Uncertainty-Aware 3D Emotional Talking Face Synthesis with Emotion Prior Distillation
作者: Nanhan Shen, Zhilei Liu
分类: cs.AI, cs.MM, cs.SD
发布日期: 2026-01-27
备注: Accepted by ICASSP 2026
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出UA-3DTalk,解决3D情感语音人脸合成中的情感对齐和渲染质量问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D人脸合成 情感语音人脸 不确定性感知 多模态融合 情感先验蒸馏 音频-视觉对齐 微表情控制
📋 核心要点
- 现有3D情感语音人脸合成方法在音频情感提取和情感微表情控制方面存在不足,导致音频-视觉情感对齐效果差。
- UA-3DTalk通过情感先验蒸馏和不确定性感知机制,实现细粒度的情感控制和自适应的多视角融合。
- 实验结果表明,UA-3DTalk在情感对齐、唇部同步和渲染质量方面均优于现有方法,性能显著提升。
📝 摘要(中文)
情感语音人脸合成在多媒体和信号处理中至关重要,但现有的3D方法面临两个关键挑战:音频-视觉情感对齐不佳,表现为音频情感提取困难和对情感微表情的控制不足;以及一刀切的多视角融合策略,忽略了不确定性和特征质量差异,从而降低了渲染质量。我们提出了UA-3DTalk,一种基于情感先验蒸馏的不确定性感知3D情感语音人脸合成方法,它具有三个核心模块:先验提取模块将音频解耦为用于对齐的内容同步特征和用于个性化的特定人互补特征;情感蒸馏模块引入了多模态注意力加权融合机制和具有多分辨率码本的4D高斯编码,从而实现细粒度的音频情感提取和对情感微表情的精确控制;基于不确定性的形变部署不确定性块来估计特定视角下的偶然不确定性(输入噪声)和认知不确定性(模型参数),实现自适应多视角融合,并结合多头解码器进行高斯基元优化,以减轻均匀权重融合的局限性。在常规和情感数据集上的大量实验表明,UA-3DTalk在情感对齐的E-FID指标上优于DEGSTalk和EDTalk等最先进的方法5.2%,在唇部同步的SyncC指标上优于3.1%,在渲染质量的LPIPS指标上优于0.015。
🔬 方法详解
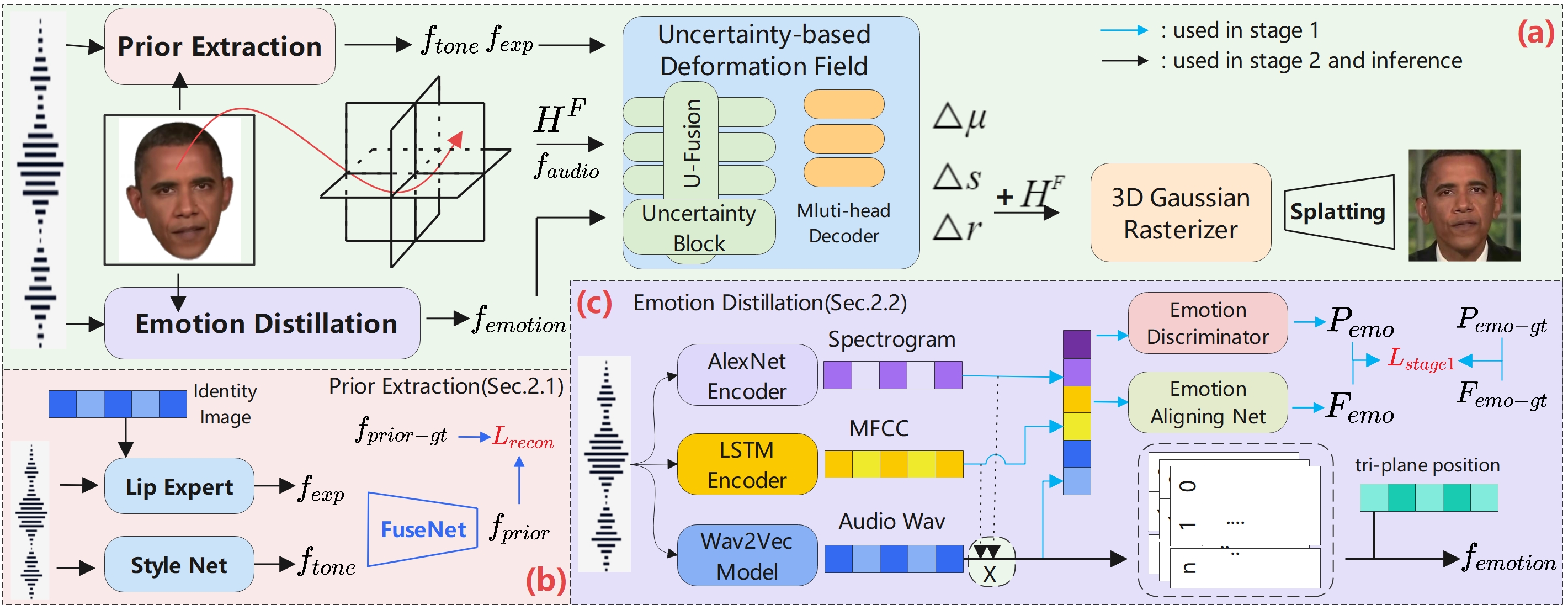
问题定义:现有的3D情感语音人脸合成方法难以实现高质量的情感表达和逼真的渲染效果。主要痛点在于音频情感提取不够精确,无法有效控制情感微表情,以及多视角融合策略不够灵活,忽略了不同视角的不确定性和特征质量差异,导致渲染质量下降。
核心思路:UA-3DTalk的核心思路是利用情感先验蒸馏来提升音频情感提取的精度,并通过不确定性感知机制来实现自适应的多视角融合。通过解耦音频特征,并引入多模态注意力机制和高斯编码,可以更精确地控制情感微表情。同时,通过估计视角特定的不确定性,可以实现更鲁棒的多视角融合,从而提升渲染质量。
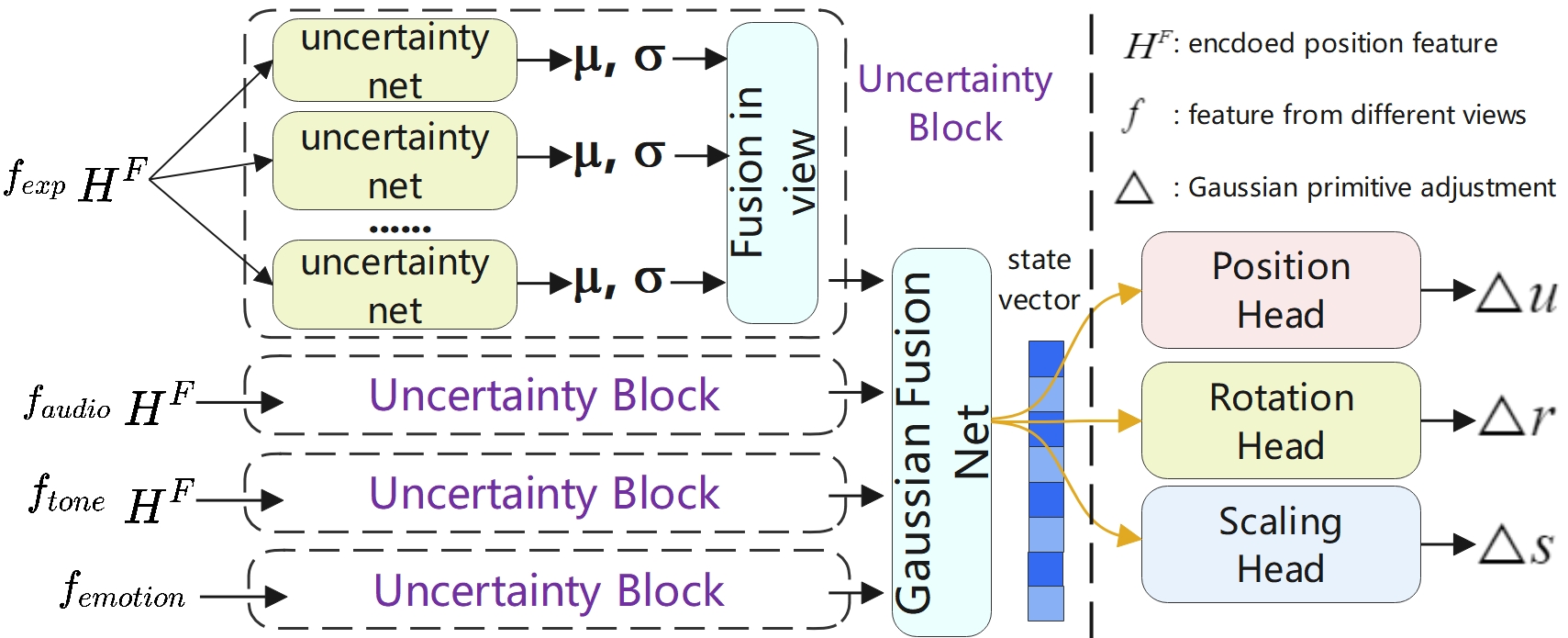
技术框架:UA-3DTalk包含三个主要模块:1) 先验提取模块:将音频解耦为内容同步特征和特定人互补特征。2) 情感蒸馏模块:利用多模态注意力加权融合和4D高斯编码,实现细粒度的情感提取和微表情控制。3) 不确定性形变模块:估计视角特定的偶然不确定性和认知不确定性,实现自适应多视角融合,并使用多头解码器进行高斯基元优化。
关键创新:UA-3DTalk的关键创新在于:1) 提出了情感先验蒸馏的方法,有效提升了音频情感提取的精度。2) 引入了不确定性感知机制,实现了自适应的多视角融合,提高了渲染质量。3) 结合了多模态注意力、高斯编码和多头解码器,实现了对情感微表情的精细控制。
关键设计:情感蒸馏模块使用了多模态注意力机制,根据不同模态的贡献程度进行加权融合。4D高斯编码使用多分辨率码本,以捕捉不同尺度下的情感信息。不确定性形变模块使用不确定性块来估计偶然不确定性和认知不确定性,并利用这些不确定性信息来调整多视角融合的权重。多头解码器用于优化高斯基元的参数,以生成更逼真的渲染结果。
🖼️ 关键图片

📊 实验亮点
UA-3DTalk在情感对齐(E-FID)上比DEGSTalk和EDTalk提高了5.2%,在唇部同步(SyncC)上提高了3.1%,在渲染质量(LPIPS)上提高了0.015。这些结果表明,UA-3DTalk在情感表达的准确性和渲染质量方面均优于现有方法,实现了显著的性能提升。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏、社交媒体等领域,实现更逼真、更具情感表现力的虚拟人物交互。例如,可以用于创建具有丰富情感表达的虚拟助手、游戏角色或社交媒体头像,提升用户体验和互动性。未来,该技术有望应用于远程医疗、教育等领域,实现更具人情味的远程交流。
📄 摘要(原文)
Emotional Talking Face synthesis is pivotal in multimedia and signal processing, yet existing 3D methods suffer from two critical challenges: poor audio-vision emotion alignment, manifested as difficult audio emotion extraction and inadequate control over emotional micro-expressions; and a one-size-fits-all multi-view fusion strategy that overlooks uncertainty and feature quality differences, undermining rendering quality. We propose UA-3DTalk, Uncertainty-Aware 3D Emotional Talking Face Synthesis with emotion prior distillation, which has three core modules: the Prior Extraction module disentangles audio into content-synchronized features for alignment and person-specific complementary features for individualization; the Emotion Distillation module introduces a multi-modal attention-weighted fusion mechanism and 4D Gaussian encoding with multi-resolution code-books, enabling fine-grained audio emotion extraction and precise control of emotional micro-expressions; the Uncertainty-based Deformation deploys uncertainty blocks to estimate view-specific aleatoric (input noise) and epistemic (model parameters) uncertainty, realizing adaptive multi-view fusion and incorporating a multi-head decoder for Gaussian primitive optimization to mitigate the limitations of uniform-weight fusion. Extensive experiments on regular and emotional datasets show UA-3DTalk outperforms state-of-the-art methods like DEGSTalk and EDTalk by 5.2% in E-FID for emotion alignment, 3.1% in SyncC for lip synchronization, and 0.015 in LPIPS for rendering quality. Project page: https://mrask999.github.io/UA-3DTalk