务中,TS-Debate相对于强大的基线实现了持续且显著的性能改进,包括所有代理观察所有输入的标准多模态辩论。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在零样本时间序列推理中存在的数值幻觉、模态干扰以及跨模态信息难以有效集成的问题。现有方法,如直接使用LLM或简单的多模态融合,无法保证数值的准确性,并且不同模态的信息容易相互干扰,导致推理结果不准确。
核心思路:论文的核心思路是将不同的模态信息(文本、视觉、数值)分配给专门的专家代理,通过结构化的辩论过程,让这些代理互相验证和校准,从而提高推理的准确性和可靠性。这种方法借鉴了人类辩论的模式,通过不同视角的碰撞来发现潜在的错误和偏差。
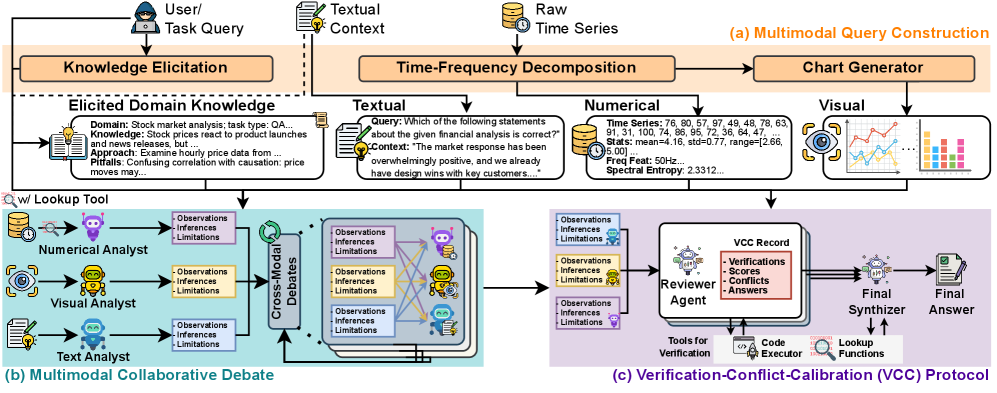
技术框架:TS-Debate框架包含以下几个主要模块:1) 领域知识提取:从输入数据中提取相关的领域知识,为后续的辩论提供基础。2) 模态专家代理:为每种模态(文本、视觉、数值)分配一个专门的代理,负责处理该模态的信息。3) 辩论协议:定义了代理之间交互的规则,包括发言顺序、辩论轮数等。4) 审查代理:负责评估每个代理的主张,并使用验证-冲突-校准机制来发现潜在的错误。5) 程序化验证:使用轻量级代码执行和数值查找来验证代理的主张,提高验证的准确性。
关键创新:TS-Debate的关键创新在于其模态专业化的协同辩论框架。与传统的单智能体或简单的多智能体方法不同,TS-Debate将不同的模态信息分配给专门的代理,并通过结构化的辩论过程来提高推理的准确性和可靠性。此外,TS-Debate还引入了程序化验证机制,进一步提高了验证的准确性。
关键设计:TS-Debate的关键设计包括:1) 领域知识提取方法:论文使用了特定的方法来提取相关的领域知识,但具体细节未知。2) 辩论协议:论文定义了特定的辩论协议,包括发言顺序、辩论轮数等,但具体细节未知。3) 验证-冲突-校准机制:论文使用了特定的机制来评估代理的主张,并发现潜在的错误,但具体细节未知。4) 程序化验证:论文使用了轻量级代码执行和数值查找来验证代理的主张,但具体实现细节未知。
🖼️ 关键图片


📊 实验亮点
TS-Debate在三个公共基准测试的20个任务中取得了显著的性能提升。与标准多模态辩论相比,TS-Debate能够更好地处理不同模态的信息,并减轻数值幻觉。具体的性能数据和提升幅度在论文中进行了详细的展示,表明TS-Debate是一种有效的时间序列推理方法。
🎯 应用场景
TS-Debate具有广泛的应用前景,例如金融市场预测、医疗诊断、环境监测等。通过结合不同模态的信息,TS-Debate可以提高预测和诊断的准确性,为决策提供更可靠的依据。未来,TS-Debate可以进一步扩展到其他领域,例如智能制造、自动驾驶等,为各行各业带来智能化升级。
📄 摘要(原文)
Recent progress at the intersection of large language models (LLMs) and time series (TS) analysis has revealed both promise and fragility. While LLMs can reason over temporal structure given carefully engineered context, they often struggle with numeric fidelity, modality interference, and principled cross-modal integration. We present TS-Debate, a modality-specialized, collaborative multi-agent debate framework for zero-shot time series reasoning. TS-Debate assigns dedicated expert agents to textual context, visual patterns, and numerical signals, preceded by explicit domain knowledge elicitation, and coordinates their interaction via a structured debate protocol. Reviewer agents evaluate agent claims using a verification-conflict-calibration mechanism, supported by lightweight code execution and numerical lookup for programmatic verification. This architecture preserves modality fidelity, exposes conflicting evidence, and mitigates numeric hallucinations without task-specific fine-tuning. Across 20 tasks spanning three public benchmarks, TS-Debate achieves consistent and significant performance improvements over strong baselines, including standard multimodal debate in which all agents observe all inputs.