Stability as a Liability:Systematic Breakdown of Linguistic Structure in LLMs
作者: Xianzhe Meng, Qiangsheng Zeng, Ling Luo, Qinghan Yang, Jiarui Hao, Wenbo Wu, Qinyu Wang, Rui Yin, Lin Qi, Renzhi Lu
分类: cs.AI, cs.CL, cs.LG
发布日期: 2026-01-26
💡 一句话要点
揭示LLM训练稳定性与生成质量的矛盾:稳定训练导致语言结构退化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 训练稳定性 生成质量 KL散度 生成熵 反馈训练 模型退化
📋 核心要点
- 大型语言模型通常将训练稳定性视为可靠优化的前提,但其对生成分布的影响尚不明确。
- 该研究表明,稳定训练可能导致模型生成熵降低,概率集中于有限模式,从而引起系统性退化。
- 通过实验验证,稳定的训练动态会导致低熵输出和重复行为,表明稳定性和生成质量并非完全一致。
📝 摘要(中文)
本文研究了大型语言模型中训练稳定性对生成分布的影响。研究表明,在标准的最大似然训练下,稳定的参数轨迹导致模型收敛到近似最小化前向KL散度的平稳解,并隐式地降低生成熵。因此,学习到的模型可能将概率质量集中在经验模式的有限子集上,即使损失平滑收敛,也会表现出系统性的退化。通过一个可控的基于反馈的训练框架来稳定内部生成统计,实证验证了这种效应,观察到跨架构和随机种子的持续低熵输出和重复行为。这表明优化稳定性和生成表达性并非天然一致,并且仅凭稳定性不足以作为生成质量的指标。
🔬 方法详解
问题定义:论文旨在解决大型语言模型训练过程中,过度追求稳定性可能导致生成质量下降的问题。现有方法通常认为训练稳定是模型性能提升的必要条件,但忽略了稳定性可能对生成分布产生负面影响,导致模型生成内容单一、重复,缺乏多样性和创造性。
核心思路:论文的核心思路是揭示训练稳定性与生成表达性之间的矛盾关系。作者认为,在最大似然估计下,稳定的训练过程会使模型倾向于最小化前向KL散度,从而降低生成熵,导致模型过度拟合训练数据的有限模式。因此,过度追求训练稳定性反而会损害模型的泛化能力和生成质量。
技术框架:论文采用了一个可控的基于反馈的训练框架来稳定内部生成统计。该框架通过对模型的生成结果进行反馈,从而控制模型的训练动态,使其更加稳定。具体来说,该框架包含以下几个主要模块:1)语言模型:待训练的大型语言模型;2)反馈机制:用于评估模型生成结果的质量,并生成反馈信号;3)训练策略:根据反馈信号调整模型的训练过程,以提高训练稳定性。
关键创新:论文最重要的技术创新点在于揭示了训练稳定性与生成表达性之间的矛盾关系,并提出了一个可控的基于反馈的训练框架来验证这一观点。与现有方法不同,该论文不再盲目追求训练稳定性,而是更加关注训练过程对生成分布的影响,从而更好地平衡稳定性和生成质量。
关键设计:论文的关键设计包括:1)反馈机制的设计:如何有效地评估模型生成结果的质量,并生成合适的反馈信号;2)训练策略的设计:如何根据反馈信号调整模型的训练过程,以提高训练稳定性,同时避免过度降低生成熵;3)实验设置:如何设计实验来验证训练稳定性与生成表达性之间的矛盾关系。
🖼️ 关键图片
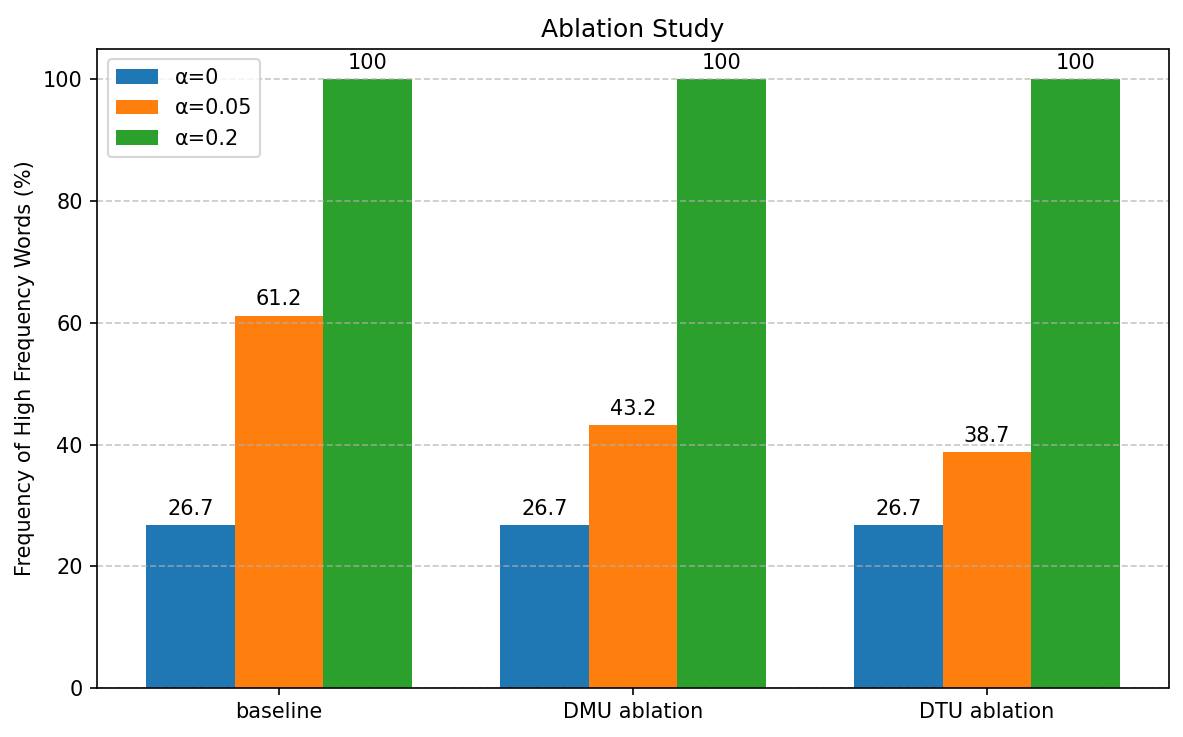
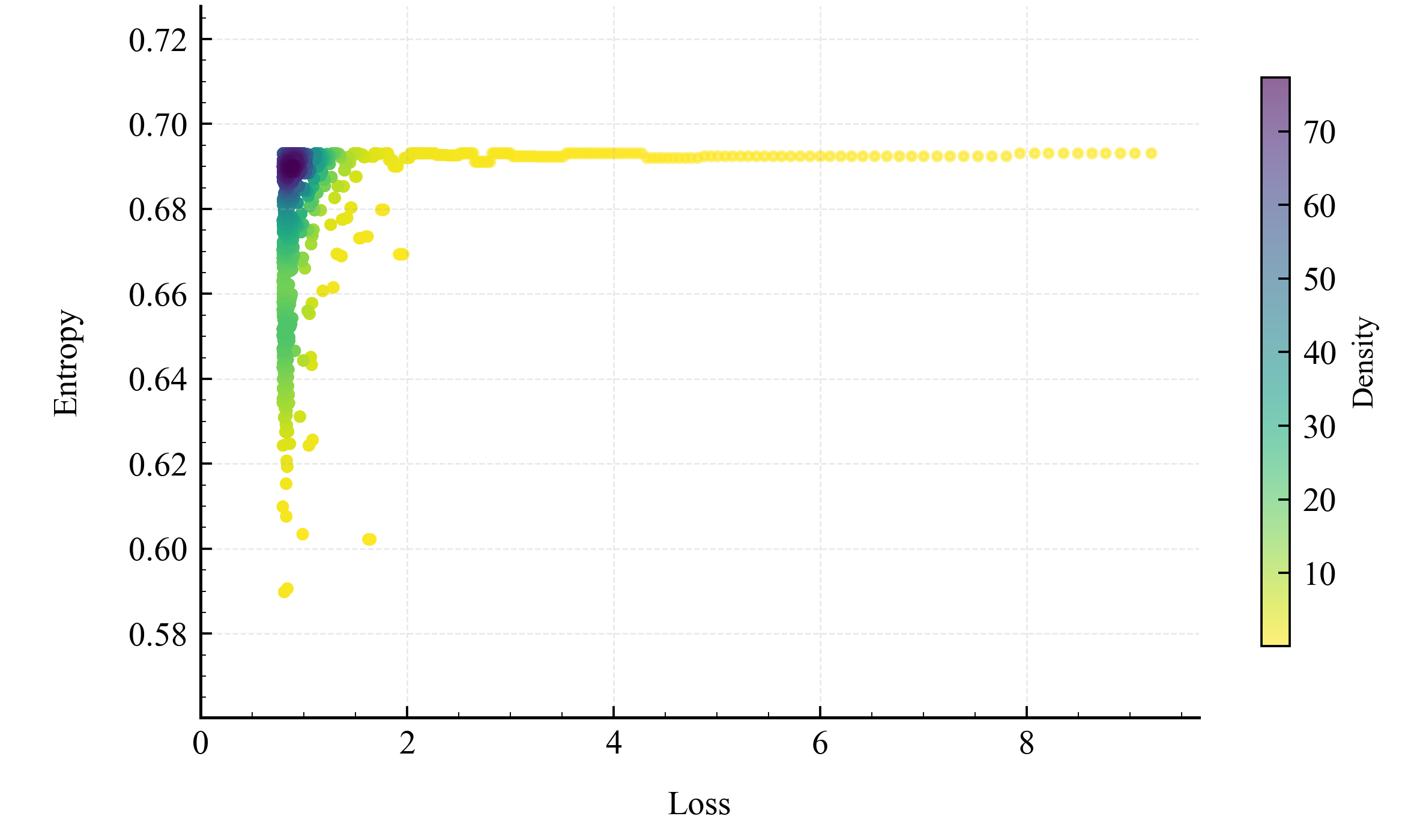
📊 实验亮点
论文通过实验验证了稳定训练会导致低熵输出和重复行为。使用可控的反馈训练框架,在不同架构和随机种子下观察到一致的结果,表明优化稳定性和生成表达性并非天然一致。这些实验结果有力地支持了论文的核心观点,即稳定性本身不足以作为生成质量的指标。
🎯 应用场景
该研究成果可应用于改进大型语言模型的训练方法,避免过度追求稳定性而牺牲生成质量。通过平衡训练稳定性和生成表达性,可以提升模型生成文本的多样性、创造性和泛化能力,从而在对话系统、文本生成、机器翻译等领域获得更好的应用效果。未来的研究可以探索更有效的训练策略,以实现稳定性和生成质量的最佳平衡。
📄 摘要(原文)
Training stability is typically regarded as a prerequisite for reliable optimization in large language models. In this work, we analyze how stabilizing training dynamics affects the induced generation distribution. We show that under standard maximum likelihood training, stable parameter trajectories lead stationary solutions to approximately minimize the forward KL divergence to the empirical distribution, while implicitly reducing generative entropy. As a consequence, the learned model can concentrate probability mass on a limited subset of empirical modes, exhibiting systematic degeneration despite smooth loss convergence. We empirically validate this effect using a controlled feedback-based training framework that stabilizes internal generation statistics, observing consistent low-entropy outputs and repetitive behavior across architectures and random seeds. It indicates that optimization stability and generative expressivity are not inherently aligned, and that stability alone is an insufficient indicator of generative quality.