TSRBench: A Comprehensive Multi-task Multi-modal Time Series Reasoning Benchmark for Generalist Models
作者: Fangxu Yu, Xingang Guo, Lingzhi Yuan, Haoqiang Kang, Hongyu Zhao, Lianhui Qin, Furong Huang, Bin Hu, Tianyi Zhou
分类: cs.AI, cs.LG
发布日期: 2026-01-26
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
TSRBench:一个综合性的多任务多模态时间序列推理基准,用于评估通用模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列推理 通用模型 多模态学习 基准测试 深度学习
📋 核心要点
- 现有通用模型基准测试中缺乏对时间序列推理能力的全面评估,限制了模型在实际应用中的潜力。
- TSRBench通过构建包含多领域、多任务的时间序列推理数据集,旨在全面评估和提升通用模型的时间序列处理能力。
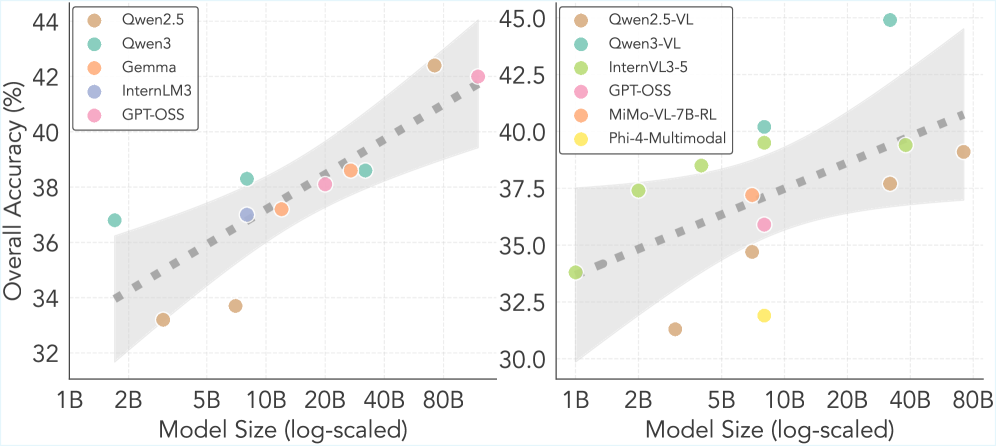
- 实验结果表明,现有模型在时间序列预测方面存在不足,且多模态融合未能有效提升性能,为未来研究提供了方向。
📝 摘要(中文)
本文提出了TSRBench,一个综合性的多模态基准,旨在全面测试通用模型的时间序列推理能力。TSRBench包含来自14个领域的4125个问题,并被划分为四个主要维度:感知、推理、预测和决策。它包含15个任务,涵盖了数值推理等关键推理能力。通过对30多个领先的专有和开源LLM、VLM和TSLLM的广泛评估,研究发现:感知和推理能力遵循缩放定律,但预测能力不遵循;强大的推理能力并不保证准确的上下文感知预测,表明语义理解和数值预测之间存在脱钩;尽管时间序列的文本和视觉表示具有互补性,但当前的多模态模型未能有效地融合它们以实现互惠的性能提升。TSRBench提供了一个标准化的评估平台,不仅突出了现有挑战,还为推进通用模型提供了有价值的见解。代码和数据集可在https://tsrbench.github.io/获取。
🔬 方法详解
问题定义:现有通用模型基准测试在时间序列推理方面存在明显不足,无法充分评估模型在处理实际场景中常见的时间序列数据时的能力。现有方法难以同时处理时间序列数据的感知、推理、预测和决策等多个维度,并且缺乏对多模态时间序列数据有效融合的能力。
核心思路:TSRBench的核心思路是构建一个综合性的、多任务的、多模态的时间序列推理基准,以全面评估通用模型在不同维度上的时间序列处理能力。通过提供多样化的数据集和任务,旨在激发模型在时间序列推理方面的潜力,并促进相关技术的发展。
技术框架:TSRBench包含以下主要组成部分:1) 多样化的数据集:包含来自14个领域的4125个问题,涵盖感知、推理、预测和决策四个维度。2) 多任务评估:包含15个任务,用于评估模型在不同推理能力上的表现,例如数值推理。3) 标准化评估平台:提供统一的评估指标和流程,方便研究人员进行模型比较和分析。4) 多模态支持:支持文本和视觉两种时间序列表示,用于评估模型的多模态融合能力。
关键创新:TSRBench的关键创新在于其综合性和多模态性。它不仅涵盖了时间序列推理的多个维度,还考虑了不同模态的时间序列数据。此外,TSRBench还提供了一个标准化的评估平台,方便研究人员进行模型比较和分析。与现有方法相比,TSRBench能够更全面地评估通用模型在时间序列推理方面的能力。
关键设计:TSRBench的数据集构建过程中,针对不同领域和任务,采用了不同的数据采集和处理方法。在多模态融合方面,研究人员探索了不同的融合策略,例如基于注意力机制的融合方法。评估指标方面,采用了多种常用的时间序列预测和分类指标,例如均方误差(MSE)和准确率(Accuracy)。具体参数设置和网络结构的选择取决于所评估的模型。
🖼️ 关键图片
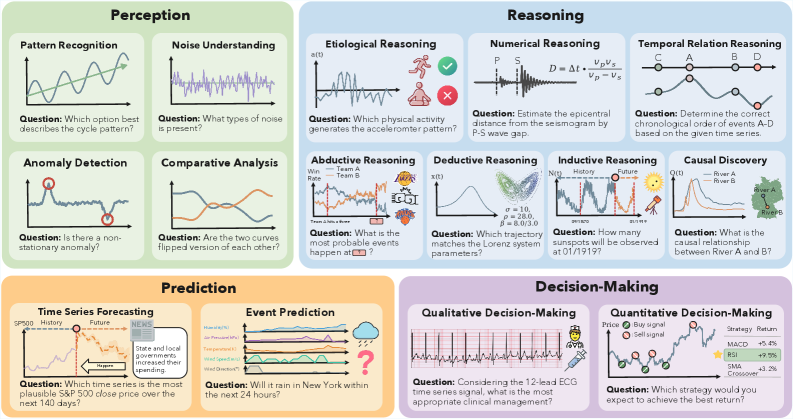
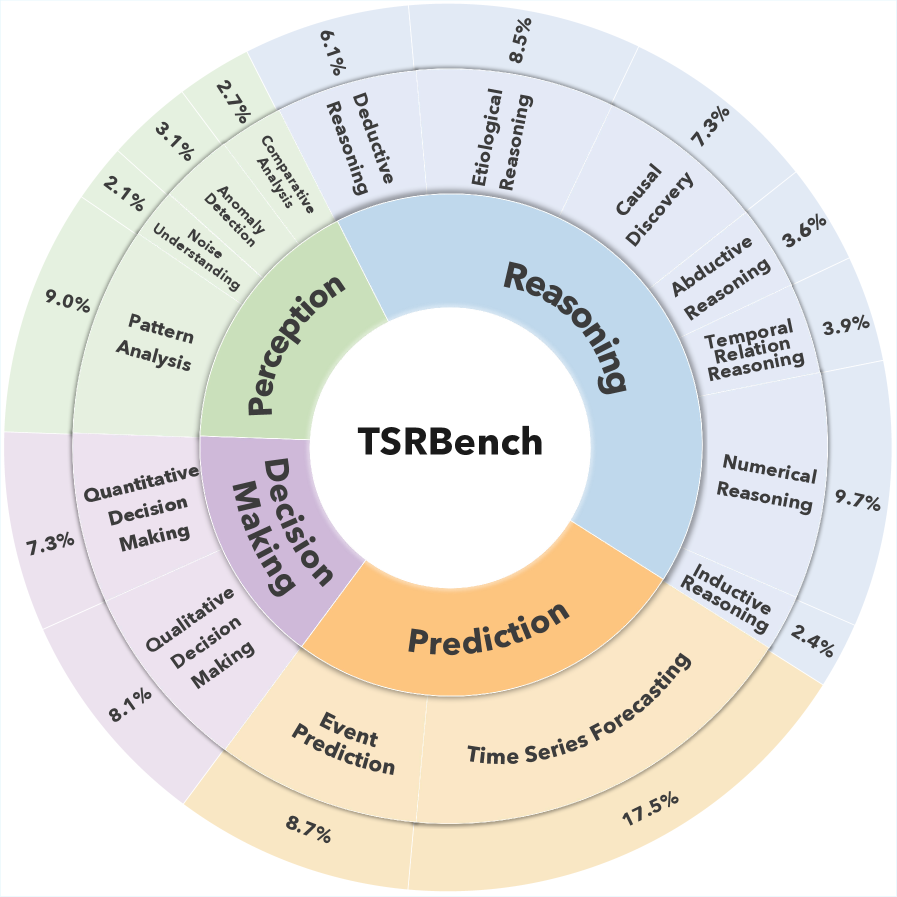
📊 实验亮点
实验结果表明,现有通用模型在TSRBench上的表现参差不齐。感知和推理能力遵循缩放定律,但预测能力不遵循。强大的推理能力并不保证准确的上下文感知预测,表明语义理解和数值预测之间存在脱钩。多模态模型未能有效融合文本和视觉信息以实现互惠的性能提升。例如,在某些预测任务上,最佳模型的准确率仅为60%,表明仍有很大的提升空间。
🎯 应用场景
TSRBench的研究成果可广泛应用于能源管理、交通控制、金融预测、医疗诊断等领域。通过提升通用模型的时间序列推理能力,可以提高这些领域中预测和决策的准确性和效率,从而带来显著的经济和社会效益。未来,TSRBench可以作为评估和改进时间序列模型的标准平台,推动相关技术的发展。
📄 摘要(原文)
Time series data is ubiquitous in real-world scenarios and crucial for critical applications ranging from energy management to traffic control. Consequently, the ability to reason over time series is a fundamental skill for generalist models to solve practical problems. However, this dimension is notably absent from existing benchmarks of generalist models. To bridge this gap, we introduce TSRBench, a comprehensive multi-modal benchmark designed to stress-test the full spectrum of time series reasoning capabilities. TSRBench features: i) a diverse set of 4125 problems from 14 domains, and is categorized into 4 major dimensions: Perception, Reasoning, Prediction, and Decision-Making. ii) 15 tasks from the 4 dimensions evaluating essential reasoning capabilities (e.g., numerical reasoning). Through extensive experiments, we evaluated over 30 leading proprietary and open-source LLMs, VLMs, and TSLLMs within TSRBench. Our findings reveal that: i) scaling laws hold for perception and reasoning but break down for prediction; ii) strong reasoning does not guarantee accurate context-aware forecasting, indicating a decoupling between semantic understanding and numerical prediction; and iii) despite the complementary nature of textual and visual represenations of time series as inputs, current multimodal models fail to effectively fuse them for reciprocal performance gains. TSRBench provides a standardized evaluation platform that not only highlights existing challenges but also offers valuable insights to advance generalist models. Our code and dataset are available at https://tsrbench.github.io/.