HalluJudge: A Reference-Free Hallucination Detection for Context Misalignment in Code Review Automation
作者: Kla Tantithamthavorn, Hong Yi Lin, Patanamon Thongtanunam, Wachiraphan Charoenwet, Minwoo Jeong, Ming Wu
分类: cs.SE, cs.AI
发布日期: 2026-01-27
备注: Under Review
💡 一句话要点
提出HalluJudge,用于检测代码评审自动化中上下文不一致导致的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码评审自动化 大型语言模型 幻觉检测 上下文对齐 软件工程
📋 核心要点
- 现有代码评审自动化中的大型语言模型易产生幻觉,生成与实际代码不符的评审意见,影响其应用。
- HalluJudge旨在通过评估生成评审意见的上下文对齐程度,从而检测LLM生成的代码评审意见中的幻觉。
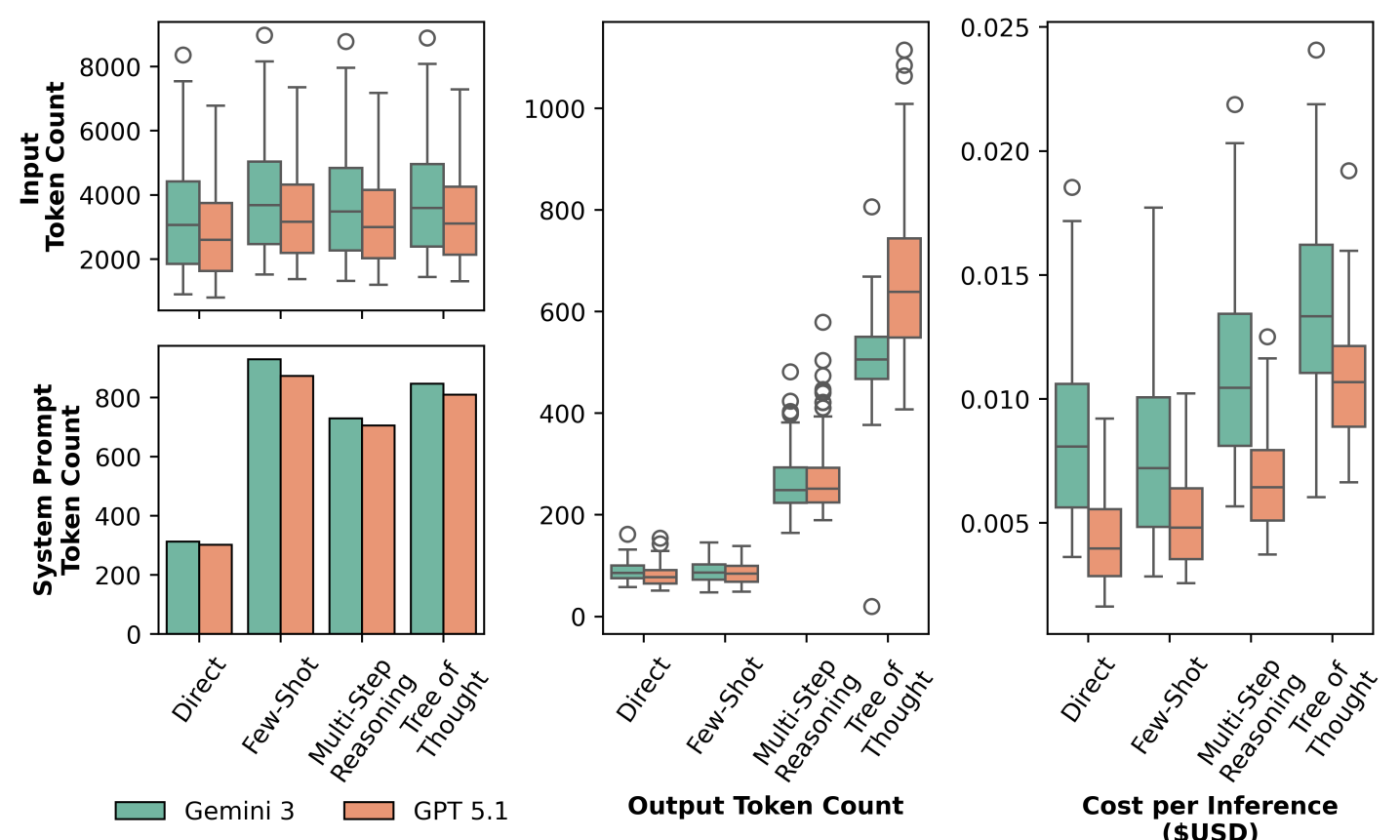
- 实验表明HalluJudge具有成本效益,F1得分为0.85,且与开发者偏好具有较高的一致性(67%)。
📝 摘要(中文)
大型语言模型(LLMs)在代码评审自动化方面表现出强大的能力,例如生成评审意见,但它们也存在幻觉问题——生成的评审意见与实际代码不符,这对LLMs在代码评审工作流程中的应用构成了重大挑战。为了解决这个问题,我们探索了在没有参考的情况下,对LLM生成的代码评审意见进行幻觉检测的有效且可扩展的方法。在这项工作中,我们设计了HalluJudge,旨在基于上下文对齐来评估生成的评审意见的可靠性。HalluJudge包括从直接评估到结构化多分支推理(例如,思维树)的四种关键策略。我们对Atlassian的企业级软件项目进行了全面的评估,以检验HalluJudge的有效性和成本效益。此外,我们分析了HalluJudge的判断与开发者对实际LLM生成的代码评审意见在实际生产中的偏好之间的一致性。我们的结果表明,HalluJudge中的幻觉评估具有成本效益,F1得分为0.85,平均成本为0.009美元。平均而言,67%的HalluJudge评估与开发者在在线生产中对LLM生成的评审意见的偏好相一致。我们的结果表明,HalluJudge可以作为一种实用的保障措施,以减少开发者接触到幻觉评论的机会,从而增强对AI辅助代码评审的信任。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在代码评审自动化中产生的幻觉问题,即生成的评审意见与实际代码不符。现有方法缺乏有效的、无需参考的幻觉检测机制,导致开发者难以信任AI辅助的代码评审。
核心思路:HalluJudge的核心思路是通过评估LLM生成的代码评审意见与代码上下文的对齐程度来判断是否存在幻觉。如果评审意见与代码上下文不一致,则认为存在幻觉。这种方法避免了对参考答案的依赖,提高了实用性。
技术框架:HalluJudge包含四个关键策略:直接评估、上下文一致性检查、多分支推理(如思维树)以及混合策略。直接评估直接判断评审意见是否合理。上下文一致性检查验证评审意见是否与代码上下文相符。多分支推理通过生成多个可能的解释来评估评审意见的合理性。混合策略结合了以上三种方法。
关键创新:HalluJudge的关键创新在于提出了一种无需参考的幻觉检测方法,该方法依赖于上下文对齐而非与标准答案的比较。此外,HalluJudge采用了多种评估策略,包括直接评估和更复杂的推理方法,提高了检测的准确性和鲁棒性。
关键设计:HalluJudge的具体实现细节未知,但可以推测其关键设计包括:用于提取代码上下文的模块、用于评估评审意见合理性的模块、以及用于执行多分支推理的模块。具体的参数设置、损失函数和网络结构等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
HalluJudge在Atlassian的企业级软件项目上进行了评估,结果表明其具有成本效益,F1得分为0.85,平均每次评估成本仅为0.009美元。此外,HalluJudge的评估结果与开发者在实际生产环境中对LLM生成评审意见的偏好具有较高的一致性(67%)。
🎯 应用场景
HalluJudge可应用于各种代码评审自动化工具和平台,以减少开发者接触到幻觉评论的风险,提高AI辅助代码评审的可靠性和可信度。该研究有助于推动LLM在软件工程领域的应用,并为其他自然语言生成任务中的幻觉检测提供借鉴。
📄 摘要(原文)
Large Language models (LLMs) have shown strong capabilities in code review automation, such as review comment generation, yet they suffer from hallucinations -- where the generated review comments are ungrounded in the actual code -- poses a significant challenge to the adoption of LLMs in code review workflows. To address this, we explore effective and scalable methods for a hallucination detection in LLM-generated code review comments without the reference. In this work, we design HalluJudge that aims to assess the grounding of generated review comments based on the context alignment. HalluJudge includes four key strategies ranging from direct assessment to structured multi-branch reasoning (e.g., Tree-of-Thoughts). We conduct a comprehensive evaluation of these assessment strategies across Atlassian's enterprise-scale software projects to examine the effectiveness and cost-efficiency of HalluJudge. Furthermore, we analyze the alignment between HalluJudge's judgment and developer preference of the actual LLM-generated code review comments in the real-world production. Our results show that the hallucination assessment in HalluJudge is cost-effective with an F1 score of 0.85 and an average cost of $0.009. On average, 67% of the HalluJudge assessments are aligned with the developer preference of the actual LLM-generated review comments in the online production. Our results suggest that HalluJudge can serve as a practical safeguard to reduce developers' exposure to hallucinated comments, fostering trust in AI-assisted code reviews.